元分析
出自 MBA智库百科(https://wiki.mbalib.com/)
元分析(Meta-Analysis)
目錄 |
元分析是一種定量分析手段。它運用一些測量和統計分析技術,總結和評價已有的研究。元分析過程中,最重要的是判定研究結果,即對研究結果進行統計顯著性水平檢驗和效果量的測定。
元分析的特點[1]
第一次使用“元分析”這個概念的人是美國學者格拉斯,他在1976年美國教育研究聯合會(American Education Research Association)的發言致辭中首次提出元分析概念。格拉斯認為,元分析是一種對分析的分析,具有以下主要特點:
(1)元分析是一種定量分析方法,它不是對原始數據的統計,而是對統計結果的再統計;
(2)元分析應該包含不同質量的研究;
(3)元分析尋求一個綜合的結論。
元分析的缺點[2]
元分析可以成為跨研究評判結果的一件有力工具。即使許多研究者已經樂意接受元分析的概念了,可還有一些人基於若幹理由而質疑它的有用性。本節探討元分析的一些缺點,併為剋服這些缺點而提出一些建設性的解決方法。
評估被評論的研究的質量 在一家期刊里可見的研究之質量取決於期刊的編輯政策。有些期刊有嚴格的發表標準,而另一些的發表標準就不太嚴格。這就意味著發表的研究之質量在不同的期刊間會有很大差別。
元分析面臨的一個問題是如何處理參差不齊的研究質量。例如,在一家非同儕評審的期刊上發表的文章應該與在一家需同儕評審的期刊上發表的文章一視同仁嗎?遺憾的是對這個問題沒有簡單的答案。Rosenthal(1984)建議按照質量來對文章加權。
應該沿什麼維度來對研究加權呢?這毫無一致意見。需一非同儕評審的維度雖然是可以的,但是你採用這個維度時也要當心,因為一家期刊是不是同儕評審的,這並不是發表的研究之質量的可靠指標。在一個新的領域里用新方法做的研究有時會被同儕評審的期刊拒絕,儘管這家期刊在方法學上是健全的,也是高質量的。類似地,在同儕評審的期刊發表的作品雖然有助於你確信該研究的質量是高的,但不保證高質量。
可以依著而對研究加權的第二個維度是方法學上的健全性,而不考慮期刊的質量。Rosenthal(1984)提出讓若幹方法學專家對每項研究打質量分(可以用一個從0到l0的量表)。質量評定可以做兩次:一次在單獨讀了方法部分之後;另一次是在讀了方法和結果兩部分之後(Rosenthal,1984)。這樣的評定是要檢查評分者間信度的,然後才用來在元分析里對每一項研究的貢獻大小進行加權。
用不同的方法合併與比較研究 對元分析的常見批評是難以理解怎麼可能對材料、量器以及方法都廣泛不同的諸研究做比較。這個問題通稱為“蘋果與桔子之爭”(Glass,1978)。
對元分析的這種批評雖常見,卻無效。Rosenthal(1984)和Glass(1978)指出,比較不同的研究結果與在一個普通實驗里對異質被試作平均化是毫無不同的。如果你願意接受對被試作平均化,那也就能接受對異質研究作平均化(Glass,1978;Rosenthal,1984)。
關鍵問題不是應不應該在異質研究之間做平均,而毋寧說是不同的研究方法會不會帶來不同的效應規模。因此Rosenthal指出,當某一被試變數成了研究中的一個問題時,你經常會“膠著”在這個被試變數上以確定它是如何與出現的差異相關聯的。同樣的,如果方法學的差異顯得與研究結果有關聯,那麼在一項元分析里,研究也要停下來考察方法學(Rosenthal,1984)。
實際問題 元分析的工作是一項艱巨的工作。對同一問題做實驗,可以使用很不同的方法與統計技術。還有,某些研究也許沒有提供必要的信息可做元分析。例如Roberts(1985)只能用38項研究來做他的態度一記憶關係的元分析。有些研究因為沒提供足夠的信息,所以得剔除掉。Robert也報告說,當一篇文章說F值小於1(文章里經常這樣做)時,他就對F賦值以零。信息不足或不准確的問題(與文件櫃問題相伴)會導致你的元分析里的研究樣本沒有代表性。誠然,偏差也許是小的,卻也是存在的。
元分析的結果不同於傳統述評的結果嗎? 傳統的述評產生的結果是不是與元分析的結果有質的不同?這的確是個問題。為回答這個問題,Cooper和Rosenthal(1980)直接比較了這兩種方法。他們把研究生和教授隨機分配於做元分析或做傳統述評,材料是7篇文章,講述被試性別對作業堅持性的影響。其中兩篇研究認為女性比男性更有堅持性,而另5篇要麼沒有統計數據,要麼顯示沒有顯著效應。
這一研究的結果顯示了使用元分析的參與者比使用傳統方法的參與者更有可能得出性別對堅持性有影響的結論。另外,比之於做元分析的參與者,做傳統述評的參與者認為性別對堅持性的影響小。總起來看,使用元分析的參與者有68%願意斷言性別對堅持性有影響,而只有27%使用傳統方法的參與者有此傾向。用統計學的話來說,做元分析者比傳統述評者更願意拒絕性別無影響的虛無假設。因此使用元分析來評判研究會導致Ⅱ型決策錯誤的降低。(Cooper&Rosenthal,1980)。
Cooper&Rosenthal(1980)也報告說,元分析樣組與傳統述評樣組在評判被述評研究的方法學上沒有能力差別。還有,兩個樣組在對該領域的未來研究提出的建議方面也無差別。大部分的參與者認為該領域的研究應該繼續下去。
最後,值得註意的是,使用元分析本身要求的統計學進路與對傳統實驗數據做統計分析的研究策略是一樣的。當我們得到一個實驗的結果時,我們不會只打量(“盯著”)數據,看看是否存在什麼模式或關係。相反,在大多數情況下,我們用統計分析來評判關係是否存在。同樣的,與其“盯著”諸研究而猜測可能的關係,還不如把一項統計分析應用於不同研究的結果,以見是否存在有意義的關係,這會更好。
元分析的步驟[1]
元分析要具有可複製性,不僅應儘可能多地檢驗搜集來的研究樣本,觀察它們是否可以凸顯出某種單項研究顯現不出的潛藏規律,還應該清楚地描述自己是如何發現這些研究及如何對它們作分析的,以便他人進行評價。因此,元分析必須遵循詳盡、嚴格的研究步驟。
1.確定研究目的
確定研究目的也就是組織研究框架。在收集研究之前,首先必須確定研究中想要探索的文獻領域及將要包括的題目範圍。元分析涵蓋的題目有時很寬泛,但其核心必須界定清楚,而且應該建立一套挑選研究樣本的“包含”與“排除”標準,這樣可以幫助一起合作的研究者在面對同一群文獻時能夠運用同樣的標準去查找或分析研究。
確定研究目的時,還需要充分理解自己所要分析的概念及使用的方法,就像確定實驗研究中的自變數和因變數一樣,確定所要研究的效果量及結果。
2.徹底的文獻搜索
通過包括電腦網路在內的各種手段進行徹底的文獻搜索,也就是研究樣本的搜索,這對元分析的有效性非常重要,是綜合研究得出結論的基礎。對文獻樣本的收集可根據Rosenthal(1984)提出的大概分類標準:
書:包括作者的原著、幾位作者共同合編的書及書的某些章節;
期刊:包括專業期刊、已出版發表的時事通訊、雜誌及報紙;
論文:包括博士論文、碩士論文及學士論文;
未發表的研究:包括某些技術報告、學術報告、大會論文及將要發表的論文。
3.確定適合的研究樣本
選擇符合研究框架的研究樣本是元分析的關鍵。要考慮多種問題,如它的研究設計,文章發表的時間,文章使用何種語言表述,研究中的樣本大小及信息是否完整等等。
一般而言,儘可能選擇最新的研究。對於未被選中的資料在分析中也要說明,這樣就可以清楚明瞭地表明這些研究曾經發表過,並非經過一段時間將它們遺漏,只是沒有作為設計的一部分包括進研究內。同時如果在研究中僅選擇了以母語或英語表述的文章,就要說明這樣做的理由。
另外,如果看到某一類研究在相似的題目上有多重報告,那麼就選擇其中一個信息較為完整的研究,使同一類型研究中的信息對元分析只貢獻一次。儘量排除小樣本的研究。如果選擇了縱向跟蹤研究,則要儘早決定跟蹤研究的時限。
4.定義變數及對變數編碼
在收集、選擇了元分析的文獻後,必須確定在元分析中要檢驗何種研究特征,這些特征就是元分析的變數。一般有以下四種變數:(1)識別背景特征的變數。這類變數包括入選研究樣本的數量,研究樣本的參考文獻,對研究編碼的人數(一般要求至少兩人以上),研究資料的來源等。(2)識別樣本特征的變數。這類變數包括被試的特征,如性別、年齡、民族、受教育水平、社會經濟狀況等。(3)識別研究特征的變數。這類變數包括研究的理論架構,研究設計,研究採用的工具,研究測量的效應類型以及其他。如果可能,這類變數可以幫助解釋研究方法與結果之間的關係。(4)識別統計特征的變數。這類變數包括兩類統計值,一個是表現平均值差異的效果量d,這需要關註每一個研究中的平均數、標準差和樣本大小。另一個是表現關係的相關係數r,這需要關註每一個研究中的相關係數及相關的測量統計值。
在界定了用來測量研究的變數之後,還需要為每一個變數編碼數據。對於每一個元分析而言,都應該有一套界定好的數據編碼系統,不同的數字代表了每一類變數中不同的水平情況。如關於性別,若樣本中僅有男性,編碼系統可將其編碼為1,若樣本中僅有女性,則可編碼為2,若既有男性又有女性,則可編碼為3,如果樣本未對性別作明確說明,則可用999(缺失值)進行編碼。研究者需要對所有的分析變數進行編碼。
5.研究數據的錄入
元分析中搜集來的有關各樣本研究特征的數據,需要錄入一個相關的統計軟體包進行分析。“元統計”軟體包是由Rudner、Evartt和Emery規劃設計的,其中包含有Glass、Hedges、Olkin、Schmidt和Hunter及其他學者的大量元分析理論,如Hedges的同質性檢驗,Rosenthal和Rubin的聚合顯著性水平分析,以及近似隨機化檢驗及效果量大小計算等等。該軟體包還可以提供大量的程式來幫助完成數據錄入、統計分析和圖表分析,數據錄入的形式既可以依據標準碼的形式也可以依據SPSS的固定格式。
6.運用多種統計技術探索、展現數據
在進行複雜的元分析之前,應先對一些基礎的數據特征進行分析,特別是錄入數據後最好做一個簡單頻次分佈圖與散點圖,來觀察數據錄入是否合理或者在所有欲分析的研究中是否有非常明顯的異常數據存在。如果有,則可用軟體包中提供的相應處理異常數據的方法來儘早地修正或遠離它們。對於具體採用哪些元分析技術,要根據研究目的來決定。一般地,需要計算各研究樣本的效果量及總效果量的大小,計算對總效果量估計的置信區間以及對各研究樣本的同質性檢驗。面對不同質的樣本要做敏感性分析,即根據研究質量的評定對研究樣本分層,可劃分為兩層或多層,然後對每一層分別進行分析,同時對比其結果。
元分析效果量的計算[1]
效果量的指標一般包括兩類,一類用d表示,一類用r表示,即Pearson積差相關係數。在一些相關研究中,研究結果一般都會提供r,因此獲取這一效果量比較方便。1985年Hedges和Olkin還提供了r和d這兩個指標間的相互轉換公式,即: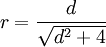 。
。
(一)樣本效果量
在元分析中,要對許多實驗研究的結果進行定量綜合,首先應計算出每一研究結果的效果量d,它是元分析中的重要指標,而且與傳統統計分析方法中虛無假設的顯著性檢驗(如:t、z、F檢驗等)有一定的聯繫。計算效果量是為了觀察大批研究中所有效應的分佈,如某種結論趨勢或形態的確存在,效果量則會集中於一個方向。
第一步:計算效果量d
效果量d的計算公式為: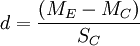 ,即實驗組與控制組的平均數之差再除以控制組計算出的標準差所得的值。如果研究中沒有均數和標準差,但提供了t值、z值或F值等顯著性檢驗參數時,也可通過轉換公式求出d值。
,即實驗組與控制組的平均數之差再除以控制組計算出的標準差所得的值。如果研究中沒有均數和標準差,但提供了t值、z值或F值等顯著性檢驗參數時,也可通過轉換公式求出d值。
第二步:計算效應平均值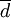
有了各研究結果的效果量d,還須計算綜合條件下抽樣樣本效果大小的平均值萬,但考慮到從各研究中所得效果量的精度不同,故可用每項研究的樣本容量作為權數,求出它的加權平均數。Hedge在1982年提出的平均效果量無偏估計的方法,他認為當實驗組和控制組的樣本容量大於10,效果量小於115時,該加權方法非常有效和精確: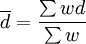 ,其中是指加權後的效果量,w是指元分析中每項研究的權重,其計算公式為:
,其中是指加權後的效果量,w是指元分析中每項研究的權重,其計算公式為:
 ,其中N指各研究樣本的樣本容量。
,其中N指各研究樣本的樣本容量。
在評定平均效果量d時,Cohen(1992)認為小於0.20的效果量太小,大於0.80的效果量太大,所以應該考慮中等的效果量,如0.50左右。
第三步,總體效果量大小的估計得出抽樣樣本效果量大小的平均值後,還需要以樣本效果大小的平均值來估計總體效果量的大小。中國學者朱瑩和郭春彥研究發現,在以抽樣樣本效果大小的平均值作為總體效果大小的估計值時,抽樣樣本的數量和樣本的容量都會對樣本效果量大小產生影響,而其中抽樣樣本的數量影響更大一些,所以理想的條件是樣本容量在70以上,且抽樣樣本數目在30以上進行元分析,結果會是準確、可靠和一致的,如果抽樣樣本數目在50以上,其結果將更為理想。
(二)效果量的齊性檢驗(homogeneity of effectsize)
齊性檢驗又稱抽樣樣本效果大小的一致性分析,它是指所抽取的樣本效果大小是否來自共同的總體,因而可以看作是效果量之間的同質性檢驗。齊性檢驗告訴我們,不是所有的研究結果都能被綜合進同一元分析中,如果研究結果不齊性,調查者應考慮是否是由隨機抽樣誤差所致,如果不是,則應該考慮將這些研究結果分成不同的子集合,使這些集合之間呈齊性關係,再對它們分別進行元分析。一般可採用聚類分析、方差分析、相關分析及回歸分析等統計分析方法來探查研究特征與研究結果之間的關係。
Rosenthal和Rubin(1982)曾提出效果量齊性檢驗的方法: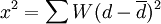 ,其中指加權後的效應均值,d指每項研究結果的效果量,叫指每個效果量的權重。該x2值的自由度為k-1,k是指總抽樣樣本的數量。
,其中指加權後的效應均值,d指每項研究結果的效果量,叫指每個效果量的權重。該x2值的自由度為k-1,k是指總抽樣樣本的數量。







{kind=link}
啦啦上官嫻