等距抽樣
出自 MBA智库百科(https://wiki.mbalib.com/)
等距抽樣也稱為:機械抽樣\系統抽樣( Systematic sampling )、SYS抽樣、間隔抽樣法(Interval sampling)
目錄 |
等距抽樣也稱為系統抽樣、或機械抽樣、SYS抽樣,它是首先將總體中各單位按一定順序排列,根據樣本容量要求確定抽選間隔,然後隨機確定起點,每隔一定的間隔抽取一個單位的一種抽樣方式。是純隨機抽樣的變種。在系統抽樣中,先將總體從1~N相繼編號,並計算抽樣距離K=N/n。式中N為總體單位總數,n為樣本容量。然後在1~K中抽一隨機數k1,作為樣本的第一個單位,接著取k1+K,k1+2K……,直至抽夠n個單位為止。
等距抽樣要防止周期性偏差,因為它會降低樣本的代表性。例如,軍隊人員名單通常按班排列,10人一班,班長排第1名,若抽樣距離也取10時,則樣本或全由士兵組成或全由班長組成。
根據總體單位排列方法,等距抽樣的單位排列可分為三類:按有關標誌排隊、按無關標誌排隊以及介於按有關標誌排隊和按無關標誌排隊之間的按自然狀態排列。
按照具體實施等距抽樣的作法,等距抽樣可分為:直線等距抽樣、對稱等距抽樣和迴圈等距抽樣三種。
| 市場調查方法 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| [編輯] | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
等距抽樣的最主要優點是簡便易行,且當對總體結構有一定瞭解時,充分利用已有信息對總體單位進行排隊後再抽樣,則可提高抽樣效率。
等距抽樣的特點是:抽出的單位在總體中是均勻分佈的,且抽取的樣本可少於純隨機抽樣。
等距抽樣既可以用同調查項目相關的標誌排隊,也可以用同調查項目無關的標誌排隊。
採用等距抽樣時,必須首先對總體單位按某種標誌進行排序,有下列兩種排序方法。
(1)按無關標誌排序。
即總體單位排列的順序和所要研究的標誌是無關的。如調查職工的收入水平,可按姓氏筆劃排列的職工名單進行抽樣;工業生產質量檢驗可按產品生產的時間順序進行等距抽樣等等。一般認為,按無關標誌排隊的等距抽樣是一種抽簽法,隨機數表法更好的純隨機抽樣方式,又稱無序系統抽樣。
(2)按有關標誌排序。
即總體單位排列的順序與所要研究的標誌是有直接關係的。例如,農產量抽樣調查時,可按照當年估產或前幾年的平均實產由低到高或由高到低的順序進行抽樣。這種按有關標誌排隊的等距抽樣又稱有序系統抽樣,它能使標誌值高低不同的單位,均有可能選入樣本,從而提高樣本的代表性,減小抽樣誤差。一般認為有序系統抽樣比等比例分層抽樣能使樣本更均勻地分佈在總體中,抽樣誤差也更小。
當總體單位的順序排列之後,可選用下列方法進行等距抽樣。
(1)隨機起點等距抽樣。
即在總體分成K段(K=N/n)的前提下,首先從第一段的1至k號總體單位中隨機抽選一個樣本單位,然後每隔k個單位抽取一個樣本單位,直到抽足n個單位為止。這n個單位就構成了一個隨機起點的等距樣本。這種方法能夠保證各個總體單位具有相同的概率被抽到,但是,如果隨機起點單位處於每一段的低端或高端,就會導致往後的單位都會處於相應段的低端或高端,從而使抽樣出現偏低或偏高的系統誤差。
(2)半距起點等距隨機抽樣。
這種方法又稱為中點法抽取樣本,它是在總體的第一段,取1,2,…,k號中的中間項為起點,然後再每隔k個單位抽取一個樣本單位,直到抽足n個樣本單位為止。當總體是按有關標誌的大小順序排列時,採用中點法抽取樣本,可提高整個樣本對總體的代表性。
(3)隨機起點對稱等距抽樣。
這種方法是在總體第一段隨機抽到第i個單位,而在第二段抽取第2k-f+1的單位,在第三段抽取第2k+f的單位,而在第四段抽取第4k-f+1的單位…,以此交替對稱進行。可概括為:在總體奇數段抽取第jk+i單位(j=0,2,4…);在總體偶數段抽取第jk-i+1單位(j=2,4…)。這種抽樣方法能使處於低端的樣本單位與另一段處於高端的樣本單位相互搭配,從而抵消或避免抽樣中的系統誤差。
(4)迴圈等距抽樣。
當N為有限總體而且不能被n所整除,亦即k不是一個整數時,可將總體各單位按順序排成首尾相接的迴圈圓形,用N/n確定抽樣間隔k,k可以取最接近的整數,然後在第一段的1至後號中抽取一個作為隨機起點,再每隔後個單位抽取一個樣本單位,直至抽滿行個為止。
等距抽樣在抽樣調查中的應用
在定量抽樣調查中,等距抽樣常常代替簡單隨機抽樣。由於該抽樣方法簡單實用,所以應用普遍。等距抽樣得到的樣本幾乎與簡單隨機抽樣得到的樣本是相同的。
等距抽樣的基本做法是,將總體中的各單元先按一定的順序排列、編號,然後決定一個間隔,併在此間隔基礎上選擇被調查的單位個體。
樣本距離可通過下麵公式確定:樣本距離 = 總體單位數∕樣本單位數
例如,假設你使用本地電話本並確定樣本距離為100 ,那麼100個中取1個組成樣本。這個公式保證了整個列表的完整性。
等距抽樣方式隨意用一個起點,例如,如果你把一本電話本作為抽樣框,必須隨意取出一個號碼決定從該頁開始翻閱。假設從第5頁開始,在該頁上再另選一個數決定從該行開始。假定選擇從第3行開始,這就決定了實際開始的位置。
等距抽樣方式相對於簡單隨機抽樣方式最主要的優勢就是經濟性。等距抽樣方式比簡單隨機抽樣更為簡單,花的時間更少,並且花費也少。使用等距抽樣方式最大的缺陷在於總體單位的排列上。一些總體單位數可能包含隱蔽的形態或者是“不合格樣本”,調查者可能疏忽,把它們抽選為樣本。
等距抽樣又稱為機械抽樣或系統抽樣,它是將總體各單位按某標誌進行排序,然後按固定的間隔來抽取樣本單位的抽樣組織形式。根據需要抽取的樣本單位數n和總體的單位數N,可以計算出等距抽樣的間隔大小為
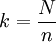
先從排序後序號為1,2,…,k的第一部分中隨機抽出第i個單位,然後在序號為k+1,k+2,…,2k的第二部分中抽取第k+i個單位,再從序號為2k+1,2k+2,...,3k的第三部分中抽取第2k+i個單位,依此類推,最後從序號為(n-1)k+1,(n-1)k+2,...,nk的第n部分中抽取第(n-1)k+i個單位,一共n個單位構成樣本。
總體排序標誌由總體的有關輔助信息確定,與調查標誌兩者間可以有關也可以無關。如家計調查,按門牌號碼排序就是無關標誌排序,但是,如果選擇的排序標誌與實際調查標誌間存在密切聯繫,要比無關標誌排序的等距抽樣更為優越。如農產量調查按平均畝產量高低排序,職工家計調查按平均工資多少進行排序,都可縮小各單位間的差異程度,有利於提高樣本的代表性。
等距抽樣的間隔應避免與現象本身的節奏性或迴圈周期相重合。例如,進行農作物調查時,抽樣間隔就應避免與農作物壠長或間距相重合;進行工業產品質量調查時,產品抽樣時間間隔不宜和上下班時間相一致,否則,就會因引起系統偏差而影響樣本的代表性。
用等距抽樣方式抽取一個樣本後,就可以計算樣本平均數。關鍵是這個平均數的平均誤差如何確定,一般說來,排序後總體被分成n個部分,每一部分包含k個單位,從中隨機抽取一個單位,其餘單位情況未知,每一部分中的方差不可計算,一般也沒有歷史資料可以替代它們。因此,直接計算等距抽樣的平均誤差是有困難的,只能以間接方式計算其近似值,如果據以排序的標誌與所要研究的目的沒有關係,且第一個單位是隨機抽取的,則等距抽樣的平均誤差就與隨機抽樣的平均誤差相接近。為了方便起見,可以採用簡單隨機抽樣的平均誤差代替等距抽樣平均誤差
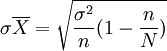
等距抽樣一般都是無回置抽樣,總體方差σ2未知時,常用樣本方差代替。
【例】某塊麥地長300米,寬120米,包括120條壠,每壠長300米,現從這塊麥地按等距抽樣的方式,抽取50個2米長壠為樣本進行實割實測。
樣本距離為麥壠總長除以樣本單位數,即300×120/50=720(米):現從地角一邊樣本距離一半處抽取第一個樣本單位,即從360米前後1米為第一個樣本單位,以後每隔720米取一個樣本單位,一直抽出50個樣本單位為止。實測各樣本單位產量如表所示:
| 樣本產量X(公斤) | 單位數n | nX | 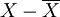 | 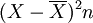
|
|---|---|---|---|---|
| 0.8 | 6 | 4.8 | -0.4 | 0.96 |
| 1 | 12 | 12 | -0.2 | 0.48 |
| 1.2 | 14 | 16.8 | 0 | 0 |
| 1.4 | 12 | 16.8 | 0.2 | 0.48 |
| 1.6 | 6 | 9.6 | 0.4 | 0.96 |
| 合計 | 50 | 60 | — | 2.88 |
試計算平均畝產量的抽樣平均誤差,並以95%的概率保證估計這塊麥地的畝產量和總產量:
解:樣本平均產量 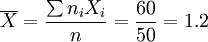 (公斤)
(公斤)
樣本單位標準差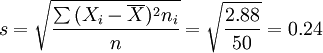 (公斤)
(公斤)
樣本單位的抽樣平均誤差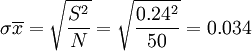 (公斤)
(公斤)
這塊麥地的面積是: (平方米),摺合為
(平方米),摺合為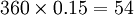 (畝)。
(畝)。
由於樣本單位壠長是2米,所以每畝含樣本單位數是:
1/2×總壠長÷面積=1/2×36000/54≈333(個)。
平均畝產量=樣本平均產量×每畝含樣本單位數,即平均畝產量
1.2×18000/54=400(公斤)
平均畝產量的抽樣平均誤差=每畝含樣本單位數×樣本單位數的抽樣平均誤差,即為
18000/54×0.034=11.33(公斤)
由於概率保證是95%,即α = 0.05,則有Zα / 2 = 1.96。那麼,畝產量的置信區間是
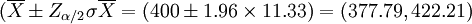
即畝產量估計在377.79公斤到422.21公斤之間。
總產量的置信區間是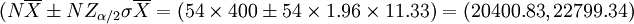
即以95%的概率保證,這塊麥地的總產量估計在20401公斤到22799公斤之間。
某企業有職工5000名,現要隨機抽取100人進行家庭收入水平調查。
抽取方法:按與研究目的無直接關係的姓名筆劃對總體進行排列,把總體劃分為K=5000/100=50個相等的間隔,在第1至第50人中隨機抽取一名,如抽到第10名,後面間隔依次抽取第60,110,160,210,…直到4960為止,總共抽取50同名職工組成一個抽樣總體。







太籠統!!!!1