KMV模型
出自 MBA智库百科(https://wiki.mbalib.com/)
目錄 |
KMV模型是美國舊金山市KMV公司於1997年建立的用來估計借款企業違約概率的方法。該模型認為,貸款的信用風險是在給定負債的情況下由債務人的資產市場價值決定的。但資產並沒有真實地在市場交易,資產的市場價值不能直接觀測到。為此,模型將銀行的貸款問題倒轉一個角度,從借款企業所有者的角度考慮貸款歸還的問題。在債務到期日,如果公司資產的市場價值高於公司債務值(違約點),則公司股權價值為公司資產市場價值與債務值之間的差額;如果此時公司資產價值低於公司債務值,則公司變賣所有資產用以償還債務,股權價值變為零。
首先,它利用Black-Scholes期權定價公式,根據企業股權的市場價值、股權價值的波動性、到期時間、無風險借貸利率及負債的賬麵價值估計出企業資產的市場價值及其波動性。
其次根據公司的負債計算出公司的違約實施點 (default exercise point,為企業1年以下短期債務的價值加上未清償長期債務賬麵價值的一半),計算借款人的違約距離。
最後,根據企業的違約距離與預期違約率(EDF) 之間的對應關係,求出企業的預期違約率。
KMV模型的優勢在於以現代期權理論基礎作依托,充分利用資本市場的信息而非歷史賬面資料進行預測,將市場信息納入了違約概率,更能反映上市企業當前的信用狀況,是對傳統方法的一次革命。KMV模型是一種動態模型,採用的主要是股票市場的數據,因此,數據和結果更新很快,具有前瞻性,是一種“向前看”的方法。在給定公司的現時資產結構的情況下,一旦確定出資產價值的隨機過程,便可得到任一時間單位的實際違約概率。其劣勢在於假設比較苛刻,尤其是資產收益分佈實際上存在“肥尾”現象,並不滿足正態分佈假設;僅抓住了違約預測,忽視了企業信用品質的變化;沒有考慮信息不對稱情況下的道德風險;必須使用估計技術來獲得資產價值、企業資產收益率的期望值和波動性;對非上市公司因使用資料的可獲得性差,預測的準確性也較差;不能處理非線性產品,如期權、外幣掉期等。
KMV模型自1993年推出以來,國外學術界對KMV模型的研究經歷了兩個階段:
第一階段是將KMV模型的預測結果與實際的違約數據相比較,大多數研究結果表明,KMV模型能夠反映信用風險的高低,並對信用風險具有很高的敏感性。
第二階段,國外學術界對模型的驗證尋找到新的角度,並開發出多種驗證模型有效性的方法和技術。
我國學者主要對模型在我國適應性和參數調整方面進行了許多探討,取得了一定的成果。張林、張佳林(2000)、王瓊、陳金賢(2002) 先後對KMV模型與其他模型進行理論上比較,認為更適合於評價上市公司的信用風險。薛鋒,魯煒,趙恆街,劉冀雲(2003)利用中國股市的數據,得出了應中市場的σv和σE的關係函數,並以一隻股票為樣本進行了實證分析。喬卓等(2003)介紹了KMV模型的基本內容,以及國外的應用經驗,但是並沒有進行實證研究。易丹輝,吳建民(2004年)對深市和滬市隨機抽取30家公司分行業計算違約距離和違約率並作比較,認為藉助違約距離衡量上市公司的信用風險是可行的。
由於缺少大量違約公司樣本的歷史資料庫,因此,我國目前無法通過比較違約距離和破產頻率的歷史,擬合出代表公司違約距離的預期違約率函數。本文嘗試使用上市公司在某國有商業銀行貸款不良率替代其違約率,並根據我國資本市場的特點,選取KMV模型的相關參數,同時採用某國有商業銀行 2001年12月31日的235家貸款客戶的不良率來替代上市公司的違約率進行實證分析,建立違約距離與不良率的函數關係。
KMV是運用現代期權定價理論建立起來的違約預測模型,是對傳統信用風險度量方法的一次重要革命。首先,KMV可以充分利用資本市場上的信息,對所有公開上市企業進行信用風險的量化和分析;其次,由於該模型所獲取的數據來自股票市場的資料,而非企業的歷史數據,因而更能反映企業當前的信用狀況,具有前瞻性,其預測能力更強、更及時,也更準確;另外,KMV模型建立在當代公司理財理論和期權理論的基礎之上,具有很強的理論基礎做依托。
但是,KMV模型與其他已有的模型一樣,仍然存在許多缺陷。首先,模型的使用範圍有一定的局限性。通常,該模型特別適用於上市公司的信用風險評估,而對非上市公司進行應用時,往往要藉助一些會計信息或其他能夠反映借款企業特征值的指標來替代模型中一些重要變數,同時還要通過對比分析最終得出該企業的期望違約概率,在一定程度上就有可能降低計算的準確性。其次,該模型假設公司的資產價值服從正態分佈,而實際中企業的資產價值一般會呈現非正態的統計特征。再次,模型不能夠對債務的不同類型進行區分,如償還優先順序、擔保、契約等類型,使得模型的輸出變數的計算結果不准確。北達公司根據中國過渡經濟的資本市場的特點,開發具有中國特色的上市公司信用KMV模型目前在進行壓力測試階段.
KMV模型與creditmetrics模型是目前國際金融界最流行的兩個信用風險管理模型。兩者都為銀行和其它金融機構在進行貸款等授信業務時衡量授信對象的信用狀況,分析所面臨的信用風險,防止集中授信,進而為實現投資分散化和具體的授信決策提供量化的、更加科學的依據,為以主觀性和藝術性為特征的傳統信用分析方法提供了很好的補償。然而,從上述的介紹和分析中,我們又可以明顯地看到這兩個模型在建模的基本思路上又相當大的差異,這些差異還主要表現在以下幾個方面。
1、KMV模型對企業信用風險的衡量指標edf主要來自於對該企業股票市場價格變化的有關數據的分析,而creditmetrics模型對企業信用風險的衡量來自於對該企業信用評級變化及其概率的歷史數據的分析。這是兩者最根本的區別之一。
2、由於KMV模型採用的是企業股票市場價格分析方法,這使得該模型可以隨時根據該企業股票市場價格的變化來更新模型的輸入數據,得出及時反映市場預期和企業信用狀況變化的新的edf值。因此,kmv模型被認為是一種動態模型,可以及時反映信用風險水平的變化。然而,creditmetrics採用的是企業信用評級指標分析法。企業信用評級,無論是內部評級還是外部評級,都不可能象股票市場價格一樣是動態變化的,而是在相當長的一段時間內保持靜態特征。這有可能使得該模型的分析結果不能及時反映企業信用狀況的變化。
3 、同時,也正是因為kmv模型所提供的edf指標來自於對股票市場價格實時行情的分析,而股票市場的實時行情不僅反映了該企業歷史的和當前的發展狀況,更重要的是反映了市場中的投資者對於該企業未來發展的綜合預期,所以,該模型被認為是一種向前看(forward-looking)的方法,edf指標中包含了市場投資者對該企業信用狀況未來發展趨勢的判斷。這與creditmetrics模型採用的主要依賴信用狀況變化的歷史數據的向後看(backward-looking)的方法有根本性的差別。kmv的這種向前看的分析方法在一定程度上剋服了依賴歷史數據向後看的數理統計模型的“歷來可以在未來複制其自身”的缺陷。
4 、KMV模型所提供的edf指標在本質上是一種對風險的基數衡量法,而creditmetrics所採用的與信用評級分析法則是一種序數衡量法,兩者完全不同。以基數法來衡量風險最大的特點在於不僅可以反映不同企業風險水平的高低順序,而且可以反映風險水平差異的程度,因而更加準確。這也更加有利於對貸款的定價。而序數衡量法只能反映企業間信用風險的高低順序,如bbb級高於bb級,卻不能明確說明高到什麼程度。
5、creditmetrics採用的是組合投資的分析方法,註重直接分析企業間信用狀況變化的相關關係,因而更加與現代組合投資管理理論相吻合。而kmv則是從單個授信企業在股票市場上的價格變化信息入手,著重分析該企業體現在股價變化信息中的自身信用狀況,對企業信用變化的相關性沒有給予足夠的分析。
案例一:KMV模型在上市公司信用風險評價中的分析[1]
一、KMV模型
KMV模型的基本思路是:當企業資產市場價值V低於企業所需清償的負債面值D時,企業將發生違約;以違約距離DD表示企業資產市場價值期望值V距離違約點DP,的遠近,距離越大,企業發生違約的可能性越小,反之較大;基於企業違約資料庫得出某一違約距離企業實際的期望違約頻率EDF;即未來違約概率。計算某一企業的期望違約頻率主要有三步:估計企業資產市場價值V和波動率\sigma_V;計算違約距離DD;計算期望違約頻率EDF。由於不能直接觀測到V和\sigma_V,因此需要從它們與股權市場價值E、股權市場價值波動率\sigma_E以及企業負債面值D之間的關係中推導得出。
KMV模型將企業負債看作是買入一份歐式看漲期權,即企業所有者持有一份以公司債務面值為執行價格,以公司資產市場價值為標的的歐式看漲期權/如果負債到期時企業資產市場價值高於其債務,企業償還債務;當企業資產市場價值小於其債務時,企業選擇違約/由於企業股權市場價值可以用Black-Scholes-Merton期權定價模型來定價,因此,KMV模型中的兩個未知變數V和σV可從以下聯立方程組中求解:
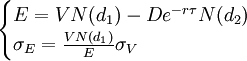 (1)
(1)
其中
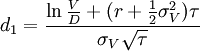
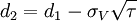
式中:E為企業股權市場價值,V為企業資產市場價值,D為企業債務面值,r為無風險收益率,τ為債務償還期限,N(d)為標準累積正態分佈函數,σV為企業資產價值波動率,σE為企業股權市場價值波動率。假設企業資產未來市場價值圍繞企業資產市場價值的均值呈正態分佈,那麼,我們可以用式(2)計算負債企業的違約距離DD(Distance to Default):
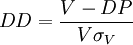 (2)
(2)
式中:DP(Default Point)為違約點值,處於公司的流動負債與總負債之間的某一點/違約距離DD以資產市場價值標準差的倍數表示,評估企業在τ時間後信用風險的大小。根據違約距離DD的定義,公司資產市場價值低於違約點的概率,即理論上發生違約的概率為1-N(DD)。而基於違約資料庫,依據違約距離可以映射出公司實際的期望違約頻率EDF。由於我國當前還沒有公開的違約資料庫可以使用,以違約距離DD作為上市公司信用評價的依據。
二、研究方法及參數設計
針對中國上市公司股權結構和所處市場環境的特殊性,考慮中國上市公司股權割裂導致的流通股和非流通股之間的價格差異,以及在中國上市公司所處特殊市場環境下,違約點設定對模型預測能力的影響。首先調整模型中股權市場價值計算方法;根據已經確定的各項參數,由式(1)求解出未知的兩項V和σV再由式(2)計算出三種違約點值情況下樣本公司的違約距離DD;然後對配對樣本的違約距離作t檢驗和Wilcoxon秩檢驗,檢驗KMV模型對上市公司整體信用風險的識別能力;最後使用ROC曲線圖評價模型對上市公司個體信用風險的識別能力。
1.上市公司股權市場價值波動率的估計
採用歷史波動率法估計上市公司股權市場價值未來一年的波動率。假設上市公司股票價格滿足對數正態分佈,則股票周收益率ui為。
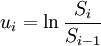 (3)
(3)
式中:Si,Si − 1為股票復權後的周收盤價。計算出公司股權市場價值的年波動率σE。
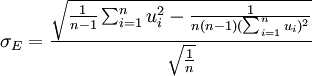 (4)
(4)
式中:E為一年內的交易周數,通過式(3)、式(4)可以估算每一公司股權市場價值的年波動率。
2.上市公司股權市場價值計算方法
中國證券市場發展歷史較為特殊,上市公司股票被人為分割為上市流通股票和暫不上市流通股票兩種。在計算上市公司股權市場價值時需要考慮以什麼樣的價格來計算非流通股市場價值/由於非流通股沒有市場交易價格,因此如何給非流通股定價是一件困難的事情。參考上市公司股票全流通研究中非流通股定價,以每股凈資產計算非流通股的價格。
流通股市場價值=12月份周平均收盤價格×流通股股數
非流通股市場價值=每股凈資產×非流通股股數
上市公司股權市場價值=流通股市場價值+非流通股市場價值
3.債務面值、債務期限和無風險利率
公司債務面值D為公司財務年報中總負債面值。考慮到數據和工作量的限制,我們設定違約距離的計算時間為一年,即τ = 1。無風險利率使用中國人民銀行公佈的一年期定期整存整取的存款利率,見下表。
表 一年期定期存款利率表
| 年份 | 1999年 | 2000年 | 2001年 | 2002年 |
| 年利率 | r=2.25% | r=2.25% | r=2.25% | r=1.98% |
4.違約點的確定
當公司資產市場價值接近債務面值總額時,公司違約風險增加;當公司資產市場價值低於債務面值總額時,公司發生違約。但是,負債總額中的長期負債往往能緩解公司償還債務的壓力KMV公司研究表明.違約點值處於債務面值總額與流動負債之間的某一點,並且模型預測準確性對違約點值的變動比較敏感0因此.如何在中國股票市場中確定違約點值從而最大程度地提高模型的預測能力是必須重點研究的問題0為了考察不同違約點值對違約距離度量信用風險能力的影響,分別討論三種情況:。
(1)違約點值DP=流動負債
(2)違約點值DP=流動負債+50%長期負債
(3)違約點值DP=流動負債+75%長期負債
三、實證研究
1.樣本數據
眾所周知,上市公司連續兩年虧損即被ST處理,ST公司比一般上市公司存在較高的信用風險.本文研究樣本選取2003年被ST的30家上市公司及與之配對的30家非ST公司,共60家上市公司1999-2002年期間的市場和財務數據0為保證研究樣本的連續性及上市公司股權市場價值計算準確,樣本選取的60家公司均是1999年1月1日前上市並且在2003年1月1日前僅發行 A股的上市公司。在ST公司和非ST公司中.滬深兩市各有15家。考慮到樣本公司之間的可比性及最大限度避免交易場所、行業及規模對實證結論的干擾,選擇配對非ST公司主要依據以下3個條件:
(1)與配對ST公司同在一個證券交易所;
(2)與配對ST公司同屬一個行業;
(3)與配對ST公司具有相近的總資產規模。
樣本公司的財務數據和市場數據來自深圳市國泰安(GTA)信息技術有限公司中國上市公司財務資料庫和天軟金融分析資料庫。
四、實證結果分析
KMV模型能夠識別上市公司整體的信用風險變化趨勢從1999年-2002年ST公司與配對非ST公司違約距離的配對樣本t檢驗結果(表2)中.發現上市公司被ST前1年和前2年.在三種不同違約點值情況下,ST公司和非ST公司的違約距離的差異在\alpha=0.05%顯著水平下都是統計顯著的。在被ST前3年及前4年,違約距離差異在ST顯著水平下是統計不顯著的。儘管如此.我們還是可以看出,在公司被ST的前4年內,兩類公司的違約距離均值的差距有逐漸增大的趨勢;特別是在上市公司被ST的前2年,模型輸出的違約距離即顯著性地反映出ST公司信用狀況變壞的趨勢/在被ST前1年時,兩類公司違約距離均值的差距達到最大-0.7642,ST公司的違約距離均值遠小於非ST公司Wilcoxon檢驗表明(同見表2),在上市公司被ST的前1年和前2年,ST公司和非ST公司的違約距離的中值在α = 0.05%顯著水平下也存在顯著性差異。
同樣可以看出,從公司被ST前4年開始,ST公司與非ST公司違約距離中值差異的顯著性在逐漸增大,越是接近被ST的時候,違約距離中值的差異越是顯著。ST公司和非ST公司違約距離均值以及中值的顯著性差異說明,KMV模型在上市公司被ST前4年,即具有較強的識別公司信用狀況變化趨勢的能力。ST公司和非ST公司之間違約距離差距的逐漸擴大.且差異逐漸顯著,充分反映出了ST公司信用狀況逐漸惡化的過程0也就是說,與非ST公司相比,ST公司的信用風險在逐年增大。因此,在中國股票市場中,運用參數調整過的123模型能夠提前4年識別出上市公司整體的信用風險變化趨勢,ST公司與非ST公司作為兩類不同的公司,整體上的信用風險存在顯著性的差異。
違約距離檢驗結果表
| 違約點值DP | 前4年 | 前3年 | 前2年 | 前1年 | ||
|---|---|---|---|---|---|---|
| DP=流動負債 | 均值 | ST公司 | 2.2942 | 3.0785 | 2.1722 | 2.2933 |
| 非ST公司 | 2.3787 | 3.2987 | 2.4798 | 3.0445 | ||
| t-檢驗 | 均值差 | -0.0845 | -0.2202 | -0.3076 | -0.7512 | |
| t-值 | -0.6299 | -1.1968 | -1.9480 | -3.0077 | ||
| P值(雙尾) | 0.5316 | 0.2364 | 0.0565 | 0.0039 | ||
| Wilcoxon檢驗 | z-值 | -0.5656 | -0.5862 | -1.8409 | -3.4041 | |
| P值(雙尾) | 0.5716 | 0.5577 | 0.0656 | 0.007 | ||
| DP=流動負債+50%長期負債 | t-檢驗 | 均值差 | -0.0547 | -0.1772 | -0.3264 | -0.7583 |
| t-值 | -0.4294 | -0.9808 | -2.0889 | -3.3978 | ||
| P值(雙尾) | 0.6695 | 0.3308 | 0.0413 | 0.0014 | ||
| Wilcoxon檢驗 | z-值 | -0.3805 | -0.3805 | -2.0260 | -3.3218 | |
| P值(雙尾) | 0.7036 | 0.7036 | 0.0428 | 0.0009 | ||
| DP=流動負債+75%長期負債 | 均值 | ST公司 | 2.2423 | 3.0290 | 2.1043 | 2.1429 |
| 非ST公司 | 2.2820 | 3.1847 | 2.4395 | 2.9071 | ||
| t-檢驗 | 均值差 | -0.0397 | -0.1557 | -0.3352 | -0.7643 | |
| t-值 | -0.3176 | -0.8641 | -2.1511 | -3.5263 | ||
| P值(雙尾) | 0.7521 | 0.3911 | 0.0358 | 0.0010 | ||
| Wilcoxon檢驗 | z-值 | -0.4217 | -0.2365 | -2.0465 | -3.3835 | |
| P值(雙尾) | 0.6733 | 0.8130 | 0.0407 | 0.0007 |
2.模型具有較強的個體信用風險識別能力
ROC曲線(Receiver Operating Characteristic Curves)反映了信用風險模型在某一臨界點時識別評價對象信用風險的能力。X軸依據違約距離大小把非ST公司從小到大排列,Y軸是違約距離少於或等於某一給定 Y值時的ST公司累積百分比ROC曲線體現了模型在排除一定比例非ST公司時能夠排除多少比例ST公司的能力W該曲線離 對角線越遠,模型的分辨能力越強X反之則越弱,從圖1-4可以看出,在被ST前1年-前4年,當模型的違約點值設定為違約點值DP=流動負債時,模型對上市公司具有最強的分辨能力;違約點值DP=流動負債+50%長期負債,以及違約點值DP=流動負債+75%長期負債時,模型具有相近的分辨能力。這一點與KMV公司推薦的違約點等於流動負債加50%長期負債時X模型的判別分辨能力最強的結論略有不同W說明在中國上市公司中,ST公司比非ST公司具有較大的短期債務償還壓力W我國的上市公司在經營績效下降即將陷入財務困境的時候,較多地採取了增加短期債務融資的方式來維持公司的經營活動。
對角線越遠,模型的分辨能力越強X反之則越弱,從圖1-4可以看出,在被ST前1年-前4年,當模型的違約點值設定為違約點值DP=流動負債時,模型對上市公司具有最強的分辨能力;違約點值DP=流動負債+50%長期負債,以及違約點值DP=流動負債+75%長期負債時,模型具有相近的分辨能力。這一點與KMV公司推薦的違約點等於流動負債加50%長期負債時X模型的判別分辨能力最強的結論略有不同W說明在中國上市公司中,ST公司比非ST公司具有較大的短期債務償還壓力W我國的上市公司在經營績效下降即將陷入財務困境的時候,較多地採取了增加短期債務融資的方式來維持公司的經營活動。




因此,在未來一年內其違約風險比非ST公司要大得多。從下圖5看出,模型在上市公司被ST前1年具有最強的分辨能力;在被ST前2年,次之;被ST前3年,再次之;被ST前4年,最差W在公司被ST的前2年起X模型即具有較強的識別公司信用風險大小的能力]而且,越是接近公司被ST時,模型的識別能力越強。

實證表明KMV模型不僅能夠在上市公司被ST的前4年識別出上市公司整體上的信用狀況變化趨勢。而且在上市公司被ST的前2年對上市公司個體具有較強的信用風險判別能力;此外,違約點等於流動負債情況時,KMV模型對上市公司信用風險具有最強的識別能力;其他兩種違約點情況下模型的識別能力非常接近。根據上述結論,在中國證券市場完全可以利用KMV模型來及時識別上市公司的信用風險,為投資者、債權人、監管機構等相關人員和部門提供較為可靠的信用風險評價信息,為及時發現從而規避或者消除信用風險提供有益的策略參考。另外,由於股票價格信息除了反映公司歷史狀況,更為重要的是包含了市場對公司未來發展前景的預期。因此,投資者還可以參考模型的信用風險評價結果選擇低風險高收益的投資組合,最大限度地化解信用風險+保障資金的安全,實現收益最大化。
- ↑ 張玲,楊貞柿,陳收.KMV模型在上市公司信用風險評價中的應用研究[J].系統工程,2004,22(11)







{kind=link}
很有價值的模型