KMV模型
出自 MBA智库百科(https://wiki.mbalib.com/)
目录 |
KMV模型是美国旧金山市KMV公司于1997年建立的用来估计借款企业违约概率的方法。该模型认为,贷款的信用风险是在给定负债的情况下由债务人的资产市场价值决定的。但资产并没有真实地在市场交易,资产的市场价值不能直接观测到。为此,模型将银行的贷款问题倒转一个角度,从借款企业所有者的角度考虑贷款归还的问题。在债务到期日,如果公司资产的市场价值高于公司债务值(违约点),则公司股权价值为公司资产市场价值与债务值之间的差额;如果此时公司资产价值低于公司债务值,则公司变卖所有资产用以偿还债务,股权价值变为零。
首先,它利用Black-Scholes期权定价公式,根据企业股权的市场价值、股权价值的波动性、到期时间、无风险借贷利率及负债的账面价值估计出企业资产的市场价值及其波动性。
其次根据公司的负债计算出公司的违约实施点 (default exercise point,为企业1年以下短期债务的价值加上未清偿长期债务账面价值的一半),计算借款人的违约距离。
最后,根据企业的违约距离与预期违约率(EDF) 之间的对应关系,求出企业的预期违约率。
KMV模型的优势在于以现代期权理论基础作依托,充分利用资本市场的信息而非历史账面资料进行预测,将市场信息纳入了违约概率,更能反映上市企业当前的信用状况,是对传统方法的一次革命。KMV模型是一种动态模型,采用的主要是股票市场的数据,因此,数据和结果更新很快,具有前瞻性,是一种“向前看”的方法。在给定公司的现时资产结构的情况下,一旦确定出资产价值的随机过程,便可得到任一时间单位的实际违约概率。其劣势在于假设比较苛刻,尤其是资产收益分布实际上存在“肥尾”现象,并不满足正态分布假设;仅抓住了违约预测,忽视了企业信用品质的变化;没有考虑信息不对称情况下的道德风险;必须使用估计技术来获得资产价值、企业资产收益率的期望值和波动性;对非上市公司因使用资料的可获得性差,预测的准确性也较差;不能处理非线性产品,如期权、外币掉期等。
KMV模型自1993年推出以来,国外学术界对KMV模型的研究经历了两个阶段:
第一阶段是将KMV模型的预测结果与实际的违约数据相比较,大多数研究结果表明,KMV模型能够反映信用风险的高低,并对信用风险具有很高的敏感性。
第二阶段,国外学术界对模型的验证寻找到新的角度,并开发出多种验证模型有效性的方法和技术。
我国学者主要对模型在我国适应性和参数调整方面进行了许多探讨,取得了一定的成果。张林、张佳林(2000)、王琼、陈金贤(2002) 先后对KMV模型与其他模型进行理论上比较,认为更适合于评价上市公司的信用风险。薛锋,鲁炜,赵恒街,刘冀云(2003)利用中国股市的数据,得出了应中市场的σv和σE的关系函数,并以一只股票为样本进行了实证分析。乔卓等(2003)介绍了KMV模型的基本内容,以及国外的应用经验,但是并没有进行实证研究。易丹辉,吴建民(2004年)对深市和沪市随机抽取30家公司分行业计算违约距离和违约率并作比较,认为借助违约距离衡量上市公司的信用风险是可行的。
由于缺少大量违约公司样本的历史数据库,因此,我国目前无法通过比较违约距离和破产频率的历史,拟合出代表公司违约距离的预期违约率函数。本文尝试使用上市公司在某国有商业银行贷款不良率替代其违约率,并根据我国资本市场的特点,选取KMV模型的相关参数,同时采用某国有商业银行 2001年12月31日的235家贷款客户的不良率来替代上市公司的违约率进行实证分析,建立违约距离与不良率的函数关系。
KMV是运用现代期权定价理论建立起来的违约预测模型,是对传统信用风险度量方法的一次重要革命。首先,KMV可以充分利用资本市场上的信息,对所有公开上市企业进行信用风险的量化和分析;其次,由于该模型所获取的数据来自股票市场的资料,而非企业的历史数据,因而更能反映企业当前的信用状况,具有前瞻性,其预测能力更强、更及时,也更准确;另外,KMV模型建立在当代公司理财理论和期权理论的基础之上,具有很强的理论基础做依托。
但是,KMV模型与其他已有的模型一样,仍然存在许多缺陷。首先,模型的使用范围有一定的局限性。通常,该模型特别适用于上市公司的信用风险评估,而对非上市公司进行应用时,往往要借助一些会计信息或其他能够反映借款企业特征值的指标来替代模型中一些重要变量,同时还要通过对比分析最终得出该企业的期望违约概率,在一定程度上就有可能降低计算的准确性。其次,该模型假设公司的资产价值服从正态分布,而实际中企业的资产价值一般会呈现非正态的统计特征。再次,模型不能够对债务的不同类型进行区分,如偿还优先顺序、担保、契约等类型,使得模型的输出变量的计算结果不准确。北达公司根据中国过渡经济的资本市场的特点,开发具有中国特色的上市公司信用KMV模型目前在进行压力测试阶段.
KMV模型与creditmetrics模型是目前国际金融界最流行的两个信用风险管理模型。两者都为银行和其它金融机构在进行贷款等授信业务时衡量授信对象的信用状况,分析所面临的信用风险,防止集中授信,进而为实现投资分散化和具体的授信决策提供量化的、更加科学的依据,为以主观性和艺术性为特征的传统信用分析方法提供了很好的补偿。然而,从上述的介绍和分析中,我们又可以明显地看到这两个模型在建模的基本思路上又相当大的差异,这些差异还主要表现在以下几个方面。
1、KMV模型对企业信用风险的衡量指标edf主要来自于对该企业股票市场价格变化的有关数据的分析,而creditmetrics模型对企业信用风险的衡量来自于对该企业信用评级变化及其概率的历史数据的分析。这是两者最根本的区别之一。
2、由于KMV模型采用的是企业股票市场价格分析方法,这使得该模型可以随时根据该企业股票市场价格的变化来更新模型的输入数据,得出及时反映市场预期和企业信用状况变化的新的edf值。因此,kmv模型被认为是一种动态模型,可以及时反映信用风险水平的变化。然而,creditmetrics采用的是企业信用评级指标分析法。企业信用评级,无论是内部评级还是外部评级,都不可能象股票市场价格一样是动态变化的,而是在相当长的一段时间内保持静态特征。这有可能使得该模型的分析结果不能及时反映企业信用状况的变化。
3 、同时,也正是因为kmv模型所提供的edf指标来自于对股票市场价格实时行情的分析,而股票市场的实时行情不仅反映了该企业历史的和当前的发展状况,更重要的是反映了市场中的投资者对于该企业未来发展的综合预期,所以,该模型被认为是一种向前看(forward-looking)的方法,edf指标中包含了市场投资者对该企业信用状况未来发展趋势的判断。这与creditmetrics模型采用的主要依赖信用状况变化的历史数据的向后看(backward-looking)的方法有根本性的差别。kmv的这种向前看的分析方法在一定程度上克服了依赖历史数据向后看的数理统计模型的“历来可以在未来复制其自身”的缺陷。
4 、KMV模型所提供的edf指标在本质上是一种对风险的基数衡量法,而creditmetrics所采用的与信用评级分析法则是一种序数衡量法,两者完全不同。以基数法来衡量风险最大的特点在于不仅可以反映不同企业风险水平的高低顺序,而且可以反映风险水平差异的程度,因而更加准确。这也更加有利于对贷款的定价。而序数衡量法只能反映企业间信用风险的高低顺序,如bbb级高于bb级,却不能明确说明高到什么程度。
5、creditmetrics采用的是组合投资的分析方法,注重直接分析企业间信用状况变化的相关关系,因而更加与现代组合投资管理理论相吻合。而kmv则是从单个授信企业在股票市场上的价格变化信息入手,着重分析该企业体现在股价变化信息中的自身信用状况,对企业信用变化的相关性没有给予足够的分析。
案例一:KMV模型在上市公司信用风险评价中的分析[1]
一、KMV模型
KMV模型的基本思路是:当企业资产市场价值V低于企业所需清偿的负债面值D时,企业将发生违约;以违约距离DD表示企业资产市场价值期望值V距离违约点DP,的远近,距离越大,企业发生违约的可能性越小,反之较大;基于企业违约数据库得出某一违约距离企业实际的期望违约频率EDF;即未来违约概率。计算某一企业的期望违约频率主要有三步:估计企业资产市场价值V和波动率\sigma_V;计算违约距离DD;计算期望违约频率EDF。由于不能直接观测到V和\sigma_V,因此需要从它们与股权市场价值E、股权市场价值波动率\sigma_E以及企业负债面值D之间的关系中推导得出。
KMV模型将企业负债看作是买入一份欧式看涨期权,即企业所有者持有一份以公司债务面值为执行价格,以公司资产市场价值为标的的欧式看涨期权/如果负债到期时企业资产市场价值高于其债务,企业偿还债务;当企业资产市场价值小于其债务时,企业选择违约/由于企业股权市场价值可以用Black-Scholes-Merton期权定价模型来定价,因此,KMV模型中的两个未知变量V和σV可从以下联立方程组中求解:
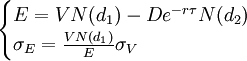 (1)
(1)
其中
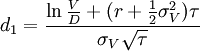
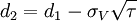
式中:E为企业股权市场价值,V为企业资产市场价值,D为企业债务面值,r为无风险收益率,τ为债务偿还期限,N(d)为标准累积正态分布函数,σV为企业资产价值波动率,σE为企业股权市场价值波动率。假设企业资产未来市场价值围绕企业资产市场价值的均值呈正态分布,那么,我们可以用式(2)计算负债企业的违约距离DD(Distance to Default):
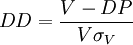 (2)
(2)
式中:DP(Default Point)为违约点值,处于公司的流动负债与总负债之间的某一点/违约距离DD以资产市场价值标准差的倍数表示,评估企业在τ时间后信用风险的大小。根据违约距离DD的定义,公司资产市场价值低于违约点的概率,即理论上发生违约的概率为1-N(DD)。而基于违约数据库,依据违约距离可以映射出公司实际的期望违约频率EDF。由于我国当前还没有公开的违约数据库可以使用,以违约距离DD作为上市公司信用评价的依据。
二、研究方法及参数设计
针对中国上市公司股权结构和所处市场环境的特殊性,考虑中国上市公司股权割裂导致的流通股和非流通股之间的价格差异,以及在中国上市公司所处特殊市场环境下,违约点设定对模型预测能力的影响。首先调整模型中股权市场价值计算方法;根据已经确定的各项参数,由式(1)求解出未知的两项V和σV再由式(2)计算出三种违约点值情况下样本公司的违约距离DD;然后对配对样本的违约距离作t检验和Wilcoxon秩检验,检验KMV模型对上市公司整体信用风险的识别能力;最后使用ROC曲线图评价模型对上市公司个体信用风险的识别能力。
1.上市公司股权市场价值波动率的估计
采用历史波动率法估计上市公司股权市场价值未来一年的波动率。假设上市公司股票价格满足对数正态分布,则股票周收益率ui为。
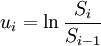 (3)
(3)
式中:Si,Si − 1为股票复权后的周收盘价。计算出公司股权市场价值的年波动率σE。
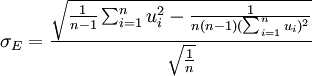 (4)
(4)
式中:E为一年内的交易周数,通过式(3)、式(4)可以估算每一公司股权市场价值的年波动率。
2.上市公司股权市场价值计算方法
中国证券市场发展历史较为特殊,上市公司股票被人为分割为上市流通股票和暂不上市流通股票两种。在计算上市公司股权市场价值时需要考虑以什么样的价格来计算非流通股市场价值/由于非流通股没有市场交易价格,因此如何给非流通股定价是一件困难的事情。参考上市公司股票全流通研究中非流通股定价,以每股净资产计算非流通股的价格。
流通股市场价值=12月份周平均收盘价格×流通股股数
非流通股市场价值=每股净资产×非流通股股数
上市公司股权市场价值=流通股市场价值+非流通股市场价值
3.债务面值、债务期限和无风险利率
公司债务面值D为公司财务年报中总负债面值。考虑到数据和工作量的限制,我们设定违约距离的计算时间为一年,即τ = 1。无风险利率使用中国人民银行公布的一年期定期整存整取的存款利率,见下表。
表 一年期定期存款利率表
| 年份 | 1999年 | 2000年 | 2001年 | 2002年 |
| 年利率 | r=2.25% | r=2.25% | r=2.25% | r=1.98% |
4.违约点的确定
当公司资产市场价值接近债务面值总额时,公司违约风险增加;当公司资产市场价值低于债务面值总额时,公司发生违约。但是,负债总额中的长期负债往往能缓解公司偿还债务的压力KMV公司研究表明.违约点值处于债务面值总额与流动负债之间的某一点,并且模型预测准确性对违约点值的变动比较敏感0因此.如何在中国股票市场中确定违约点值从而最大程度地提高模型的预测能力是必须重点研究的问题0为了考察不同违约点值对违约距离度量信用风险能力的影响,分别讨论三种情况:。
(1)违约点值DP=流动负债
(2)违约点值DP=流动负债+50%长期负债
(3)违约点值DP=流动负债+75%长期负债
三、实证研究
1.样本数据
众所周知,上市公司连续两年亏损即被ST处理,ST公司比一般上市公司存在较高的信用风险.本文研究样本选取2003年被ST的30家上市公司及与之配对的30家非ST公司,共60家上市公司1999-2002年期间的市场和财务数据0为保证研究样本的连续性及上市公司股权市场价值计算准确,样本选取的60家公司均是1999年1月1日前上市并且在2003年1月1日前仅发行 A股的上市公司。在ST公司和非ST公司中.沪深两市各有15家。考虑到样本公司之间的可比性及最大限度避免交易场所、行业及规模对实证结论的干扰,选择配对非ST公司主要依据以下3个条件:
(1)与配对ST公司同在一个证券交易所;
(2)与配对ST公司同属一个行业;
(3)与配对ST公司具有相近的总资产规模。
样本公司的财务数据和市场数据来自深圳市国泰安(GTA)信息技术有限公司中国上市公司财务数据库和天软金融分析数据库。
四、实证结果分析
KMV模型能够识别上市公司整体的信用风险变化趋势从1999年-2002年ST公司与配对非ST公司违约距离的配对样本t检验结果(表2)中.发现上市公司被ST前1年和前2年.在三种不同违约点值情况下,ST公司和非ST公司的违约距离的差异在\alpha=0.05%显著水平下都是统计显著的。在被ST前3年及前4年,违约距离差异在ST显著水平下是统计不显著的。尽管如此.我们还是可以看出,在公司被ST的前4年内,两类公司的违约距离均值的差距有逐渐增大的趋势;特别是在上市公司被ST的前2年,模型输出的违约距离即显著性地反映出ST公司信用状况变坏的趋势/在被ST前1年时,两类公司违约距离均值的差距达到最大-0.7642,ST公司的违约距离均值远小于非ST公司Wilcoxon检验表明(同见表2),在上市公司被ST的前1年和前2年,ST公司和非ST公司的违约距离的中值在α = 0.05%显著水平下也存在显著性差异。
同样可以看出,从公司被ST前4年开始,ST公司与非ST公司违约距离中值差异的显著性在逐渐增大,越是接近被ST的时候,违约距离中值的差异越是显著。ST公司和非ST公司违约距离均值以及中值的显著性差异说明,KMV模型在上市公司被ST前4年,即具有较强的识别公司信用状况变化趋势的能力。ST公司和非ST公司之间违约距离差距的逐渐扩大.且差异逐渐显著,充分反映出了ST公司信用状况逐渐恶化的过程0也就是说,与非ST公司相比,ST公司的信用风险在逐年增大。因此,在中国股票市场中,运用参数调整过的123模型能够提前4年识别出上市公司整体的信用风险变化趋势,ST公司与非ST公司作为两类不同的公司,整体上的信用风险存在显著性的差异。
违约距离检验结果表
| 违约点值DP | 前4年 | 前3年 | 前2年 | 前1年 | ||
|---|---|---|---|---|---|---|
| DP=流动负债 | 均值 | ST公司 | 2.2942 | 3.0785 | 2.1722 | 2.2933 |
| 非ST公司 | 2.3787 | 3.2987 | 2.4798 | 3.0445 | ||
| t-检验 | 均值差 | -0.0845 | -0.2202 | -0.3076 | -0.7512 | |
| t-值 | -0.6299 | -1.1968 | -1.9480 | -3.0077 | ||
| P值(双尾) | 0.5316 | 0.2364 | 0.0565 | 0.0039 | ||
| Wilcoxon检验 | z-值 | -0.5656 | -0.5862 | -1.8409 | -3.4041 | |
| P值(双尾) | 0.5716 | 0.5577 | 0.0656 | 0.007 | ||
| DP=流动负债+50%长期负债 | t-检验 | 均值差 | -0.0547 | -0.1772 | -0.3264 | -0.7583 |
| t-值 | -0.4294 | -0.9808 | -2.0889 | -3.3978 | ||
| P值(双尾) | 0.6695 | 0.3308 | 0.0413 | 0.0014 | ||
| Wilcoxon检验 | z-值 | -0.3805 | -0.3805 | -2.0260 | -3.3218 | |
| P值(双尾) | 0.7036 | 0.7036 | 0.0428 | 0.0009 | ||
| DP=流动负债+75%长期负债 | 均值 | ST公司 | 2.2423 | 3.0290 | 2.1043 | 2.1429 |
| 非ST公司 | 2.2820 | 3.1847 | 2.4395 | 2.9071 | ||
| t-检验 | 均值差 | -0.0397 | -0.1557 | -0.3352 | -0.7643 | |
| t-值 | -0.3176 | -0.8641 | -2.1511 | -3.5263 | ||
| P值(双尾) | 0.7521 | 0.3911 | 0.0358 | 0.0010 | ||
| Wilcoxon检验 | z-值 | -0.4217 | -0.2365 | -2.0465 | -3.3835 | |
| P值(双尾) | 0.6733 | 0.8130 | 0.0407 | 0.0007 |
2.模型具有较强的个体信用风险识别能力
ROC曲线(Receiver Operating Characteristic Curves)反映了信用风险模型在某一临界点时识别评价对象信用风险的能力。X轴依据违约距离大小把非ST公司从小到大排列,Y轴是违约距离少于或等于某一给定 Y值时的ST公司累积百分比ROC曲线体现了模型在排除一定比例非ST公司时能够排除多少比例ST公司的能力W该曲线离 对角线越远,模型的分辨能力越强X反之则越弱,从图1-4可以看出,在被ST前1年-前4年,当模型的违约点值设定为违约点值DP=流动负债时,模型对上市公司具有最强的分辨能力;违约点值DP=流动负债+50%长期负债,以及违约点值DP=流动负债+75%长期负债时,模型具有相近的分辨能力。这一点与KMV公司推荐的违约点等于流动负债加50%长期负债时X模型的判别分辨能力最强的结论略有不同W说明在中国上市公司中,ST公司比非ST公司具有较大的短期债务偿还压力W我国的上市公司在经营绩效下降即将陷入财务困境的时候,较多地采取了增加短期债务融资的方式来维持公司的经营活动。
对角线越远,模型的分辨能力越强X反之则越弱,从图1-4可以看出,在被ST前1年-前4年,当模型的违约点值设定为违约点值DP=流动负债时,模型对上市公司具有最强的分辨能力;违约点值DP=流动负债+50%长期负债,以及违约点值DP=流动负债+75%长期负债时,模型具有相近的分辨能力。这一点与KMV公司推荐的违约点等于流动负债加50%长期负债时X模型的判别分辨能力最强的结论略有不同W说明在中国上市公司中,ST公司比非ST公司具有较大的短期债务偿还压力W我国的上市公司在经营绩效下降即将陷入财务困境的时候,较多地采取了增加短期债务融资的方式来维持公司的经营活动。




因此,在未来一年内其违约风险比非ST公司要大得多。从下图5看出,模型在上市公司被ST前1年具有最强的分辨能力;在被ST前2年,次之;被ST前3年,再次之;被ST前4年,最差W在公司被ST的前2年起X模型即具有较强的识别公司信用风险大小的能力]而且,越是接近公司被ST时,模型的识别能力越强。

实证表明KMV模型不仅能够在上市公司被ST的前4年识别出上市公司整体上的信用状况变化趋势。而且在上市公司被ST的前2年对上市公司个体具有较强的信用风险判别能力;此外,违约点等于流动负债情况时,KMV模型对上市公司信用风险具有最强的识别能力;其他两种违约点情况下模型的识别能力非常接近。根据上述结论,在中国证券市场完全可以利用KMV模型来及时识别上市公司的信用风险,为投资者、债权人、监管机构等相关人员和部门提供较为可靠的信用风险评价信息,为及时发现从而规避或者消除信用风险提供有益的策略参考。另外,由于股票价格信息除了反映公司历史状况,更为重要的是包含了市场对公司未来发展前景的预期。因此,投资者还可以参考模型的信用风险评价结果选择低风险高收益的投资组合,最大限度地化解信用风险+保障资金的安全,实现收益最大化。
- ↑ 张玲,杨贞柿,陈收.KMV模型在上市公司信用风险评价中的应用研究[J].系统工程,2004,22(11)







{kind=link}
很有价值的模型