抽樣
出自 MBA智库百科(https://wiki.mbalib.com/)
抽樣(Sampling)
目錄 |
抽樣就是從研究總體中選取一部分代表性樣本的方法。例如我們要研究某城市居民的生活方式問題,那麼整個城市居民都是我們的研究對象。但限於研究條件等原因,我們難以對每一個居民進行調查研究,而只能採用一定的方法選取其中的部分居民作為調查研究的對象,這種選擇調查研究對象的過程就是抽樣。採用抽樣法進行的調查就稱為抽樣調查。抽樣調查是最常用的調查研究方法之一,它已被廣泛應用到社會調查、市場調查和輿論調查等多個領域。
抽樣對調查研究來說至關重要。社會科學研究的對象通常是非常複雜的,涉及到社會生活的方方面面,既包括個體行動者,也包括群體甚至整個社區或社會。但在大多數情況下,我們難以對全部的對象做研究,而只能研究其中的一部分。對這部分研究對象的選擇就要依靠抽樣來完成,如此可以節省研究的成本和時間。但我們的研究又不是停留在所選取的樣本本身,而是通過對有代表性的樣本的分析來研究總體。故抽樣的目的,就是從研究對象總體中抽選一部分作為代表進行調查分析,並根據這一部分樣本去推論總體情況。
抽樣已發展出了自己的一套專門術語,主要包括如下一些:
1、總體或抽樣總體(population)
總體(population)通常與構成它的元素共同定義:總體是指構成它的所有元素的集合,而元素則是構成總體的最基本單位。在社會研究中,最常見的總體是由社會中的某些個人組成的,這些個人便是構成總體的元素。
比如,當我們開展對某省大學生的擇業傾向進行研究和探討時,該省所有在校大學生的集合就是我們研究的總體,而每一個在校大學生便是構成總體的元素。又比如,我們打算研究某城市居民的家庭生活質量,那麼,該市所有的居民家庭就構成我們研究的總體,而其中的每一戶家庭都是這個總體中的一個元素。
2、樣本(sample)
樣本與總體相對應,是指用來代表總體的單位,樣本實際上是總體中某些單位的子集。樣本不是總體,但它應代表總體,以抽樣的標準就是讓所選擇的樣本最大程度地代表總體。
3、抽樣單位或抽樣元素(sampling unit/element)
抽樣單位或抽樣元素是指收集信息的基本單位和進行分析的元素。在社會科學研究中,常用的抽樣單位是個體的人,它也可以是一定類型的群體或組織,如家庭、公司、居委會、社區等。抽樣單位與抽樣元素有時是一致的,有時是不一致的。如在簡單抽樣中,它們是一致的,但在整群或多階段抽樣中,抽樣單位是群體,而每個群體單位中又包含許多抽樣元素。
4、抽樣框(sampling frame)
抽樣框又稱做抽樣範圍,它指的是抽樣過程中所使用的所有抽樣單位的名單。比如,從一所中學的全體學生中,直接抽取200名學生作為樣本。那麼,這所中學全體學生的名單就是這次抽樣的抽樣框;如果是從這所中學的所有班級中抽取部分班級的學生作為調查的樣本,那麼,此時的抽樣框就不再是全校學生的名單,而是全校所有班級的名單了。
5、參數值與統計值
參數值(parameter)也稱總體值,是指反映總體中某變數的特征值。例如某地所有職工的平均收入水平和總體收入等都是參數值。但參數值多是理論值,難以具體確定。通常是根據樣本的統計值來推論總體的參數值。
統計值(dstatistic)也稱樣本值,是指對樣本中某變數特征的描述。它通常是實際統計分析的數值。例如,根據某一樣本資料可計算其平均收入水平、構成比例等。用樣本統值去推論參數值時,二者是一一對應的。下表列出了常見的一些特征值:
| 參數值 | 統計值 | |
|---|---|---|
| 定義 | 反映總體特征的指標 | 反映樣本特征的指標 |
| 特征值 | N (總體數) μ(總體均值) σ(總體標準差) P(總體成數) | n(樣本數)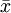 (樣本均值) (樣本均值)s(樣本標準差) p(樣本成數) |
6、抽樣誤差(sampling error)
樣本統計值與所要推論的總體參數值之間的均差值就稱為抽樣誤差。這是由抽樣本身產生的誤差,它反映的是樣本對總體的表性程度,故又稱代表性誤差。我們在下麵將結合樣本數的確定再做具體討論。
7、置信水平與置信區間(confidence 1evel and interval)
置信水平和置信區間是與抽樣誤差密切相關的兩個概念。置信水平,又稱置信度,是指總體參數值落在某一區間內的概率。
而置信區間是指在某一置信水平下,用樣本統計值推論總體參數值的範圍。其大小與誤差密切相關,置信區間越大,誤差也越大。
根據概率論原理常用的抽樣形式主要分為隨機抽樣和非隨機抽樣兩大類。二者的區別在於:前者按照隨機原則來抽取樣本,而後者不按隨機原則抽取樣本。
(一)隨機抽樣
隨機抽樣又稱概率抽樣,是指嚴格按照隨機原則來抽取樣本,要求總體中每個單位都有被抽取的同等機會。由隨機抽樣所抽取的樣本稱為隨機樣本,這類樣本具有較高的代表性。隨機抽樣法又分為下列五種不同的抽樣方法:
1、簡單隨機抽樣
簡單隨機抽樣,也稱純隨機抽樣,是指按照隨機原則從總體單位中直接抽取若幹單位組成樣本。它是最基本的概率抽樣形式,也是其他幾種隨機抽樣方法的基礎。
2、等距隨機抽樣
等距隨機抽樣也稱機械隨機抽樣或系統隨機抽樣,是指按照一定的間隔,從根據一定的順序排列起來的總體單位中抽取樣本的一種方法。具體做法是:首先將總體各單位按照一定的順序排列起來,編上序號;然後用總體單位數除以樣本單位數得出抽樣間隔;最後採取簡單隨機抽樣的方式在第一個抽樣間隔內隨機抽取一個單位作為第一個樣本,再依次按抽樣間隔做等距抽樣,直到抽取最後一個樣本為止。
3、分層隨機抽樣
分層隨機抽樣,也稱類型隨機抽樣,是指首先將調查對象的總體單位按照一定的標準分成各種不同的類別(或組),然後根據各類別(或組)的單位數與總體單位數的比例確定從各類別(或組)中抽取樣本的數量,最後按照隨機原則從各類(或組)中抽取樣本。
4、整群隨機抽樣
整群隨機抽樣,又稱聚類抽樣,是先把總體分為若幹個子群,然後一群一群地抽取作為樣本單位。它通常比簡單隨機抽樣和分層隨機抽樣更實用,像後者那樣,它也需要將總體分成類群,所不同的是,這些分類標準往往是特殊的。具體做法是:先將各子群體編碼,隨機抽取分群數位,然後對所抽樣本群或組實施調查。因此,整群抽樣的單位不是單個的分子,而是成群成組的。凡是被抽到的群或組,其中所有的成員都是被調查的對象。這些群或組可以是一個家庭、一個班級,也可以是一個街道、一個村莊。
5、分段隨機抽樣
分段隨機抽樣,也稱多段隨機抽樣或階段隨機抽樣,是一種分階段從調查對象的總體中抽取樣本進行調查的方法。它首先要將總體單位按照一定的標準劃分為若幹群體,作為抽樣的第一級單位;再將第一級單位分為若幹小的群體,作為抽樣的第二級單位;以此類推,可根據需要分為第三級或第四級單位。然後,按照隨機原則從第一級單位中隨機抽取若幹單位作為第一級單位樣本,再從第一級單位樣本中隨機抽取若幹單位作為第二級單位樣本,以此類推,直至獲得所需要的樣本。
(二)非隨機抽樣
在實際的調查過程中,還有一類抽樣方法,稱之為非隨機抽樣,即它不是嚴格按照隨機原則抽取樣本,而是根據調查者的主觀經驗和主觀判斷選擇樣本的。
與隨機抽樣相比,雖然這類非隨機動抽樣的代表性差,提供的資料信息較零散,難以從樣本調查的結論中對總體做出準確的推斷。但是,由於它非常簡便易行,並能通過對樣本的調查而大致瞭解總體的某些情況,對調查研究工作很有啟發性。因此,它適用於那種調查對象的總體難以具體界定,以及不需要準確推斷總體情況的調查。常用非隨機抽樣的方法主要有以下幾種:
1、偶遇抽樣
偶遇抽樣,也稱方便抽樣,是指調查者將自己在特定場合下偶然遇到的對象作為樣本的一種方法。如在商店門口、街頭路口、車站碼頭、公園廣場等公共場所,隨便選取某些顧客、行人、旅客、觀眾等作為樣本進行調查研究.這種方法比較簡單方便,適用於探索性研究,但樣本的代表性較差,具有很大的偶然性。
2、立意抽樣
立意抽樣,也稱主觀抽樣,它是調查者根據自己的主觀印象、以往的經驗和對調查對象的瞭解來選取樣本的一種方法;這種抽樣適用於那些總體範圍較小、總體單位之間的差異較大的調查。
這種主觀抽樣所抽取的樣本是否具有代表性、所得出的結論是否準確,完全取決於調查者本人的判斷能力,以及對調查對象的瞭解程度。因此這種方法具有很大的主觀隨意性。但是當對總體狀況較為熟悉時,用這一抽樣法所選擇的樣本也有較高的代表性。例如當在們對某一群體作調查時,就可以根據我們所瞭解的群體情況選取某些樣本做研究。
3、配額抽樣
配額抽樣,也稱定額抽樣,即調查者首先確定所要抽取樣本的數量,再按照一定的標準和比例分配樣本,然後從符合標準的對象中任意地抽取樣本。其方法類似於分層隨機抽樣,但它不是按照隨機原則抽取樣本。例如,我們可以根據研究目的,把總體按性別、民族等變數進行分組,然後分配相應的樣本數選取樣本。
這種配額抽樣比前兩種方法所抽取的樣本更有代表性,而且簡便易行,在民意調查中經常使用。但這種方法也具有很大的主觀隨意性和局限性,如蓋洛普採用此抽樣法曾幾次成功地預測了美國的總統大選,但在1948年總統選舉的民意調查中卻失敗了。現在,人們有時把這一方法與隨機抽樣法結合起來使用,其效果會更好些。
4、滾雪球抽樣
滾雪球抽樣,即以少量樣本為基礎,逐漸擴大樣本的規模,直至找出足夠的樣本。此法適用於對調查總體不甚清楚的情況,常用於探索性的實地研究,特別適用於對小群體關係的研究。例如我們要瞭解某個人經常交往的社會圈子,就可以通過這個人提供的線索找到更多與他有關聯的人。
其具體做法是,先找到一個或幾個符合研究目的的對象,然後再根據這些對象所提供的線索找另外相關的對象,依次進行,直至達到研究目的。但滾雪球抽樣法所選擇的樣本有時會有很大的隨意性和特殊性,因而代表性不高。
在社會科學研究過程中,抽樣是必不可少的重要環節。這就要求必須做好抽樣設計,使所選擇的樣本具有代表性。抽樣設計就是確定抽樣的原理與形式、程式和方法等。其基本原則是:第一,目的性,即根據研究目的進行抽樣設計;第二,可度量性,即根據樣本值能做出有效的估計;第三,可行性,即在實際操作中能按預定的設計完成任務;第四,經濟性,即以最小的代價去實現抽樣的目的。
(一) 抽樣的原理與形式
抽樣通常分為概率抽樣和非概率抽樣兩大類,但以概率抽樣為主。概率抽樣的基本原理首先是概率論的隨機原理,所謂隨機原理,是指抽取樣本時必須嚴格遵循一定方法和規則,使得總體中每一個對象都有相同的機會被選入樣本。這又稱為等概率抽樣。因為只有按照隨機原則進行抽樣,所抽出的樣本才有充分的代表性,也才可以對抽樣誤差做出準確的計算,以估計它的可信度。
概率抽樣的理論基礎就是概率論。我們通常把因果關係分為兩種:一種是必然性的因果關係,即若A,則必然B;另一種是隨機性的因果關係,即若A,則可能B。大量的社會現象都是隨機現象。研究隨機現象的數學分支學科是概率論。概率是事物發生的可能性大小的量度。在概率論中,把不可能發生的事件的概率稱為最小概率,定為0,而把必然發生的事件的概率稱為最大概率,定為1。那麼事件A出現的概率P(A)在0與l之間,即隨機事件發生的可能性在0到1之間,是個非負數。
(二) 抽樣的基本程式
按照一定原則進行抽樣時,大致可包括如下幾個步驟:
1、界定總體
界定總體包括明確總體的範圍、內容和時間。實際調查的總體與理論上設定的總體會有所不同,總體越複雜,二者的差別越大。例如,要研究某地青少年的犯罪狀況,理論上的總體是這一地區符合一定條件的所有的青少年,但實際上我們能夠抽樣的總體並不能全部包括,也就是說只能根據我們所能夠掌握的這一地區符合一定條件的青少年進行抽樣。因此,抽樣總體有時不等於理論上的研究總體,樣本所代表的也只是明確界定的抽樣總體。此外,由於調查研究內容的不同,對總體的限定也會有所不同。
2、確定抽樣框
這一步驟的任務就是依據已經明確界定的總體範圍,收集總體中全部抽樣單位的名單,並通過對名單進行統一編號進而組合成一種可供選擇的形式,如名單、代碼、符號等。抽樣框的形式受總體類型的影響:簡單的總體可直接根據其組成名單形成抽樣框;但對構成複雜的總體,常常根據調查研究的需要,制定不同的抽樣框,分級選擇樣本。例如,進行全國人口抽樣調查,先以全國的省市為抽樣框選部分省、市為調查單位,然後再以這些省、市中的各縣、區為抽樣框選部分縣、區為調查單位,這樣依次到村或居委會。
在概率抽樣中,抽樣框的確定非常重要,它會直接影響到樣本的代表性。因此,抽樣框要力爭全面、準確。
3、樣本設計
樣本設計包括確定樣本規模和選擇抽樣的具體方式。抽樣的目的是用樣本來代表總體,自然樣本數越大,其代表性越高。但樣本數越大,調查研究的成本也越大。因此,確定合適的樣本規模和抽樣方式是抽樣設計中的一項重要內容。我們在第三節中杵詳細討論這一問題。
4、評估樣本質量
評估樣本質量即通過對樣本統計值的分析,說明其代表性或誤差大小。對樣本代表性進行評估的主要標準是準確性和精確性:前者是指樣本的偏差,偏差越小,其準確性越高;後者是指抽樣誤差,誤差越小,其精確性或代表性越高。







{kind=link}
很不錯,剛好用上了