抽樣分佈
出自 MBA智库百科(https://wiki.mbalib.com/)
- 抽樣分佈(Sampling Distribtuion)
目錄 |
什麼是抽樣分佈[1]
抽樣分佈也稱統計量分佈、隨機變數函數分佈,是指樣本估計量的分佈。樣本估計量是樣本的一個函數,在統計學中稱作統計量,因此抽樣分佈也是指統計量的分佈。以樣本平均數為例,它是總體平均數的一個估計量,如果按照相同的樣本容量,相同的抽樣方式,反覆地抽取樣本,每次可以計算一個平均數,所有可能樣本的平均數所形成的分佈,就是樣本平均數的抽樣分佈。
抽樣分佈的類型[2]
- 一、單一樣本統計量的抽樣分佈
當我們要對某一總體的參數進行估計時,就要研究來自該總體的所有可能的樣本統計量的分佈問題,比如樣本均值的分佈、樣本比例的分佈,從而概括有關統計量抽樣分佈的一般規律。
- (一)樣本均值的抽樣分佈
- 1.樣本均值抽樣分佈的形成
樣本均值的抽樣分佈即所有樣本均值的可能取值形成的概率分佈。例如,某高校大一年級參加英語四級考試的人數為6000人,為了研究這6000人的平均考分,欲從中隨機抽取500人組成樣本進行觀察。若逐一抽取全部可能樣本,並計算出每個樣本的平均考分,將會得出很多不完全相同的樣本均值,全部可能的樣本均值有一個相應的概率分佈,即為樣本均值的抽樣分佈。
我們知道,從總體的N個單位中抽取一個容量為n的隨機樣本,在重覆抽樣條件下,共有Nn個可能的樣本;在不重覆抽樣條件下,共有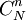 =
= 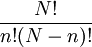 個可能的樣本。因此,樣本均值是一個隨機變數。
個可能的樣本。因此,樣本均值是一個隨機變數。
- 2.樣本均值抽樣分佈的特征
從抽樣分佈的角度看,我們所關心的分佈的特征主要是數學期望和方差。這兩個特征一方面與總體分佈的均值和方差有關,另一方面也與抽樣的方法是重覆抽樣還是不重覆抽樣有關。
無論是重覆抽樣還是不重覆抽樣,樣本均值的期望值總是等於總體均值μ,即:
公式一: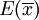 = μ
= μ
樣本均值的方差則與抽樣方法有關。在重覆抽樣條件下,樣本均值的方差為總體方差的1/n,即:
公式二: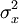 =
= 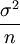
在不重覆抽樣條件下,樣本均值的方差為:
公式三: = 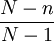
從公式二和公式三可以看出兩者僅相差繫數,該繫數通常被稱為有限總體修正繫數。在實際應用中,這一繫數常常被忽略不計,主要是因為:對於無限總體進行不重覆抽樣時,由於N未知,此時樣本均值的標準差仍可按公式二計算,即可按重覆抽樣處理;對於有限總體,當N很大而抽樣比例n/N很小時,其修正繫數=1 - 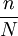
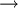 1,通常在樣本容量n小於總體容量N的5%時,有限總體修正繫數就可以忽略不計。因此,公式二是計算樣本均值方差的常用公式。
1,通常在樣本容量n小於總體容量N的5%時,有限總體修正繫數就可以忽略不計。因此,公式二是計算樣本均值方差的常用公式。
- 3.樣本均值抽樣分佈的形式
樣本均值抽樣分佈的形式與原有總體的分佈和樣本容量n的大小有關。
如果原有總體是正態分佈,那麼,無論樣本容量的大小,樣本均值的抽樣分佈都服從正態分佈。
如果原有總體的分佈是非正態分佈,就要看樣本容量的大小。隨著樣本容量n的增大(通常要求n≥30),不論原來的總體是否服從正態分佈,樣本均值的抽樣分佈都將趨於正態分佈,即統計上著名的中心極限定理。
(2)雖然總體成績的分佈形態未知,但σ已知,且n=150為大樣本,依據中心極限定理可知:樣本均值的抽樣分佈近似服從正態分佈。
- (二)樣本比例的抽樣分佈
樣本比例即指樣本中具有某種特征的單位所占的比例。樣本比例的抽樣分佈就是所有樣本比例的可能取值形成的概率分佈。例如,某高校大一年級學生參加英語四級考試的人數有6000人,為了估計這6000人中男生所占的比例,從中抽取500人組成樣本進行觀察,若逐一抽取全部可能樣本,並計算出每個樣本的男生比例,則全部可能的樣本比例的概率分佈,即為樣本比例的抽樣分佈。可見,樣本比例也是一個隨機變數。
- 1.樣本比例抽樣分佈的特征
在大樣本情況下,樣本比例的抽樣分佈特征可概括如下:
無論是重覆抽樣還是不重覆抽樣,樣本比例p的數學期望總是等於總體比例P,即:
公式一:E(p)=P
而樣本比例p的方差,在重覆抽樣條件下為:
公式二: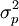 =
=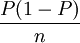
在不重覆抽樣條件下為:
= 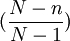
- 2.樣本比例抽樣分佈的形式
樣本比例的分佈屬於二項分佈問題,當樣本容量n足夠大時,即當nP與n(1一P)都不小於5時,樣本比例的抽樣分佈近似為正態分佈。
- 二、兩個樣本統計量的抽樣分佈
如果要對兩個總體有關參數的差異進行估計,就要研究來自這兩個總體的所有可能樣本相應統計量差異的抽樣分佈。
- (一)兩個樣本均值差異的抽樣分佈
若從總體X1和總體X2中分別獨立地抽取容量為n1和n2的樣本,則由兩個樣本均值之差 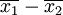 的所有可能取值形成的概率分佈稱為兩個樣本均值差異的抽樣分佈。
的所有可能取值形成的概率分佈稱為兩個樣本均值差異的抽樣分佈。
設總體X1和總體X2的均值分別為μ1和μ2,標準差分別為σ1和σ2,則兩個樣本均值之差的抽樣分佈可概括為以下兩種情況:
(1)若總體X1—N(μ1,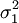 ),總體X2—N(μ2,
),總體X2—N(μ2,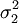 ),則
),則
— N(μ1 − μ2,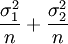 )
)
(2)若兩個總體都是非正態總體,當兩個樣本容量n1和n2都足夠大時,依據中心極限定理,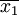 和
和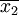 分別近似服從正態分佈,則— N(μ1 − μ2,)。
分別近似服從正態分佈,則— N(μ1 − μ2,)。
- (二)兩個樣本比例差異的抽樣分佈
若從總體X1和總體X2中分別獨立地抽取容量為n1和n2的樣本,則由兩個樣本比例之差p1 − p2的所有可能取值形成的概率分佈,稱為兩個樣本比例差異的抽樣分佈。
設兩個總體的比例分別為P1和P2,當兩個樣本容量n1和n2都足夠大時,根據中心極限定理,p1和p2分別近似服從正態分佈,則有
p1 − p2—N(P1-P2,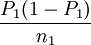 +
+ 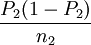 )
)
抽樣分佈的幾個定理[3]
(1)從總體中隨機抽取容量為n的一切可能個樣本的平均數之平均數,等於總體的平均數,即 = μ,(E為平均的符號,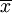 為樣本的平均數,μ為總體的平均數)。
為樣本的平均數,μ為總體的平均數)。
(2)容量為n的樣本平均數在抽樣分佈上的標準差,等於總體標準差除以n的方根,即σx = 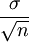 ,(σx為平均數抽樣分佈的標準差,σ為總體標準差,n為樣本容量。)
,(σx為平均數抽樣分佈的標準差,σ為總體標準差,n為樣本容量。)
(3)從正態總體中,隨機抽取的容量為n的一切可能樣本平均數的分佈也呈正態分佈。
(4)雖然總體不是正態分佈,如果樣本容量較大,反映總體μ和σ的樣本平均數的抽樣分佈,也接近於正態分佈。
抽樣分佈、樣本分佈和總體分佈[4]
統計中用隨機變數X的取值範圍及其取值概率的序列來描述這個隨機變數,稱之為隨機變數X的概率分佈。如果我們知道隨機變數X的取值範圍及其取值概率的序列,就可以用某種函數來表述X取值小於某個值的概率,即為分佈函數:F(X)=P(X≤z)。
例如,一個由N家工業企業組成的總體,X為銷售收入。將總體所有企業的銷售收入按大小順序排隊,累計出總體中銷售收入小於某值x的企業數量並除以總體企業總數N,就可得到總體中銷售收入小於x的企業的頻率,也即抽取一個銷售收入小於x的企業的概率。此頻率或概率隨著x值不同而變化形成一個序列,形成了銷售收入X的概率分佈。
總體分佈是在總體中X的取值範圍及其概率。
樣本分佈是在樣本中X的取值範圍及其概率。上例中,如果抽取n個企業作為樣本,我們同樣可以用這n個銷售收入的取值範圍及其概率描述其分佈,也即樣本分佈。樣本分佈也稱為經驗分佈,隨著樣本容量n的逐漸增大,樣本分佈逐漸接近總體分佈。
抽樣分佈是指樣本統計量的概率分佈。採用同樣的抽樣方法和同等的樣本量,從同一個總體中可以抽取出許許多多不同的樣本,每個樣本計算出的樣本統計量的值也是不同的。樣本統計量也是隨機變數,抽樣分佈則是樣本統計量的取值範圍及其概率。仍以工業企業為例,我們設計了一個抽樣方案並確定了樣本量,這時可能抽取的樣本是眾多的,每抽取一個樣本就可以計算出一個企業平均銷售收入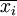 ,所有可能形成的分佈就是抽樣分佈。例中,樣本統計量為隨機變數,抽樣分佈是的概率分佈。
,所有可能形成的分佈就是抽樣分佈。例中,樣本統計量為隨機變數,抽樣分佈是的概率分佈。
研究概率分佈對於抽樣調查是十分重要的,因為只有知道概率分佈,才能夠利用抽樣技術推斷抽樣誤差。現實中,總體的分佈狀況通常是未知的,但我們也無需知道總體分佈,而只需知道抽樣分佈。







{kind=link}
Hey, there. The spelling of distribution is wrong, not "btu", it is "but". Please correct it or we may not find out this item from English search. Thanks a lot!!!