历史模拟法
出自 MBA智库百科(https://wiki.mbalib.com/)
历史模拟法(Historical Simulation Method,简称HS法)
目录 |
历史模拟法是一个简单的、非理论的方法,有些金融商品不易取得完整的历史交易资料,此时可以借由搜集此金融商品之风险因子计算过去一段时间内的资产组合风险收益的频率分布,通过找到历史资料求出其报酬率,然后搭配目前持有资产的投资组合部位,则可以重新建构资产价值的历史损益分配,然后对资料期间之每一交易日重复分析步骤,如果历史变化重复时,则可以重新建构资产组合未来报酬的损益分配。
历史模拟法不必假设风险因子的报酬率必须符合常态分配。
假设现在的时间为t = 0'Si(t)为第I项资产在时间t的价格,以历史模拟法来估算未来一天的风险植的程序:
1、选取过去N+1天第I项资产的价格作为模拟资料;例如首先找出过去一段时间(假设是201天)的股票收盘价:Si( − 1)、Si( − 2)…Si( − 200)、Si( − 201)。
2、将过去彼此相邻的N+1笔价格资料相减,就可以求得N笔该资产每日的价格损益变化量;例如:Δ1 = Si( − 1) − Si( − 2)、Δ2 = Si( − 2) − Si( − 3)、Δ200 = Si( − 200) − Si( − 201)。
3、步骤2代表的是第I项资产在未来一天损益的可能情况(共有N种可能情形),将变化量转换成报酬率,就可以算出N种的可能报酬率,也就是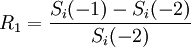 、
、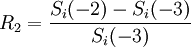 、
、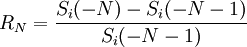 。
。
4、将步骤3的报酬率由小到大依序排列,并依照不同的信赖水准找出相对应分位数的临界报酬率。
5、将目前的资产价格Si(0)乘以步骤4的临界报酬率,得到的金额就是使用历史模拟法所估计得到的风险值。
以历史模拟法算出风险值

历史模拟法释例1
债券风险设算为例:
(1)确定风险因子:国内债券的风险因子为利率。
(2)选取历史期间的长度
(3)搜集利率的资料,并计算每日利率波动之程度,及其所有相对应之损益分布。
(4)将所有相对的债券损益按大小依序排列,计算其方式机率并绘成直方图,模拟出未来的损益分配。
(5)选定所要估计之信赖水准,在该百分位数之价值即为此债券之风险值。
历史模拟法释例2
假设今日以60元买入鸿海的股票1万张共60万元,我们只可以找到过去101个交易日的历史资料,求在95%信赖水准之下的日风险值为何?
1.根据过去101日鸿海之每日收盘价资料,可以产生100个报酬率资料。
2.将100个报酬率由小排到大找出到倒数第五个报酬率(因为信赖水准为95%),在此假设为-4.25%。
3.-4.25% * 600,000 =-$25,500
4.所以VaR= $25,500,因此明日在95%的机率下,损失不会超过$ 25,500元。
使用历史模拟法要有大量的历史资料,才有办法精确的叙述在极端状况下(如99%的信赖水准)的风险值 。
历史资料中能捕捉到的极端损失的机率低于正常损益的机率,量多而且具有代表性的资料的取得就相形重要。
历史模拟法更可以勾勒出资产报酬分配常见的厚尾、偏态、峰态等现象,因此计算历史价格的时间(与资料的多寡有关)是影响风险值的一个重点。
优点:不需要加诸资产报酬的假设
利用历史资料,不需要加诸资产报酬的假设,可以较精确反应各风险因子的机率分配特性,例如一般资产报酬具有的厚尾、偏态现象就可能透过历史模拟法表达出来
优点:不需分配的假设
历史模拟法是属于无母数法的一员,不须对资产报酬的波动性、相关性做统计分配的假设,因此免除了估计误差的问题;况且历史资料已经反应资产报酬波动性、相关性等的特征,因此使得历史模拟法相较于其它方法,较不受到模型风险的影响。
优点:完全评价法
不需要类似一阶常态法以简化现实的方式,利用趋近求解的观念求取进似值;因此无论资产或投资组合的报酬是否为常态或线性,波动是否随时间而改变,Gamma风险等等,皆可采用历史模拟法来衡量其风险值。
缺点:资料的品质与代表性
庞大历史资料的储存、校对、除错等工作都需要庞大的人力与资金来处理,如果使用者对于部位大小与价格等信息处理、储存不当,都会产生垃圾进,垃圾出的不利结果。
有些标的物的投资信息取得不易,例如未上市公司股票的价格、新上市(柜)公司股票的历史资料太短、有的流动性差的股票没有每日成交价格等。
若某些风险因子并无市场资料或历史资料的天数太少时,模拟的结果可能不具代表性,容易有所误差。 缺点:极端事件的损失不易模拟
主要的理由就是重大极端事件的损失比较罕见,无法有足够的资料来模拟损失分配 。
极端事件发生期间占整体资料比数的比例如何安排也是个问题,不同的比例会深深影响历史模拟法的结果。
例如以国际股票投资为例,1997年的亚洲金融危机、2001年美国发生的911恐怖攻击事件、美伊战争的进展等事件都会引发全球股市的大幅变动,若这些发生巨幅变动的时间占整体资料的比重过大,就会高估正常市场的波动性,因而高估真正的风险值。
缺点:因子的变动假设
未来风险因子的变动会与过去表现相同的假设,不一定可以反映现实状况。
涨跌幅比例的改变、交易时段延长、最小跳动单位改变等,都会使得未来的评估期间的市场的结构可能会产生改变,而跟过去历史模拟法选样的期间不同,甚至从未在选样期间发生的事件,其损益分配是无从反映在评估期间的风险值计算上。
缺点:资料选取的长度
虽然资料笔数要够多才有代表性,但是太多久远的资料会丧失预测能力,但是过少的时间资料又可能会遗失过去曾发生过的重要讯息,两者的极端情况都会使历史模拟法得所到的风险值可信度偏低,造成两难的窘境。
到底要选用多长的选样期间,只有仰赖对市场的认知与资产的特性,再加上一点主观的判断来决定了。
包括指数加权移动平均法与拔靴复制法(Bootstrap Method),前者可以给予近期资料较高的权值,后者可以在历史资料不足的时候增加选样笔数。
历史模拟法的案例分析[1]
- 案例:基于历史模拟法的VaR的设计与实现
- (一)历史数据的处理及构建收益率序列
在历史模拟法的实际操作中,历史数据多数从金融数据服务商那里获得,而且构建历史的盈亏序列时,我们必须考虑以下几个问题:。
1.历史数据的来源及格式。据统计,截至2005年,有近8000支美国三大交易所NYSE,AMEX,Nasdaq.上市,除此之外,在金融市场的衍生品更是数不胜数。要获得某一支股票历史数据犹如大海捞针,所以我们不得不借助金融服务商,如Bloomberg(彭博),reuters(路透),从提供商那里能方便的获得数据,但是此时问题出现了,不同的服务商提供的数据并非统一的格式,例如有些历史数据以TXT文本的形式提供,而有些则以XML文件的形式提供,对于数据整体打包出售的数据则以数据库的形式提供。除了提供的数据格式有变化之外,数据的内容也有不同,对于多数股票来说,数据多为股票价格,也就是说,从历史数据中我们能看到每一天的历史报价,而对于复合形式的金融产品而言,数据提供商只提供其历史收益率,即每一天相对于前一天的收益率历史记录。
2.对历史数据的优化处理。上述的历史数据要应用到VaR的数学模型中必须经过修改,一般情况,VaR模型中应用其历史收益率来计算,然而针对不同的类型的金融产品又有差别,例如,对股票来说,一般对其价格取对数,获得其对数收益率,即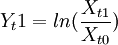 ,Yt1即时间点t1相对于t0的收益率。而以收益率存储的历史数据,没有必要对其进行任何转换。有些金融产品的收益率采取最直接的形式来取得收益率序列,其收益率计算公式为
,Yt1即时间点t1相对于t0的收益率。而以收益率存储的历史数据,没有必要对其进行任何转换。有些金融产品的收益率采取最直接的形式来取得收益率序列,其收益率计算公式为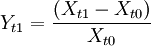 。
。
3.构建盈亏序列(PNL,ProfitandLoss)。盈亏序列是指当前的头寸映射到对应的历史数据序列上,即此金融产品的历史收益率序列上,获得历史上的各个时间点的盈亏值。由此可知,盈亏序列的建立必须满足两个条件,1.已经处理好的历史数据2.当前的头寸。经过处理的历史数据已经经过讨论,当前头寸可以作为参数直接输入获得,当然为了更好的结构性和扩展性的考虑我们可以把头寸写入配置文件中。用数学公式PnL=Position(头寸)*(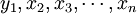 )。
)。
- (二)系统设计
针对上述问题,设计图如下:

由图可知:针对上述问题1,设计一个DataSeries接口,同时两个抽象类FileDataSeries,DatabaseDataSeries实现此接口,且分别对应数据来源:文件和数据库,这样不同格式,不同来源的历史数据均能整合到一起,而对于SimulatePnL不需要知道数据的原始来源以及格式,因为他只需要用到最终的原始有效数据而不必去关心太多的细节。
同理,针对问题2,设计Computer接口,即针对原始数据进行处理,针对不同的数据处理方法设计不同的类,这些类分别实现此接口,当然随着统计方式的变化,新的数据处理方法会被提出,此时只需添加新的类来实现新的方法,而程序的结构不需要改变,而DataSeries的设计思路也是如此。
SimulatePnL的设计是针对问题3的。有了Computer,DataSeries这些数据结构,很容易构造出收益率序列,同时结合头寸(TradedPostion),便可以比较容易的构造出PnL序列。
- (三)VaR的计算
由上述PnL序列,根据数学统计方法,我们可以计算出方差D(X),和标准差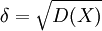 ,根据置信水平α,我们可以得到分位数Zc
,根据置信水平α,我们可以得到分位数Zc
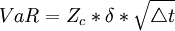
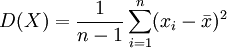
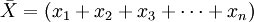 。
。
- (四)配置文件
<VaR>
<ConfidenceLevel>
<confidenceValue>0.95</confidenceValue>
<quantile>1.96</quantile>
</ConfidenceLevel>
<TradedPosition>4,000,0
00</TradedPosition>
<DataSeries>
<DataSourceType>File</DataSourceType>
<DataSourceClass>XMLDataSeries</DataSourceClass>
<SecurityID>SHA:60188</SecurityID>
<FilePath>D:\\data\\ch-60188.xml</FilePath>
</DataSeries>
<Computer>LogNormalComputer</Computer>
</VaR>
由上述的设计类图可知,当VaR计算引擎启动时,Runner从配置文件中读取分位数,头寸等相应参数,当DataSourceType为File时,即数据来源于文件,而DataSourceClass明确指明了用什么样对应的数据处理类来获得历史数据,FilePath指明了数据文件的存储位置。如果DataSourceType为DB时,对应的类会根据SecurityID从数据库中来获得数据序列。Computer指定了对原始数据处理的方式方法类,LogNormalComputer意味着对原始数据进行取对数然后构造对数收益率序列。
- ↑ 李伟杰.浅谈历史模拟法VaR的设计和实现.时代金融.2009年07期






