信用组合观点模型
出自 MBA智库百科(https://wiki.mbalib.com/)
信用组合观点模型(Credit Portfolio View,CPV)
目录 |
什么是信用组合观点模型[1]
信用组合观点模型是由麦肯锡公司应用计量经济学理论和蒙特·卡罗模拟法于1998年开发出的一个多因素信用风险量化模型,它主要用于信贷组合风险的分析。
信用组合观点模型的基本原理及框架[2]
信用组合观点(Credit Portfolio View)模型是由麦肯锡(Mckinsey)开发的一个多因子模型,可以用于模拟既定宏观因素取值下各个信用等级对象之间联合条件违约分布和信用转移概率。在观测到失业率、GDP增长率、长期利率水平、外汇水平、政府支出和国民储蓄率等宏观经济因子信息时,计算不同国家、不同行业、不同信用评级的违约和信用潜移概率的分布函数。此模型假定每个债券的信用评级对整体的信用周期更敏感。
Credit Portfolio View将观测到的违约概率和信用潜移概率与宏观经济因素联系起来。当经济处于衰退期时,各信用主体信用降级和违约概率增加;与此相反,当经济处于繁荣时期时,各信用主体信用降级和违约概率减少。也就是说信用周期与经济周期密切相关。假定能够得到相关的数据,这一框架可以应用到每一个国家,并可用到像制造业、金融业和农业等不同的部门和各种类型的信用个体。
1.违约预测模型
违约概率为一个Logit函数,其变量为一些宏观经济变量的当前值或滞后值构造的综合评级指数,可表示为: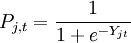 (1)
(1)其中,Pj,t表示国家或行业j中债券在时期t的条件违约概率,Yj,t表示由宏观经济变量构造的评级指数。注意上述Logit变换保证了计算得到的违约概率处于0与1之间。
某一时期一个国家经济状况的宏观经济指数Yj,t可用下述的多因子模型来表示: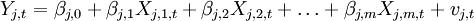 (2)
(2) 其中,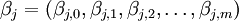 为第j个国家、产业或级别的参数;
为第j个国家、产业或级别的参数;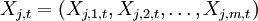 为时期t第j个国家或行业的宏观经济变量;vj,t表示与宏观经济向量Xj,t独立的残差变量,并假设服从正态分布:vj,t—N(O,σj),和vt—N(O,∑v),这里,vt表示残差变量vj,t的向量形式,∑v表示j×j的方差协方差矩阵。
为时期t第j个国家或行业的宏观经济变量;vj,t表示与宏观经济向量Xj,t独立的残差变量,并假设服从正态分布:vj,t—N(O,σj),和vt—N(O,∑v),这里,vt表示残差变量vj,t的向量形式,∑v表示j×j的方差协方差矩阵。
对每一个国家来说,宏观经济变量都是给定的。如果能够得到足够的数据,上述模型就可以在国家或产业的水平上进行计算,从而就可以估计出相应的违约概率Pj,t、违约概率指数Yj,t和相应的参数βj。
实际估计时,一般假设宏观经济变量服从2阶自回归(AR2)过程:其中,Xj,i,t − 1,rj,i,2Xj,i,t − 2表示宏观经济变量Xj,t的一阶和二阶的滞后项;rj = (rj,i,0,rj,i,1,rj,i,2)表示需要估计的参数;ej,i,t表示独立同分布的残差项;ej,i,t-N(O,σej,i,t)和et-N(O,∑e)。其中,et表示残差ej,i,t的向量形式,∑e为(j×i)(j×i)的方差协方差矩阵。
为了计算违约概率,需要考虑下面的几个方程(4): 其中残差的向量Et表示为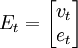 -N(O,
-N(O,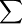 ),这里
),这里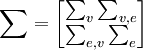 ,∑v,e和∑e,v表示交叉的协方差阵。
,∑v,e和∑e,v表示交叉的协方差阵。
在计算了(4)的几个方程后,可以通过以下步骤来计算违约概率:
第一步:对协方差矩阵∑进行Cholesky分解,即:∑=AA’ (5)
第二步:产生标准正态分布的随机向量Zt-N(0,I),然后计算Et=A’Zt,所得的结果就是vj,t和ej,i,t,代入(4)的估计值就得到了Yj,t和Pj,t。
2.条件转移矩阵
为了推导条件信用转移矩阵,我们使用根据穆迪(Moody)公司或标准普尔(Standard & Poor)公司的历史数据计算的信用等级转移矩阵(无条件的马尔可夫转移矩阵),记做币M。之所以称为无条件转移概率,因为它们是基于20年、跨越好几个经济周期和产业的数据之上推导的历史平均数。
非投资级的债务人在经济衰退时期的违约概率平均较高,此时信用降级的概率下降,信用升级的概率上升,在经济扩张时期,与此相反,即(6):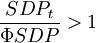 经济衰退时
经济衰退时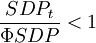 经济繁荣时时,增加了债券信用降级和违约的概率;当经济繁荣,时,降低了债券信用降级和违约的概率。因为可以计算出任何经济时期的转移概率矩阵,那么也就可以得到多期的转移矩阵:
经济繁荣时时,增加了债券信用降级和违约的概率;当经济繁荣,时,降低了债券信用降级和违约的概率。因为可以计算出任何经济时期的转移概率矩阵,那么也就可以得到多期的转移矩阵: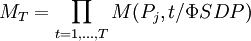 (8)
(8)对上式模拟很多次,就能得到任何时期,任何评级的条件违约概率的分布。
KMV和Credit Portfolio View都假设违约和转移概率是随时间变化的。KMV模型是利用微观经济的方法将债券的违约概率和资产的市场价值结合起来。Credit Portfolio View则是利用宏观经济的框架将宏观经济因子和违约概率、信用转移概率结合起来,它需要每一个国家每一个部门的某些数据。上述模型的一个缺点是对于转移概率的调整带有一定的任意性。上述两种方法也有一定的联系,因为公司资产的价值依赖于经济的状况。
信用组合观点模型的优缺点[3]
信用组合观点模型主要适用于投机级债务人,而不太适合于投资级债务人。因为投资级债务人的违约率相对稳定,而投机级债务人的违约率会受周期性宏观经济因素的影响而剧烈变动,所以要根据宏观经济状况适时调整违约概率及其对应的信用等级转移矩阵。
信用组合观点模型将宏观经济状况纳入模型中,用于模拟信用事件的信用风险,其优点是显而易见的。但同时,该模型也存在着一些局限性。
(1)该法要求每个国家、甚至每个国家内的每个产业部门都要有完备可靠的违约数据,这显然是很难实现,退一步来说,即使能够实现,但如果模型中所包含的行业越多,关于违约事件的信息就会相对变得越少,这也将不利于条件违约概率的确定,并影响模型的应用效果。
(2)模型没有考虑诸如债务的剩余期限及其对债务偿还情况等微观经济因素的影响,而是完全依赖宏观经济因素来决定信用等级转移概率,这有点过于武断和片面。
(3)模型对企业信用等级变化所进行的调整,容易受银行在信贷方面积累的经验和对信贷周期的主观认识等人为因素的影响,从而有可能降低调整后模型的客观性、可信性。
(4)模型有可能受到调整信用等级转移矩阵的特定程序的限制,而且也无法判定在实践中是否一定比简单的贝叶斯模型表现更好。
CPV模型与其他信用风险量化模型比较[4]
1.现代信用风险内部度量模型
银行内部信用风险度量的依据是对借款人和具体交易类型风险特征进行评估并以此确定银行可能遭受的损失,进而估计经济资本。
CreditMetricsTM是银行业最早使用并且对外公开的信用风险管理模型,是由J.P.摩根银行(JPM)和一些合作机构1997年推出的信用度量术。基础是资产组合理论,旨在使信用按市值定价。着眼于流动性非常好的债券市场或债券衍生品市场,因此可以轻易收集广泛的价格和评级数据。它对贷款和债券在给定的时间单位内(通常为1年)的未来价值变化分布进行估计,并通过在险价值(Value at Risk,VaR)来衡量风险。这里VaR用来衡量投资组合风险敞口的程度,是指在正常的市场情况和一定的置信水平下,在给定的时间段内预期可能发生的最大损失。
KMV是美国一家开发和出售信用分析软件以及其他金融信息产品的专业公司,模型因公司而得名。KMV模型的理论基础是Black-Scholes,Merton以及Hull和White的期权定价理论。该模型认为信用风险产生的动因是发行者的资产价值的变化。
从期权与公司资产价值的角度来看,公司的股东持有一份以公司债务为执行价格,以公司资产为标的物的看涨期权。当资产大于负债时,股东则行使该看涨期权,即偿还债务,继续拥有公司;如果资产小于负债,公司破产,公司所有者将公司资产出售给债权的持有人,即债权人拥有公司。所以企业破产的概率由企业的资产和负债共同决定。Merton模型把杠杆企业中的股权看作是一个以企业资产为标的,总负债账面价值为执行价格的看涨期权。如果贷款到期时企业市场价值高于其债务,企业有动力还款;当企业价值小于其债务时,企业有违约的选择权。因此,企业的股权价值可以用Black-Scholes期权定价模型来定价。
CreditRisk + 是由瑞士信贷第一波士顿银行(CSFB)于1996年在保险精算的基础上开发的信贷风险管理系统。它假定违约率是随机的,可以在信用周期内显著地波动,并且其本身是风险的驱动因素驯。
因而,CreditRisk + 被认为是一种“违约率模型”的代表。与CreditMetricsTM和KMV都以资产价值作为风险驱动因素不同,它只考虑了违约风险,而没有对违约的成因做出任何假设:一个债务人或者以概率PA违约,或者以1一PA的概率没有违约。它假定:(1)对于一笔贷款,在给定期间内的违约概率与其他任何期间的违约概率相同;(2)对于大量的债务人,任何特定债务人的违约概率很小,且在某一特定时期内的违约数与任何其他时期内的违约数相互独立。
1998年McKinsey公司提出的CreditPonfolioViewTM模型(以下称CPV模型)是一个用于分析贷款组合风险和收益的多因素模型,它根据诸如失业率、GDP增长率、长期利率水平、政府支出等宏观因素,运用经济计量学和蒙特卡罗技术来对每个国家不同行业中不同等级的违约和转移概率的联合条件分布进行模拟。与CreditMetricsTM应用的转移概率和违约率不同,CPV模型不是以历史等级转移和违约的数据来估计,而是以当期的经济状态为条件来计算债务人的等级转移概率和违约率。模型中的违约概率和转移概率都与宏观经济状况紧密相联。当经济状况恶化时,降级和违约增加;反之,则减少。
2.现代信用风险度量模型的比较
CreditMetricsTM,KMV,CreditRisk + 和CPV模型4种方法是当今国际上最具代表性的现代信用风险量化模型。它们建立的基础和对风险评估的重点都有所不同,为了更好的进行分析,特从以下3个方面进行比较。
2.1信用损失的定义及驱动因素
根据模型对信用损失的不同定义,可以将模型分为两类:以贷款的市场价值变化为基础的模型称为盯市模型(Mark-to-Market Model),集中于预测违约损失的风险机制的模型称为违约模型(Default Model)。盯市模型在计算贷款价值的损失和收益中既考虑了违约因素,同时也考虑了贷款信用等级上升或者下降以及由此发生的信用价差变化等因素。违约模型只考虑两种状态,即违约或者不违约。盯市模型和违约模型之间的关键差异是盯市模型包括了价差风险。在以上的4个模型中,KMV模型和CreditMetricsTM模型明显是盯市模型,CreditRisk + 模型则是违约模型,而CPV模型既可以当作盯市模型也可以当作违约模型。
这些模型的关键风险驱动因素似乎不大相同,CreditMetricsTM模型和KMV模型是以MeHon模型为分析基础,企业的资产价值和资产价值的波动性是违约风险的关键性驱动因素。在CPV模型观点中,信用风险驱动因素是一些宏观因素。在CreditRisk + 模型中,信用风险的驱动因素则是违约率及其波动性。然而,如果从多因素角度来考虑,4种模型都可以看作有着类似的根源。
CPV模型中风险驱动因素有着与CreditMetricsTM模型和KMV模型在本质上的相似之处。特别是,一套系统的“国家范围的”宏观因素和非系统的宏观冲击驱动着违约风险和借款人之间的违约风险的相关性。在CreditRisk + 模型中,关键的信用风险驱动因素是经济中可变的违约率均值。违约率均值可以被看作是与宏观经济状态系统地联系在一起,一旦宏观经济恶化,则违约率就可能上升,违约率波动性也一样。经济形式的改善则有着相反的效应。
2.2信用事件的可变性及相关性
在关于信用事件的可变性方面,各个模型之间的关键差异在于,是为违约率建立模型,还是为违约分布函数的概率建立模型。在CreditMetricsTM模型中,违约率和信用等级转化概率被模型化为基于历史数据的固定的或离散的值。在KMV模型中,预期违约率随着新信息被纳入股票价格而发生变化,股票价格变化以及股票价格的波动性称为KMV模型中预期违约率计量的基础。在CreditRisk + 模型中,每笔贷款违约率被看作是可变的,并且服从围绕某些违约率均值的泊松分布,因此,违约率均值被模型化为一个服从r分布的变量。无论是与CreditMetricsTM模型还是与CPV模型比较,由CreditRisk + 模型可以产生一种可能有“更厚实的尾部”的损失分布。在CPV模型中,违约率是一套呈正态分布的宏观因素和冲击的对数函数,因此,随着宏观经济的演变,违约率以及信用等级转换矩阵中概率也会变化。
在信用事件的相关性方面,各模型具有不同的相关性结构,KMV模型和CreditMetricsTM是多变量正态;CPV模型是因素负载;而CreditRisk + 模型是独立假定或与预期违约率的相关性。
2.3信用风险因子的计算方法
CreditMetricsTM模型考虑可以让贷款违约损失利发生变化,在该模型为正态分布的情况下,估计的违约损失率的标准差被纳入了VaR的计算,在“实际”分布的情况下,考虑到贷款价值损失分布函数尾部的偏斜,因而假定违约损失率服从β分布,并且贷款的VaR通过蒙特卡罗模拟法来计算。
在KMV最简单的模型中,违约损失率被看作是一个常数。在该模型最新的发展中,也允许回收率遵循β分布。在CreditRisk + 模型中损失的严重程度被划分区间并凑成整数,从而得到次级的贷款组合,然后将任何次级贷款组合的损失的严重程度视为一个常数。在CPV模型中,违约损失率的估计也是通过蒙特卡罗模拟法进行的。
表1 4种信用风险量化模型的比较
| CreditMetricsTM模型 | KMV模型 | CreditRisk + 模型 | CreditPortifolioViewTM模型 | |
| 信用损失定义 | 盯市方法 | 盯市方法或违约模式 | 违约模式 | 盯市方法或违约模式 |
| 风险驱动因素 | 资产价值 | 资产价值 | 期望违约率 | 宏观经济因素 |
| 信用事件可变性 | 不变 | 可变 | 可变 | 可变 |
| 信用事件的相关性 | 多变量正态资产收益 | 多变量正态资产收益 | 独立假设或期望违约率相关 | 随因素变化 |
| 违约回收率 | 随机 | 常数或随机 | 分区域,每一区域为一值 | 随机 |
| 计算方法 | 模拟或分析 | 分析 | 分析 | 模拟 |
4个模型在估计VaR和预期损失的计算方法上是不尽相同的。不论是在个别贷款的层次上,还是在贷款组合的层次上,CreditMetricsTM模型均可以将组合的VaR有逻辑地分析和计量出来。但是随着贷款组合中贷款数目的增加,这一方法会变得越来越难以处理。结果是,对于大额的组合贷款组合CreditMetricsTM模型需要运用蒙特卡罗模拟技术来产生一个组合贷款价值的“近似的”总体分布,并由此计算出VaR。类似地,CPV模型中使用重复的蒙特卡罗模拟法来生成宏观冲击和贷款组合损失或贷款价值的分布,从而最终也能算出VaR。向比较而言,CreditRisk + 模型基于其方便的假定(个别贷款呈泊松分布,违约率均值呈r分布,以及假定在贷款组合中贷款损失有固定的回收率),能够生成关于损失的概率密度函数的逻辑分析解或闭型解。另外,KMV模型也可以获得损失函数的逻辑分析解。







{kind=link}