機械學習
出自 MBA智库百科(https://wiki.mbalib.com/)
目錄 |
所謂機械學習是一種單純依靠記憶學習材料,而避免去理解其複雜內部和主題推論的學習方法。平時多稱為死記、死背或死記硬背。
由美國心理學家大衛·奧蘇伯爾提出,與有意義學習相對的概念,指符號所代表的新知識與學習者認知結構中已有的知識建立非實質性的和人為的聯繫。如學生僅能記住乘法口訣表,形成機械的聯想,但並不真正理解這些符號所代表的知識。
機械學習模式[1]
機械學習是最簡單的機器學習方法。機械學習就是記憶,即把新的知識存儲起來,供需要時檢索調用,而不需要計算和推理。
機械學習又是最基本的學習過程。任何學習系統都必須記住它們獲取的知識。在機械學習系統中,知識的獲取是以較為穩定和直接的方式進行的,不需要系統進行過多的加工。而對於其它學習系統,需要對各種建議和訓練例子等信息進行加工處理後,才能存儲起來。
當機械學習系統的執行部分解決好問題之後,系統就記住該問題及其解。我們可把學習系統的執行部分抽象地看成某個函數,該函數在得到自變數輸入值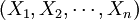 之後,計算並輸出函數值
之後,計算並輸出函數值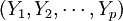 。機械學習在存儲器中簡單地記憶存儲對
。機械學習在存儲器中簡單地記憶存儲對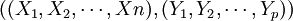 。當需要
。當需要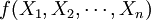 時,執行部分就從存儲器中把簡單地檢索出來而不是重新計算它。這種簡單的學習模式如下:
時,執行部分就從存儲器中把簡單地檢索出來而不是重新計算它。這種簡單的學習模式如下:
![]()
Lenat,Hayes Roth,和Klahr等人於1979年關於機械學習提出一種有趣的觀點。他們指出,可以把機械學習看成是數據化簡分級中的第一級。數據化簡與電腦語言編譯類似;其目的是把原始信息變成可執行的信息。在機械學習中我們只記憶計算的輸入輸出,忽略了計算過程,這樣就把計算問題化簡成存取問題,見下圖。

圖:數據化簡級別圖
正像計算問題可以簡化成存取問題一樣,其它的推理過程也可以簡化成較為簡單的任務。例如推導可以簡化成計算。比方說第一次要我們解一個一元二次方程的時候,我們必須使用很長的一段推導才能得出解方程的求根公式。但是一旦有了求根公式,以後再解一元二次方程時,就不必重覆以前的推導過程,可以直接使用求根公式計算出根,這樣就把推導問題簡化成計算問題。同樣地,歸納過程可以簡化成推導過程。
例如我們可以在大量病例的基礎上歸納總結出治療的一般規律,形成規則,當遇見一個新病例時,我們就使用規則去處理它,而不必參照以前的眾多病例推斷解決辦法。化簡的目的,主要是為了提高工作效率。
機械學習的主要問題[1]
對於機械學習,需要註意3個重要的問題:存儲組織,穩定性和存儲與計算之間的權衡。
(a) 存儲組織信息。顯然,只有當檢索一個項目的時間比重新計算一個項目的時間短時,機械學習才有意義,檢索的越快,其意義也就越大。因此,採用適當的存儲方式,使檢索速度儘可能地快,是機械學習中的重要問題。在數據結構與資料庫領域,為提高檢索速度,人們研究了許多卓有成效的數據存儲方式,如索引、排序、雜湊等等,在機械學習中我們可以充分利用這些成果來實現我們的要求。
(b) 環境的穩定性與存儲信息的適用性問題。在急劇變化的環境下機械學習策略是不適用的。做為機械學習基礎的一個重要假定是在某一時刻存儲的信息必須適用於後來的情況。然而如果信息變換得特別頻繁,這個假定就被破壞了。
(c) 存儲與計算之間的權衡。因為機械學習的根本目的是改進系統的執行能力,因此對於機械學習來說很重要的一點是它不能降低系統的效率。比方說,如果檢索一個數據比重新計算一個數據所花的時間還要多,那麼機械學習就失去了意義。
這種存儲與計算之間的權衡問題的解決方法有兩種。一種方法是估算一下存儲信息所要花費的存儲空間以及檢索信息時所花費的時間,然後將其代價與重新計算所花的代價比較,再決定存儲信息是否有利。另一種方法是把信息先存儲起來,但為了保證有足夠的檢索速度,限制了存儲信息的量,系統只保留那些最常使用的信息,“忘記”那些不常使用的信息。這種方法也叫“選擇忘卻”技術。
機械學習應用舉例[1]
雖然機械學習是機器學習中最簡單的策略,但是正確使用這種策略卻能對提高應用軟體系統的質量起著重要作用。下麵介紹吉林大學開發的建築工程預算軟體系統中採用的機械學習策略。這種方法成功地解決了工程預算中較難處理的圖集問題。
建築工程預算是建築工程中一項困難而又重要的任務,工作量大,要求高。過去用手工編製,要花費很多時間。一份3000m2的民用建築,一個技術人員手工編製預算需要15天至20天,加上工料分析,取費計算等等,需要近一個月時間,而且容易出錯,影響預算的質量,造成資金、人員和材料的浪費與損失。近年來,隨著電子電腦的普及應用,許多單位研製了建築預算系統,減輕了建築工程預算人員的繁重的腦力勞動,提高了工程預算的速度與準確性。
但是,建築預算中的關鍵問題——工程量計算問題,卻始終沒有得到很好地解決。這個問題的困難之一在於現行使用的建築工程設計圖紙上的數據與電腦要求的初始輸入數據之間存在著很大的差距,只有靠建築工程人員分析觀察圖紙,形成電腦可接受的初始輸入,才能開始計算。造成工程量計算困難的第二個原因是設計圖紙中出現的大量的門窗及預製件型號。預算中,工程技術人員需要不斷查閱有關資料,決定這些預製件所需工時及材料。所採用的機械學習方法主要用來解決這一困難。
建築工程中使用的門窗,大都採用國家或省市的標準設計,如JGMC—1—16—3是建工部規定的標準木窗,窗寬1米,高1.6米,此外還確定了窗的式樣,如該窗是亮子的,3開扇,中間固定,有小汽窗,根據這種標準設計圖紙,人們預先計算出建造一個這種窗子所需的木料,玻璃,油漆,合頁,鐵角,拉手,所需木工量,油工量等等。在建築工程圖紙上,並不畫出具體的窗子和門,只標明窗子和門的型號,預算時,人們只要數出各種窗子和門分別有多少個,然後根據標準圖集查出每種窗子和門各需多少原材料及人工,即可求出建造門窗所需總的建築材料及費用。
從問題的性質來看,採用電腦檢索是最適宜不過了。但事情並不那麼簡單,問題的難點在於門窗的標準型號太多。這些標準型號的門窗,按規定標準的部門及門窗的種類編成許多厚厚的標準圖集。雖然在工程預算程式內部保存了大量的標準圖集,但仍不能滿足預算的實際需要,一旦遇見一個先前未裝入的新型號,系統只好暫時停止運行,把新型號門窗及有關數據裝入後再行計算,這樣算算停停,很不方便,而且使預算時間拖得很長。
建築工程所用的門窗及預製構件雖多,但也有其規律性。一般說來,一個建築工程設計部門經常使用某些型號,對另外一些型號卻較少涉及,一個工程項目通常只採用幾種或幾十種型號的門窗和預製件,並不是雜亂無章的。因此可採用機械學習方法解決這一問題。當程式運行中遇見未曾裝入的門窗型號或預製構型號時,不是停下來待裝入後重新計算,而是向用戶提出詢問,根據用戶提供的數據,程式算出一個窗子或門等標準構件所需木材、玻璃、鐵角等材料及所需各工種工日數,然後把計算的數據提供給預算系統繼續計算,並把門窗等標準構件型號與所需材料及工日保存起來,以後再遇見同種型號的標準構件,建築工程系統只要通過檢索就能獲得數據,可以順利進行下去,不再需要用戶干預。因為大多數工程項目為著採購、製造、運輸與管理上的方便,只採用幾種或幾十種的標準預製構件,所以預算系統在詢問幾次之後,就不必再行詢問,直至計算得出最終預算結果,從而方便了用戶,縮短了運行時間。
這種預算方法的另一個優點是具有廣泛的適應性和自我完善能力,一個建築設計部門通常與幾個門窗生產廠家與預製件廠家有業務聯繫,因此通常採用某些型號的標準預製件。一旦這些型號的數據裝入電腦,系統就能在大多數情況下獨立完成預算。因此,上述採用的圖集處理方法不僅適用於吉林省,而且其它省份與建築部門也可同樣採用,只要他們使用一段時間之後,系統所積累的型號就基本上能滿足他們的要求。因此便於推廣,而且使用的次數越多,積累的標準構件型號越多,系統提出詢問的情況越少,計算的速度也越來越快。






