财务困境预测模型
出自 MBA智库百科(https://wiki.mbalib.com/)
目录 |
财务困境预测模型研究的基本问题——财务困境
财务困境(Financial distress)又称“财务危机”(Financial crisis),最严重的财务困境是“企业破产” (Bankruptcy)。企业因财务困境导致破产实际上是一种违约行为,所以财务困境又可称为“违约风险”(Default risk)。
事实上,企业陷入财务困境是一个逐步的过程,通常从财务正常渐渐发展到财务危机。实践中,大多数企业的财务困境都是由财务状况正常到逐步恶化,最终导致财务困境或破产的。因此,企业的财务困境不但具有先兆,而且是可预测的。正确地预测企业财务困境,对于保护投资者和债权人的利益、对于经营者防范财务危机、对于政府管理部门监控上市公司质量和证券市场风险,都具有重要的现实意义。纵观财务困境判定和预测模型的研究,涉及到三个基本问题:
- 1、财务困境的定义;
- 2、预测变量或判定指标的选择;
- 3、计量方法的选择。
- 预测变量或判定指标的选择
财务困境预测模型因所用的信息类型不同分为财务指标信息类模型、现金流量信息类模型和市场收益率信息类模型。
1、财务指标信息类模型
Ahman(1968)等学者(Ahman,Haldeman和Narayanan,1980;Platt和Platt, 1991)使用常规的财务指标,如负债比率、流动比率、净资产收益率和资产周转速度等,作为预测模型的变量进行财务困境预测。
尽管财务指标广泛且有效地应用于财务困境预测模型,但如何选择财务指标及是否存在最佳的财务指标来预测财务困境发生的概率却一直存在分歧。Harmer (1983)指出被选财务指标的相对独立性能提高模型的预测能力。Boritz(1991)区分出65个之多的财务指标作为预测变量。但是,自Z模型 (1968)和ZETA模型(1977)发明后,还未出现更好的使用财务指标于预测财务困境的模型。
2、现金流量信息类模型
现金流量类信息的财务困境预测模型基于一个理财学的基本原理:公司的价值应等于预期的现金流量的净现值。如果公司没有足够的现金支付到期债务,而且又无其他途径获得资金时,那么公司最终将破产。因此,过去和现在的现金流量应能很好地反映公司的价值和破产概率。
在Gentry,Newbold和Whitford(1985a;1985b)研究的基础上,Aziz、Emanuel和Lawson(1988)发展了现金流量信息预测财务困境模型。公司的价值来自经营的、政府的、债权人的、股东的现金流量的折现值之和。他们根据配对的破产公司和非破产公司的数据,发现在破产前5年内两类公司的经营现金流量均值和现金支付的所得税均值有显著的差异。显然,这一结果是符合现实的。破产公司与非破产公司的经营性现金流量会因投资质量和经营效率的差异而不同,二者以现金支付的所得税也会因税收会计的处理差异而不同。Aziz、Emanuel和Lawson(1989)比较了Z 模型、ZETA模型、现金流量模型预测企业发生财务困境的准确率,发现现金流量模型的预测效果较好。
3、市场收益率信息类模型
Beaver(1968)是使用股票市场收益率信息进行财务困境预测研究的先驱。他发现在有效的资本市场里,股票收益率也如同财务指标一样可以预测破产,但时间略滞后。Altman和Brenner(1981)的研究表明,破产公司的股票在破产前至少1年内在资本市场上表现欠佳。Clark和Weinstein(1983)发现破产公司股票在破产前至少3年内存在负的市场收益率。然而,他们也发现破产公告仍然向市场释放了新的信息。破产公司股票在破产公告日前后的两个月时间区段内平均将经历26%的资本损失。
Aharony,Jones和Swary(1980)提出了一个基于市场收益率方差的破产预测模型。他们发现在正式的破产公告日之前的4年内,破产公司的股票的市场收益率方差与一般公司存在差异。在接近破产公告日时,破产公司的股票的市场收益率方差变大。
- 计量方法的选择
财务困境的预测模型因选用变量多少不同分为
1、单变量预测模型
2、多变量预测模型:多变量预测模型因使用计量方法不同分为
- 1)线性判定模型
- 2)线性概率模型
- 3)Logistic回归模型。
此外,值得注意的是,近年来财务困境预测的研究方法又有新的进展,网络神经遗传方法已经开始被应用于构建和估计财务困境预测模型。
上市公司财务困境预测模型比较研究[1]
一、建模方法
1.统计方法
采用MDA、Logistic回归、近邻法,以及分类和回归树(CART)四种方法建立统计模型,其中前两者属于参数法,后两者属于非参数方法。
MDA和Logistic回归都属于多元统计学方法,基本思路是由一些已知类别的训练样本,根据判别准则建立判别函数(模型),用来对新样本进行分类。这两种方法的最大优点在于具有明显的解释性,存在的缺陷是过于严格的前提条件。如两者都对变量之间多重共线性敏感,且MDA要求数据服从多元正态分布和等协方差。
近邻法根据新样本在特征空间中K个近邻样本中的多数样本的类别来进行分类,因此具有直观、无需先验统计知识、无需学习等特点。但当样本的维数较高时,存在所谓的“维数祸根”——对高维数据,即使样本量很大,其散布在高维空间中仍显得非常稀疏,这使得“近邻”的方法不可靠
CART是一种现代非参数统计方法,它根据一定的标准,运用二分法,通过建立二元分类树来对新样本进行预测。CART模型宜于理解,能处理缺失数据,并且对噪声有一定的鲁棒性。它的缺点是,作为一种前向选择方法,当它引入新的分类规则时并没有考虑前面的分类方法,因而有可能同一个分类变量会重复出现但判别点发生变化。
2.神经网络方法
神经网络是由大量的简单处理单元相互联结组成的复杂网络系统。作为非参数的分类方法,它克服了选择模型函数形式的困难,同时对样本及变量的分布特征没有限制。采用在财务困境预测研究中应用最广的三种神经网络:反向传播网络(BPNN)、概率神经网络(PNN)和学习矢量量化网络(LVQ)来建立模型。
BPNN是应用最广泛的一种神经网络。在建立财务困境预测模型时,一般选三层BPNN:输入层由代表财务比率的节点构成;隐层节点个数由经验试错法确定;输出层仅有一个节点,该节点输出值大于预设阈值时为一类,小于预设阈值时为另一类。
PNN主要是用估计各个类别核密度的方法完成样本分类。当用于财务困境预测时,PNN通常取三层:输入层节点数等于建模所用财务比率个数;中间层节点数等于训练集样本个数;输出层节点数等于样本类别数。与BPNN相比,PNN的优势在于要估计的参数少,训练时间短,而且能够对模型生成的结果做出概率上的解释。
LVQ是在自组织映射神经网络基础上改进的一种有导师监督分类器,它允许对输入样本按照所属的类别进行指定。用于财务困境预测的LVQ由三层节点组成。输入层节点数等于建模所用的财务比率个数,输出层节点数对应于输入样本的类别个数。与前两种神经网络不同的是,LVQ竞争层的每个节点只与输出层的一个节点相连接,即被指定属于这个输出层节点所对应的类别。也就是说,竞争层将输入矢量分成不同子类,输出层负责将竞争隐层的子类转换为使用者定义的类别。
神经网络具有一些统计方法无法比拟的优点,如:对数据分布的要求不严格;非线性的函数映射方式;高鲁棒性和自适应性等。然而,由于神经网络缺乏统一的数学理论,在如何确定网络结构、如何提高模型的解释性、过学习和局部极小点等问题上还未有实质突破,并且实际效果也不太稳定。
3.交叉验证
所谓m重交叉验证,就是将样本总数为n的样本集随机地分成m个不相交的组,每组有nlm个样本。用(m-1)个组的样本训练分类器,并用剩余的1个组的样本作为测试集测试分类器,求得一测试误差。重复这一过程,直到m个组中的每一组都成为过一次测试集为止。将m个组所对应溅试误差的平均值作为分类器在整个样本集上的测试误差。交叉验证能减少估计偏差,从而更客观地评价模型。
二、样本和变量选择
1.样本选择
我国沪深股市1998~2002五年间258家公司选作建模样本,其。申ST公司和配对的非ST公司各129家,将2003,2004两年内被ST的106家公司和246家非ST公司作为独立的预测集,所有610家公司假设是在t年被ST或未被ST。样本选择标准如下:
1)从1998~2002五年间所有的151家sT公司中剔除因“其它状况异常”而被ST的公司22家,保留因“财务状况异常”(“连续两年亏损”或“每股净资产低于股票面值”)而被ST的129家公司作为财务困境公司;根据同行业与总资产规模相当标准,从同一财务年度选出129家配对的非ST公司;
2)在构造预测集时,为了评价模型实际预测效果,将2003-2004两年内所有ST公司全部选人预测集,没有进行任何剔除;在选择非ST样本时,同样为了评价模型实际预测效果,没有根据配对原则来选,只是随机地选取了这两年内246家非ST公司;
2.比率选择
由于缺乏具体的经济理论指导,而公司被ST的本质原因又不尽相同,所以很难用简单的几个财务比率对财务困境进行充分描述。研究者选用的财务比率有所差异,通常选择尽可能多的财务比率,这些不同的财务比率反映着企业不同的财务侧面,如盈利能力、偿债能力、营运能力和现金能力等方面。从研究结果来看,得出的预测财务困境最有效的财务比率也不尽相同心。财务比率共有41个(见下表),反映了企业财务状况的各个方面,以便从中找出统计检验显著性强的比率进行建模

三、模型选择
为了消除财务比率量纲和数量级差异的影响,首先对原始数据进行标准化,即变换为均值为0和标准差为1的新数据。然后进行ST公司和非ST公司财务比率差异的单变量检验。根据检验结果,首先选出两类公司间具有显著差异(P<0.05)的比率:被ST前的(t-2)财政年度包括X3 − X9,X11,X15,X17 − X26,X19,X31,X37,X40,X41;被ST前的(t-3)财政年度包括X5 − X8,X14,X15,X17,X18,X20,X22 − X26,X28,X29,X37 − X41
1.统计模型
MDA和Logistic回归模型预测变量集
| (t-2) | (t-3) |
|---|---|
| X6,X17,X23,X24,X25 | X7,X20,X28,X38,X41 |
对于MDA和longistic回归,首先采用10重交叉验证+和逐步回归选择变量方法对上述初选的比率集进行再次筛选,如果某一财务比率在10次结果中出现了4次以上。则被选人。然后经过多重共线性检验剔除冗余变量,最终选出的预测变量如表2
对于近邻法,仍采用上述财务比率集{X_6,X_17,X_23,X_24,X_25}和{X_7,X_20,X_28,X_38,X_41}作为(t-2)和(t-3)年模型的预测变量集。并应用10重交叉验证选择近邻数K,具体如表3。可见,最近邻(K=1)具有最佳分类效果
近邻法K选择的10重交叉验证分析
| K | (t-2) | (t-3) | ||||
|---|---|---|---|---|---|---|
| 总正确数 | 一类错误数 | 二类错误数 | 总正确数 | 一类错误数 | 二类错误数 | |
| 1 | 24.4 | 0.7 | 0.7 | 23.5 | 1.1 | 1.2 |
| 3 | 23 | 2 | 0.8 | 20.7 | 2.6 | 2.5 |
| 5 | 22.2 | 2.3 | 1.3 | 19.8 | 3.1 | 2.9 |
| 7 | 22.3 | 2.4 | 1.1 | 19.7 | 3.1 | 3 |
| 9 | 22.5 | 2.4 | 0.9 | 19.9 | 3.2 | 2.7 |
注:表3-表7中数据均为10次交叉测试结果的平均值
由于决策树属于非参数化的自上而下的归纳学习算法,所以对于CART模型,不必对变量进行筛选
但是,为防止“过拟合”发生,需要对树进行修剪,修剪程度的大小由10重交叉验证确定,结果如下表。可见,未剪枝的CART在10个测试集上的平均效果最好,但与剪枝2的效果没有明显差别,根据Occam剃刀原理㈨,选用剪枝度为2的CART模型
CART剪枝度选择的10重交叉验证分析
| 剪枝程度 | (t-2) | (t-3) | ||||
|---|---|---|---|---|---|---|
| 总正确数 | 一类错误数 | 二类错误数 | 总正确数 | 一类错误数 | 二类错误数 | |
| 0 | 24.1 | 1.1 | 0.6 | 22.3 | 1.9 | 1.8 |
| 1 | 23.8 | 1.2 | 0.8 | 21.9 | 1.9 | 2 |
| 2 | 23.6 | 1.1 | 1.1 | 21.6 | 1.9 | 2.3 |
| 3 | 23 | 1.3 | 1.5 | 21.3 | 1.8 | 2.7 |
2.神经网络模型
由于神经网络自学习能力和非线性映射能力很强,输入变量间是否存在多重共线性对数据处理结果的影响不大,因此在构建神经网络模型时没有进行变量筛选,而仅仅使所选财务比率尽可能包含比较多的信息。选取了X3、X7、X13、X15、X18、X_20、X_24、X25、X29和X41共10个比率作为神经网络的输入变量,它们全面地反映了企业的盈利能力、偿债能力、营运能力和现金能力等各个方面。
对于BPNN,采用小随机数作为初始权值,以使初始点尽量避免局部极小。隐层节点数由经验公式确定。
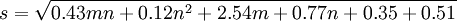 (1)
(1)
其中,s值经四舍五人取整后作为中间层节点数,m为输入层节点数,n为输出层节点数。由上可知m=10,n=1计算得中间层的节点数为6。采用10重交叉验证确定BPNN的训练误差参数,结果如表5。可见,对于(t-2)年数据,误差参数为0。06时BPNN的平均效果最好;对于(t-3)年数据,误差参数为0.09时BPNN的平均效果最好
BPNN误差参数的10重交叉验证分析
| 误差 | (t-2) | (t-3) | ||||
|---|---|---|---|---|---|---|
| 总正确数 | 一类错误数 | 二类错误数 | 总正确数 | 一类错误数 | 二类错误数 | |
| 0.05 | 23.1 | 1.6 | 1.1 | 20.8 | 2.1 | 2.9 |
| 0.06 | 23.6 | 1 | 1.2 | 21.7 | 1.9 | 2.2 |
| 0.08 | 23.2 | 1.1 | 1.5 | 21.7 | 1.8 | 2.3 |
| 0.09 | 22.2 | 2.1 | 1.5 | 22 | 1.5 | 2.3 |
| 0.1 | 231.5 | 1.3 | 20.4 | 2.5 | 2.9 | |
对于PNN,需要用户设置的唯一未知参数是σ,它表示有效的高斯窗的宽度。用10重交叉验证技术确定。结果如下表。可见,对于(t-2)和(t-3)年数据,σ = 1时PNN的平均效果都是最好
PNN参数σ的lO重交叉验证分析
| σ | (t-2) | (t-3) | ||||
|---|---|---|---|---|---|---|
| 总正确数 | 一类错误数 | 二类错误数 | 总正确数 | 一类错误数 | 二类错误数 | |
| 1 | 23.2 | 1.2 | 1.4 | 21.4 | 1.7 | 2.7 |
| 2 | 22.5 | 1.6 | 1.7 | 19.7 | 2.3 | 3.8 |
| 3 | 22.1 | 2 | 1.7 | 19.3 | 2.7 | 3.8 |
LVQ的学习速率饮由lO重交叉验证确定,结果如下表。可见,当学习速率LR=0.05时(t-2)年模型平均效果最好;当LR=0.01时(t-3)年模型平均效果最好。
LVQ学习速率10重交叉验证分析
| LR | (t-2) | (t-3) | ||||
|---|---|---|---|---|---|---|
| 总正确数 | 一类错误数 | 二类错误数 | 总正确数 | 一类错误数 | 二类错误数 | |
| 0.005 | 22.1 | 1.9 | 1.8 | 19.2 | 2.8 | 3.8 |
| 0.01 | 22 | 2 | 1.8 | 19.3 | 2.7 | 3.8 |
| 0.05 | 22.3 | 1.9 | 1.6 | 18.9 | 2.8 | 4.1 |
| 0.1 | 22 | 1.8 | 2 | 19.2 | 2.4 | 4.2 |
分别采用在预测集和测试集上的10次分类结果的平均值来进行比较。具体是,在模型选择时所用的10重交叉训练集上确立10个具体分类模型,然后分别在相应的10个交叉测试集和同一预测集上进行分类,将分别得到的10个分类结果进行平均。表8列出了各个模型在测试集上的平均结果,表9列出了各模型在预测集上的平均结果。

由上表和下表中的实证结果可见:

1)对于提前两年预测,统计和神经网络模型都能有效的预测财务困境发生,其中MDA总正确率最高,最近邻效果最差,CART和lJ09istic回归略好于三种神经网络模型。对于提前三年预测,所有模型的预测准确率都较低,除BPNN外,其它两种神经网络模型均优于统计模型。
2)对于提前两年和提前三年预测,所有模型在测试集上的分类结果明显地优于在预测集上的结果,这证明了用同一财务年度区间内的样本集作为测试集,即使测试集独立于训练集,实证结果也趋于乐观。
更重要的是,在测试集上效果好的模型在预测集上的效果未必好,如最近邻模型在测试集上效果最好,而在预测集上较差。这更加表明在测试集上评价模型的不合理性。
中国上市公司作为研究对象,以因财务状况异常而被特别处理作为界定上市公司陷入财务困境的标志,采用交叉验证技术建立统计和神经网络预测模型,并在独立的预测集上进行比较。实证结果表明统计和神经网络模型都能有效地预测上市公司的财务困境,统计模型在提前两年预测时效果较好,神经网络模型在提前三年预测时效果较好。实证结果同时表明,与训练集处在同一财务年度区间内的测试集不能够正确地评估模型性能。
- ↑ 谢纪刚,裘正定,韩彦俊等.上市公司财务困境预测模型比较研究[J].系统工程理论与实践,2005,25(9)







太深奥了