歷史模擬法
出自 MBA智库百科(https://wiki.mbalib.com/)
歷史模擬法(Historical Simulation Method,簡稱HS法)
目錄 |
歷史模擬法是一個簡單的、非理論的方法,有些金融商品不易取得完整的歷史交易資料,此時可以藉由搜集此金融商品之風險因數計算過去一段時間內的資產組合風險收益的頻率分佈,通過找到歷史資料求出其報酬率,然後搭配目前持有資產的投資組合部位,則可以重新建構資產價值的歷史損益分配,然後對資料期間之每一交易日重覆分析步驟,如果歷史變化重覆時,則可以重新建構資產組合未來報酬的損益分配。
歷史模擬法不必假設風險因數的報酬率必須符合常態分配。
假設現在的時間為t = 0'Si(t)為第I項資產在時間t的價格,以歷史模擬法來估算未來一天的風險植的程式:
1、選取過去N+1天第I項資產的價格作為模擬資料;例如首先找出過去一段時間(假設是201天)的股票收盤價:Si( − 1)、Si( − 2)…Si( − 200)、Si( − 201)。
2、將過去彼此相鄰的N+1筆價格資料相減,就可以求得N筆該資產每日的價格損益變化量;例如:Δ1 = Si( − 1) − Si( − 2)、Δ2 = Si( − 2) − Si( − 3)、Δ200 = Si( − 200) − Si( − 201)。
3、步驟2代表的是第I項資產在未來一天損益的可能情況(共有N種可能情形),將變化量轉換成報酬率,就可以算出N種的可能報酬率,也就是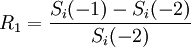 、
、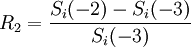 、
、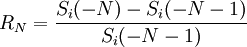 。
。
4、將步驟3的報酬率由小到大依序排列,並依照不同的信賴水準找出相對應分位數的臨界報酬率。
5、將目前的資產價格Si(0)乘以步驟4的臨界報酬率,得到的金額就是使用歷史模擬法所估計得到的風險值。
以歷史模擬法算出風險值

歷史模擬法釋例1
債券風險設算為例:
(1)確定風險因數:國內債券的風險因數為利率。
(2)選取歷史期間的長度
(3)搜集利率的資料,並計算每日利率波動之程度,及其所有相對應之損益分佈。
(4)將所有相對的債券損益按大小依序排列,計算其方式機率並繪成直方圖,模擬出未來的損益分配。
(5)選定所要估計之信賴水準,在該百分位數之價值即為此債券之風險值。
歷史模擬法釋例2
假設今日以60元買入鴻海的股票1萬張共60萬元,我們只可以找到過去101個交易日的歷史資料,求在95%信賴水準之下的日風險值為何?
1.根據過去101日鴻海之每日收盤價資料,可以產生100個報酬率資料。
2.將100個報酬率由小排到大找出到倒數第五個報酬率(因為信賴水準為95%),在此假設為-4.25%。
3.-4.25% * 600,000 =-$25,500
4.所以VaR= $25,500,因此明日在95%的機率下,損失不會超過$ 25,500元。
使用歷史模擬法要有大量的歷史資料,才有辦法精確的敘述在極端狀況下(如99%的信賴水準)的風險值 。
歷史資料中能捕捉到的極端損失的機率低於正常損益的機率,量多而且具有代表性的資料的取得就相形重要。
歷史模擬法更可以勾勒出資產報酬分配常見的厚尾、偏態、峰態等現象,因此計算曆史價格的時間(與資料的多寡有關)是影響風險值的一個重點。
優點:不需要加諸資產報酬的假設
利用歷史資料,不需要加諸資產報酬的假設,可以較精確反應各風險因數的機率分配特性,例如一般資產報酬具有的厚尾、偏態現象就可能透過歷史模擬法表達出來
優點:不需分配的假設
歷史模擬法是屬於無母數法的一員,不須對資產報酬的波動性、相關性做統計分配的假設,因此免除了估計誤差的問題;況且歷史資料已經反應資產報酬波動性、相關性等的特征,因此使得歷史模擬法相較於其它方法,較不受到模型風險的影響。
優點:完全評價法
不需要類似一階常態法以簡化現實的方式,利用趨近求解的觀念求取進似值;因此無論資產或投資組合的報酬是否為常態或線性,波動是否隨時間而改變,Gamma風險等等,皆可採用歷史模擬法來衡量其風險值。
缺點:資料的品質與代表性
龐大歷史資料的儲存、校對、除錯等工作都需要龐大的人力與資金來處理,如果使用者對於部位大小與價格等信息處理、儲存不當,都會產生垃圾進,垃圾出的不利結果。
有些標的物的投資信息取得不易,例如未上市公司股票的價格、新上市(櫃)公司股票的歷史資料太短、有的流動性差的股票沒有每日成交價格等。
若某些風險因數並無市場資料或歷史資料的天數太少時,模擬的結果可能不具代表性,容易有所誤差。 缺點:極端事件的損失不易模擬
主要的理由就是重大極端事件的損失比較罕見,無法有足夠的資料來模擬損失分配 。
極端事件發生期間占整體資料比數的比例如何安排也是個問題,不同的比例會深深影響歷史模擬法的結果。
例如以國際股票投資為例,1997年的亞洲金融危機、2001年美國發生的911恐怖攻擊事件、美伊戰爭的進展等事件都會引發全球股市的大幅變動,若這些發生巨幅變動的時間占整體資料的比重過大,就會高估正常市場的波動性,因而高估真正的風險值。
缺點:因數的變動假設
未來風險因數的變動會與過去表現相同的假設,不一定可以反映現實狀況。
漲跌幅比例的改變、交易時段延長、最小跳動單位改變等,都會使得未來的評估期間的市場的結構可能會產生改變,而跟過去歷史模擬法選樣的期間不同,甚至從未在選樣期間發生的事件,其損益分配是無從反映在評估期間的風險值計算上。
缺點:資料選取的長度
雖然資料筆數要夠多才有代表性,但是太多久遠的資料會喪失預測能力,但是過少的時間資料又可能會遺失過去曾發生過的重要訊息,兩者的極端情況都會使歷史模擬法得所到的風險值可信度偏低,造成兩難的窘境。
到底要選用多長的選樣期間,只有仰賴對市場的認知與資產的特性,再加上一點主觀的判斷來決定了。
包括指數加權移動平均法與拔靴複製法(Bootstrap Method),前者可以給予近期資料較高的權值,後者可以在歷史資料不足的時候增加選樣筆數。
歷史模擬法的案例分析[1]
- 案例:基於歷史模擬法的VaR的設計與實現
- (一)歷史數據的處理及構建收益率序列
在歷史模擬法的實際操作中,歷史數據多數從金融數據服務商那裡獲得,而且構建歷史的盈虧序列時,我們必須考慮以下幾個問題:。
1.歷史數據的來源及格式。據統計,截至2005年,有近8000支美國三大交易所NYSE,AMEX,Nasdaq.上市,除此之外,在金融市場的衍生品更是數不勝數。要獲得某一支股票歷史數據猶如大海撈針,所以我們不得不藉助金融服務商,如Bloomberg(彭博),reuters(路透),從提供商那裡能方便的獲得數據,但是此時問題出現了,不同的服務商提供的數據並非統一的格式,例如有些歷史數據以TXT文本的形式提供,而有些則以XML文件的形式提供,對於數據整體打包出售的數據則以資料庫的形式提供。除了提供的數據格式有變化之外,數據的內容也有不同,對於多數股票來說,數據多為股票價格,也就是說,從歷史數據中我們能看到每一天的歷史報價,而對於複合形式的金融產品而言,數據提供商只提供其歷史收益率,即每一天相對於前一天的收益率歷史記錄。
2.對歷史數據的優化處理。上述的歷史數據要應用到VaR的數學模型中必須經過修改,一般情況,VaR模型中應用其歷史收益率來計算,然而針對不同的類型的金融產品又有差別,例如,對股票來說,一般對其價格取對數,獲得其對數收益率,即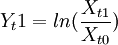 ,Yt1即時間點t1相對於t0的收益率。而以收益率存儲的歷史數據,沒有必要對其進行任何轉換。有些金融產品的收益率採取最直接的形式來取得收益率序列,其收益率計算公式為
,Yt1即時間點t1相對於t0的收益率。而以收益率存儲的歷史數據,沒有必要對其進行任何轉換。有些金融產品的收益率採取最直接的形式來取得收益率序列,其收益率計算公式為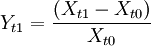 。
。
3.構建盈虧序列(PNL,ProfitandLoss)。盈虧序列是指當前的頭寸映射到對應的歷史數據序列上,即此金融產品的歷史收益率序列上,獲得歷史上的各個時間點的盈虧值。由此可知,盈虧序列的建立必須滿足兩個條件,1.已經處理好的歷史數據2.當前的頭寸。經過處理的歷史數據已經經過討論,當前頭寸可以作為參數直接輸入獲得,當然為了更好的結構性和擴展性的考慮我們可以把頭寸寫入配置文件中。用數學公式PnL=Position(頭寸)*(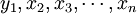 )。
)。
- (二)系統設計
針對上述問題,設計圖如下:

由圖可知:針對上述問題1,設計一個DataSeries介面,同時兩個抽象類FileDataSeries,DatabaseDataSeries實現此介面,且分別對應數據來源:文件和資料庫,這樣不同格式,不同來源的歷史數據均能整合到一起,而對於SimulatePnL不需要知道數據的原始來源以及格式,因為他只需要用到最終的原始有效數據而不必去關心太多的細節。
同理,針對問題2,設計Computer介面,即針對原始數據進行處理,針對不同的數據處理方法設計不同的類,這些類分別實現此介面,當然隨著統計方式的變化,新的數據處理方法會被提出,此時只需添加新的類來實現新的方法,而程式的結構不需要改變,而DataSeries的設計思路也是如此。
SimulatePnL的設計是針對問題3的。有了Computer,DataSeries這些數據結構,很容易構造出收益率序列,同時結合頭寸(TradedPostion),便可以比較容易的構造出PnL序列。
- (三)VaR的計算
由上述PnL序列,根據數學統計方法,我們可以計算出方差D(X),和標準差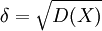 ,根據置信水平α,我們可以得到分位數Zc
,根據置信水平α,我們可以得到分位數Zc
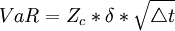
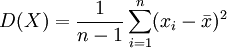
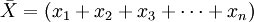 。
。
- (四)配置文件
<VaR>
<ConfidenceLevel>
<confidenceValue>0.95</confidenceValue>
<quantile>1.96</quantile>
</ConfidenceLevel>
<TradedPosition>4,000,0
00</TradedPosition>
<DataSeries>
<DataSourceType>File</DataSourceType>
<DataSourceClass>XMLDataSeries</DataSourceClass>
<SecurityID>SHA:60188</SecurityID>
<FilePath>D:\\data\\ch-60188.xml</FilePath>
</DataSeries>
<Computer>LogNormalComputer</Computer>
</VaR>
由上述的設計類圖可知,當VaR計算引擎啟動時,Runner從配置文件中讀取分位數,頭寸等相應參數,當DataSourceType為File時,即數據來源於文件,而DataSourceClass明確指明瞭用什麼樣對應的數據處理類來獲得歷史數據,FilePath指明瞭數據文件的存儲位置。如果DataSourceType為DB時,對應的類會根據SecurityID從資料庫中來獲得數據序列。Computer指定了對原始數據處理的方式方法類,LogNormalComputer意味著對原始數據進行取對數然後構造對數收益率序列。
- ↑ 李偉傑.淺談歷史模擬法VaR的設計和實現.時代金融.2009年07期







{kind=link}