偏最小二乘法
出自 MBA智库百科(https://wiki.mbalib.com/)
偏最小二乘法(partial least squares method)
目錄 |
偏最小二乘法是一種新型的多元統計數據分析方法,它於1983年由伍德(S.Wold)和阿巴諾(C.Albano)等人首次提出。近幾十年來,它在理論、方法和應用方面都得到了迅速的發展。
長期以來,模型式的方法和認識性的方法之間的界限分得十分清楚。而偏最小二乘法則把它們有機的結合起來了,在一個演算法下,可以同時實現回歸建模(多元線性回歸)、數據結構簡化(主成分分析)以及兩組變數之間的相關性分析(典型相關分析)。這是多元統計數據分析中的一個飛躍。
偏最小二乘法在統計應用中的重要性體現在以下幾個方面:
偏最小二乘法是一種多因變數對多自變數的回歸建模方法。偏最小二乘法可以較好的解決許多以往用普通多元回歸無法解決的問題。
偏最小二乘法之所以被稱為第二代回歸方法,還由於它可以實現多種數據分析方法的綜合應用。
主成分回歸的主要目的是要提取隱藏在矩陣X中的相關信息,然後用於預測變數Y的值。這種做法可以保證讓我們只使用那些獨立變數,噪音將被消除,從而達到改善預測模型質量的目的。但是,主成分回歸仍然有一定的缺陷,當一些有用變數的相關性很小時,我們在選取主成分時就很容易把它們漏掉,使得最終的預測模型可靠性下降,如果我們對每一個成分進行挑選,那樣又太困難了。
偏最小二乘回歸可以解決這個問題。它採用對變數X和Y都進行分解的方法,從變數X和Y中同時提取成分(通常稱為因數),再將因數按照它們之間的相關性從大到小排列。現在,我們要建立一個模型,我們只要決定選擇幾個因數參與建模就可以了
H Wold作為PLS的創始人,在70年代的經濟學研究中引入了偏最小二乘法進行路徑分析,創建了非線性迭代偏最小二乘演算法(Nonlinear Iterative Partial Least Squares algorithm,NIPALS),至今仍然是PLS中最常用和核心的演算法。HW.old的兒子S Wold和C Albano等人在1983年提出了偏最小二乘回歸的概念,用來解決計量化學中變數存在多重共線性,解釋變數個數大於樣本量的問題,如在光譜數據分析中。上世紀90年代,出現了多種NIPALS演算法的擴展,如迭代法、特征根法、奇異值分解法等。1993年,de Jong提出了一種與NIPALS不同的演算法,稱為簡單偏最小二乘(Simple Partial Least Squares,SIMPLS)。1996年,在法國召開了偏最小二乘回歸方法的理論和應用國際學術專題研討會,就PLS的最新進展,以及PLS在計量化學、工業設計、市場分析等領域的應用進行了交流,極大的促進了PLS的演算法研究和應用研究。目前,PLS在化學、經濟學、生物醫學、社會學等領域都有很好的應用。
PLS在上世紀90年代引入中國,在經濟學、機械控制技術、藥物設計及計量化學等方面有所應用,但是在生物醫學上偏最小二乘法涉及相對較少。對該方法的各種演算法和在實際應用中的介紹也不系統,國內已有學者在這方面做了一些努力,但作為一種新興的多元統計方法,還不為人所熟知。
偏最小二乘回歸是對多元線性回歸模型的一種擴展,在其最簡單的形式中,只用一個線性模型來描述獨立變數Y與預測變數組X之間的關係:
Y = b0 + b1X1 + b2X2 + ... + bpXp
在方程中,b0是截距,bi的值是數據點1到p的回歸繫數。
例如,我們可以認為人的體重是他的身高、性別的函數,並且從各自的樣本點中估計出回歸繫數,之後,我們從測得的身高及性別中可以預測出某人的大致體重。對許多的數據分析方法來說,最大的問題莫過於準確的描述觀測數據並且對新的觀測數據作出合理的預測。
多元線性回歸模型為了處理更複雜的數據分析問題,擴展了一些其他演算法,象判別式分析,主成分回歸,相關性分析等等,都是以多元線性回歸模型為基礎的多元統計方法。這些多元統計方法有兩點重要特點,即對數據的約束性:
變數X和變數Y的因數都必須分別從X'X和Y'Y矩陣中提取,這些因數就無法同時表示變數X和Y的相關性。
預測方程的數量永遠不能多於變數Y跟變數X的數量。
偏最小二乘回歸從多元線性回歸擴展而來時卻不需要這些對數據的約束。在偏最小二乘回歸中,預測方程將由從矩陣Y'XX'Y中提取出來的因數來描述;為了更具有代表性,提取出來的預測方程的數量可能大於變數X與Y的最大數。
簡而言之,偏最小二乘回歸可能是所有多元校正方法里對變數約束最少的方法,這種靈活性讓它適用於傳統的多元校正方法所不適用的許多場合,例如一些觀測數據少於預測變數數時。並且,偏最小二乘回歸可以作為一種探索性的分析工具,在使用傳統的線性回歸模型之前,先對所需的合適的變數數進行預測並去除噪音干擾。
因此,偏最小二乘回歸被廣泛用於許多領域來進行建模,象化學,經濟學,醫葯,心理學和製藥科學等等,尤其是它可以根據需要而任意設置變數這個優點更加突出。在化學計量學上,偏最小二乘回歸已作為一種標準的多元建模工具。
作為一個多元線性回歸方法,偏最小二乘回歸的主要目的是要建立一個線性模型:Y=XB+E,其中Y是具有m個變數、n個樣本點的響應矩陣,X是具有p個變數、n個樣本點的預測矩陣,B是回歸繫數矩陣,E為噪音校正模型,與Y具有相同的維數。在通常情況下,變數X和Y被標準化後再用於計算,即減去它們的平均值並除以標準偏差。
偏最小二乘回歸和主成分回歸一樣,都採用得分因數作為原始預測變數線性組合的依據,所以用於建立預測模型的得分因數之間必須線性無關。例如:假如我們現在有一組響應變數Y(矩陣形式)和大量的預測變數X(矩陣形式),其中有些變數嚴重線性相關,我們使用提取因數的方法從這組數據中提取因數,用於計算得分因數矩陣:T=XW,最後再求出合適的權重矩陣W,並建立線性回歸模型:Y=TQ+E,其中Q是矩陣T的回歸繫數矩陣,E為誤差矩陣。一旦Q計算出來後,前面的方程就等價於Y=XB+E,其中B=WQ,它可直接作為預測回歸模型。
偏最小二乘回歸與主成分回歸的不同之處在於得分因數的提取方法不同,簡而言之,主成分回歸產生的權重矩陣W反映的是預測變數X之間的協方差,偏最小二乘回歸產生的權重矩陣W反映的是預測變數X與響應變數Y之間的協方差。
在建模當中,偏最小二乘回歸產生了pxc的權重矩陣W,矩陣W的列向量用於計算變數X的列向量的nxc的得分矩陣T。不斷的計算這些權重使得響應與其相應的得分因數之間的協方差達到最大。普通最小二乘回歸在計算Y在T上的回歸時產生矩陣Q,即矩陣Y的載荷因數(或稱權重),用於建立回歸方程:Y=TQ+E。一旦計算出Q,我們就可以得出方程:Y=XB+E,其中B=WQ,最終的預測模型也就建立起來了。
案例一:偏最小二乘法在顧客滿意度評價中的運用[1]
一、顧客滿意度指數含義及研究意義
所謂顧客滿意度,是指顧客通過對一個產品或服務的感知效果/結果與其期望值相比較後所形成的愉悅或失望的感覺狀態,即是消費者對商品、品牌或企業的滿意程度。顧客滿意度理論是2O世紀九十年代管理科學的最新發展之一,它抓住了管理科學“以人為本”的本質。在市場經濟高度發達的今天。任何一個企業能否以市場為中心,以顧客為中心,讓顧客滿意,決定著該企業能否在市場上立足,決定著企業所占市場份額的大小。因而,對顧客滿意度的研究對企業來說十分重要,有著現實的指導意義。
二、顧客滿意度指數模型及偏最小二乘法操作原理
對顧客滿意度指數模型的研究最早起於瑞典,發展於美國。瑞典率先於1989年建立了全國性的顧客滿意度指數,美國和歐盟相繼建立了各自的顧客滿意度指數——美國顧滿意度指數(ACSI)和歐洲顧客滿意度指數(ECSI)。另外。紐西蘭、加拿大和臺灣等國家和地區也在幾個重要的行業建立了顧客滿意度指數。在這些模型中幾乎都涉及顧客期望、感知質量、顧客滿意度、顧客抱怨和顧客忠誠度這些指標(圖)。

然而,在現實的操作中,這些都是定性指標,很難進行衡量,而且還有一些隱變數也不易觀測,這些問題為建立顧客滿意度模型帶來了困難。但是。偏最小二乘法(PLS)能剋服這些問題,得到比較好的估計效果。偏最小二乘法類似於主成分回歸的方式剋服多重共線性的問題。它是將主成分分析與多元回歸結合起來的疊代估計。是一種因果建模的方法。瑞典、美國和歐盟模型都使用這種方法進行估計。在ACSI模型估計中,該方法對不同隱變數的測量變數子集抽取主成分,放在回歸模型系統中使用,然後調整主成分權數,以最大化模型的預測能力。
三、偏最小二乘法在顧客滿意度指數中的運用
對於包含隱變數的結構方程模型,目前最經常使用的估計方法是PLS方法和LISP,EL方法。
設在顧客滿意度測評中有q個因變數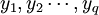 和P個自變數
和P個自變數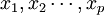 。為了研究因變數和自變數之間的統計關係,我們觀察了n個樣本點,由此構造了自變數和因變數的數據表:
。為了研究因變數和自變數之間的統計關係,我們觀察了n個樣本點,由此構造了自變數和因變數的數據表:
![X=[x_1,x_2L,x_p]_{nxp}=\begin{cases}X_{11} X_{12} L X_{1p}\\X_{21} X_{22} L X_{2p}\\L L L L\\X_{n1} X_{n2} L X_{np}\end{cases}](/w/images/math/d/a/0/da0984285ba7aa375da1154361435b86.png)
![Y=[y_1,y_2L,y_p]_{nxp}=\begin{cases}y_{11} y_{12} L y_{1p}\\y_{21} y_{22} L y_{2p}\\L L L L\\y_{n1} y_{n2} L y_{np}\end{cases}](/w/images/math/a/6/8/a686da36b7c2947c96acb86ae309b454.png)
偏最小二乘法回歸的做法是首先在自變數集中提取第一潛因數t1(t1是 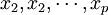 的線性組合,且儘可能多地提取原自變數集中的變異信息,比如第一主分量);同時,在因變數集中也提取第一潛因u1(u1為
的線性組合,且儘可能多地提取原自變數集中的變異信息,比如第一主分量);同時,在因變數集中也提取第一潛因u1(u1為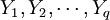 的線性組合),並要求t1和u1相關程度達到最大。然後建立因變數Y與t1的回歸,如果回歸方程已達到滿意的精度,則演算法終止。否則繼續進行第二輪潛在因數的提取,直到能達到滿意的精度為止。若最終對自變數集提取1個潛因數
的線性組合),並要求t1和u1相關程度達到最大。然後建立因變數Y與t1的回歸,如果回歸方程已達到滿意的精度,則演算法終止。否則繼續進行第二輪潛在因數的提取,直到能達到滿意的精度為止。若最終對自變數集提取1個潛因數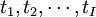 的回歸式,然後再表示為Y與原自變數的回歸方程式。
的回歸式,然後再表示為Y與原自變數的回歸方程式。
PLS的演算法步驟如下:
1、把自變數和因變數都進行標準化處理,以消除測量時由於採用不同的量綱和數量級所引起的差異。標準化處理的公式是:
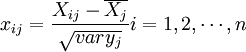 ;
;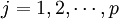
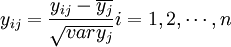 ;
;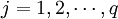
X經標準化處理後的數據矩陣記為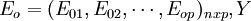 經標準化處理後數據矩陣為
經標準化處理後數據矩陣為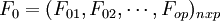 。
。
2、提取主成分,逐步回歸法。記t1是Eo的第一個成分。t1 = E0w1,w1是E0的第一個軸。它是一個單位向量,即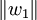 ;u1是F0的第一個成分,u1 = Foc1,c1是F0的第一個軸,它是一個單位向量,即
;u1是F0的第一個成分,u1 = Foc1,c1是F0的第一個軸,它是一個單位向量,即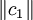 。
。
在建立顧客滿意度指數建模時,要求t1和u1能很好地分別代表自變數x和因變數Y中的數據變異信息,根據主成分分析原理應該有: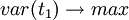
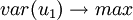
而另一方面,在顧客滿意度指數建模時,又要求t1對u1具有最大的解釋能力,由典型相關分析思路,t1和u1的相關程度應達到最大值,即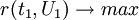 。實質上是要求t1,u1的協方差達到最大。
。實質上是要求t1,u1的協方差達到最大。
因此,顧客滿意度指數測評模型的偏最小二乘回歸的正規數學表達式為求下列優化問題.即 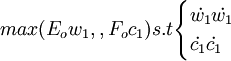 第一步,從X中提取第一主成分t_1(t_1為向量),提取的原則是t_1與Y之間的協方差達到最大,即求矩陣
第一步,從X中提取第一主成分t_1(t_1為向量),提取的原則是t_1與Y之間的協方差達到最大,即求矩陣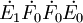 的最大特征值所對應的特征向量w1,然後求成分t1和殘差矩陣E1,其計算公式如下:
的最大特征值所對應的特征向量w1,然後求成分t1和殘差矩陣E1,其計算公式如下: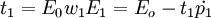 式中
式中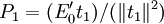 ;第二步,求矩陣
;第二步,求矩陣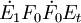 的最大特征值所對應的特征向量w2,然後求成分t2和殘差矩陣E2,其計算公式:
的最大特征值所對應的特征向量w2,然後求成分t2和殘差矩陣E2,其計算公式:
t2 = E1w2
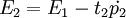 式中
式中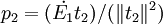
……
第m步,重覆以上步驟,求成分tm = Em − 1wm,這裡wm是矩陣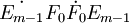 的最大特征值所對應的特征向量,直到提取的主成分t_m對模型預測效果的邊際貢獻不顯著為止。
的最大特征值所對應的特征向量,直到提取的主成分t_m對模型預測效果的邊際貢獻不顯著為止。
如果根據交叉有效性,確定共抽取m個成分t1,t2,L,tm可以得到一個滿意的預測模型,則求F0在t1,t2,L,tm上的普通最小二乘回歸方程為。
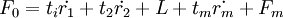
最後,將還原成為Y * 關於x * = Eoj的回歸方程形式,即,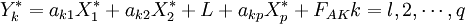
就得到了顧客滿意度指數測評模型。
運用偏最小二乘法對顧客滿意度指數進行估計和評析,能較好地估計出顧客滿意度測評模型,從而幫助企業發現企業運行中的薄弱環節,對複雜多變的市場瞭如指掌,推動企業經營體制和機制的改革,幫助企業制定正確的發展戰略和市場政策。
- ↑ 薛艷.偏最小二乘法在顧客滿意度評價中的運用[J].合作經濟與科技,2006,(7)

評論(共12條)
舉幾個實例分析分析,讓我們學的人更明白,謝謝
增加了新的案例和新的內容,希望對您有幫助!
不要列出具體的數學演算法,很多MBA學生對那個不敢興趣。只簡單說說1.什麼情況下用偏最小二乘法,而不用其他方法,比如SEM,2.偏最小二乘法與最大似然估計是什麼關係,區別何在,3.用什麼軟體能做出最小二乘法,軟體間差異如何。等等。這些問題可能對學生幫助更大。
不要列出具體的數學演算法,很多MBA學生對那個不敢興趣。只簡單說說1.什麼情況下用偏最小二乘法,而不用其他方法,比如SEM,2.偏最小二乘法與最大似然估計是什麼關係,區別何在,3.用什麼軟體能做出最小二乘法,軟體間差異如何。等等。這些問題可能對學生幫助更大。
難怪各種預測模型被很多MBA學生濫用的一塌糊塗,就是因為連具體的演算法都不明白,只會拿來就用,也不管用的對不對
難怪各種預測模型被很多MBA學生濫用的一塌糊塗,就是因為連具體的演算法都不明白,只會拿來就用,也不管用的對不對
樓上說得好
難怪各種預測模型被很多MBA學生濫用的一塌糊塗,就是因為連具體的演算法都不明白,只會拿來就用,也不管用的對不對
同意






非常好,我要下載