等距抽样
出自 MBA智库百科(https://wiki.mbalib.com/)
等距抽样也称为:机械抽样\系统抽样( Systematic sampling )、SYS抽样、间隔抽样法(Interval sampling)
目录 |
等距抽样也称为系统抽样、或机械抽样、SYS抽样,它是首先将总体中各单位按一定顺序排列,根据样本容量要求确定抽选间隔,然后随机确定起点,每隔一定的间隔抽取一个单位的一种抽样方式。是纯随机抽样的变种。在系统抽样中,先将总体从1~N相继编号,并计算抽样距离K=N/n。式中N为总体单位总数,n为样本容量。然后在1~K中抽一随机数k1,作为样本的第一个单位,接着取k1+K,k1+2K……,直至抽够n个单位为止。
等距抽样要防止周期性偏差,因为它会降低样本的代表性。例如,军队人员名单通常按班排列,10人一班,班长排第1名,若抽样距离也取10时,则样本或全由士兵组成或全由班长组成。
根据总体单位排列方法,等距抽样的单位排列可分为三类:按有关标志排队、按无关标志排队以及介于按有关标志排队和按无关标志排队之间的按自然状态排列。
按照具体实施等距抽样的作法,等距抽样可分为:直线等距抽样、对称等距抽样和循环等距抽样三种。
| 市场调查方法 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| [编辑] | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
等距抽样的最主要优点是简便易行,且当对总体结构有一定了解时,充分利用已有信息对总体单位进行排队后再抽样,则可提高抽样效率。
等距抽样的特点是:抽出的单位在总体中是均匀分布的,且抽取的样本可少于纯随机抽样。
等距抽样既可以用同调查项目相关的标志排队,也可以用同调查项目无关的标志排队。
采用等距抽样时,必须首先对总体单位按某种标志进行排序,有下列两种排序方法。
(1)按无关标志排序。
即总体单位排列的顺序和所要研究的标志是无关的。如调查职工的收入水平,可按姓氏笔划排列的职工名单进行抽样;工业生产质量检验可按产品生产的时间顺序进行等距抽样等等。一般认为,按无关标志排队的等距抽样是一种抽签法,随机数表法更好的纯随机抽样方式,又称无序系统抽样。
(2)按有关标志排序。
即总体单位排列的顺序与所要研究的标志是有直接关系的。例如,农产量抽样调查时,可按照当年估产或前几年的平均实产由低到高或由高到低的顺序进行抽样。这种按有关标志排队的等距抽样又称有序系统抽样,它能使标志值高低不同的单位,均有可能选入样本,从而提高样本的代表性,减小抽样误差。一般认为有序系统抽样比等比例分层抽样能使样本更均匀地分布在总体中,抽样误差也更小。
当总体单位的顺序排列之后,可选用下列方法进行等距抽样。
(1)随机起点等距抽样。
即在总体分成K段(K=N/n)的前提下,首先从第一段的1至k号总体单位中随机抽选一个样本单位,然后每隔k个单位抽取一个样本单位,直到抽足n个单位为止。这n个单位就构成了一个随机起点的等距样本。这种方法能够保证各个总体单位具有相同的概率被抽到,但是,如果随机起点单位处于每一段的低端或高端,就会导致往后的单位都会处于相应段的低端或高端,从而使抽样出现偏低或偏高的系统误差。
(2)半距起点等距随机抽样。
这种方法又称为中点法抽取样本,它是在总体的第一段,取1,2,…,k号中的中间项为起点,然后再每隔k个单位抽取一个样本单位,直到抽足n个样本单位为止。当总体是按有关标志的大小顺序排列时,采用中点法抽取样本,可提高整个样本对总体的代表性。
(3)随机起点对称等距抽样。
这种方法是在总体第一段随机抽到第i个单位,而在第二段抽取第2k-f+1的单位,在第三段抽取第2k+f的单位,而在第四段抽取第4k-f+1的单位…,以此交替对称进行。可概括为:在总体奇数段抽取第jk+i单位(j=0,2,4…);在总体偶数段抽取第jk-i+1单位(j=2,4…)。这种抽样方法能使处于低端的样本单位与另一段处于高端的样本单位相互搭配,从而抵消或避免抽样中的系统误差。
(4)循环等距抽样。
当N为有限总体而且不能被n所整除,亦即k不是一个整数时,可将总体各单位按顺序排成首尾相接的循环圆形,用N/n确定抽样间隔k,k可以取最接近的整数,然后在第一段的1至后号中抽取一个作为随机起点,再每隔后个单位抽取一个样本单位,直至抽满行个为止。
等距抽样在抽样调查中的应用
在定量抽样调查中,等距抽样常常代替简单随机抽样。由于该抽样方法简单实用,所以应用普遍。等距抽样得到的样本几乎与简单随机抽样得到的样本是相同的。
等距抽样的基本做法是,将总体中的各单元先按一定的顺序排列、编号,然后决定一个间隔,并在此间隔基础上选择被调查的单位个体。
样本距离可通过下面公式确定:样本距离 = 总体单位数∕样本单位数
例如,假设你使用本地电话本并确定样本距离为100 ,那么100个中取1个组成样本。这个公式保证了整个列表的完整性。
等距抽样方式随意用一个起点,例如,如果你把一本电话本作为抽样框,必须随意取出一个号码决定从该页开始翻阅。假设从第5页开始,在该页上再另选一个数决定从该行开始。假定选择从第3行开始,这就决定了实际开始的位置。
等距抽样方式相对于简单随机抽样方式最主要的优势就是经济性。等距抽样方式比简单随机抽样更为简单,花的时间更少,并且花费也少。使用等距抽样方式最大的缺陷在于总体单位的排列上。一些总体单位数可能包含隐蔽的形态或者是“不合格样本”,调查者可能疏忽,把它们抽选为样本。
等距抽样又称为机械抽样或系统抽样,它是将总体各单位按某标志进行排序,然后按固定的间隔来抽取样本单位的抽样组织形式。根据需要抽取的样本单位数n和总体的单位数N,可以计算出等距抽样的间隔大小为
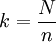
先从排序后序号为1,2,…,k的第一部分中随机抽出第i个单位,然后在序号为k+1,k+2,…,2k的第二部分中抽取第k+i个单位,再从序号为2k+1,2k+2,...,3k的第三部分中抽取第2k+i个单位,依此类推,最后从序号为(n-1)k+1,(n-1)k+2,...,nk的第n部分中抽取第(n-1)k+i个单位,一共n个单位构成样本。
总体排序标志由总体的有关辅助信息确定,与调查标志两者间可以有关也可以无关。如家计调查,按门牌号码排序就是无关标志排序,但是,如果选择的排序标志与实际调查标志间存在密切联系,要比无关标志排序的等距抽样更为优越。如农产量调查按平均亩产量高低排序,职工家计调查按平均工资多少进行排序,都可缩小各单位间的差异程度,有利于提高样本的代表性。
等距抽样的间隔应避免与现象本身的节奏性或循环周期相重合。例如,进行农作物调查时,抽样间隔就应避免与农作物垅长或间距相重合;进行工业产品质量调查时,产品抽样时间间隔不宜和上下班时间相一致,否则,就会因引起系统偏差而影响样本的代表性。
用等距抽样方式抽取一个样本后,就可以计算样本平均数。关键是这个平均数的平均误差如何确定,一般说来,排序后总体被分成n个部分,每一部分包含k个单位,从中随机抽取一个单位,其余单位情况未知,每一部分中的方差不可计算,一般也没有历史资料可以替代它们。因此,直接计算等距抽样的平均误差是有困难的,只能以间接方式计算其近似值,如果据以排序的标志与所要研究的目的没有关系,且第一个单位是随机抽取的,则等距抽样的平均误差就与随机抽样的平均误差相接近。为了方便起见,可以采用简单随机抽样的平均误差代替等距抽样平均误差
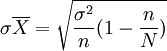
等距抽样一般都是无回置抽样,总体方差σ2未知时,常用样本方差代替。
【例】某块麦地长300米,宽120米,包括120条垅,每垅长300米,现从这块麦地按等距抽样的方式,抽取50个2米长垅为样本进行实割实测。
样本距离为麦垅总长除以样本单位数,即300×120/50=720(米):现从地角一边样本距离一半处抽取第一个样本单位,即从360米前后1米为第一个样本单位,以后每隔720米取一个样本单位,一直抽出50个样本单位为止。实测各样本单位产量如表所示:
| 样本产量X(公斤) | 单位数n | nX | 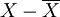 | 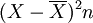
|
|---|---|---|---|---|
| 0.8 | 6 | 4.8 | -0.4 | 0.96 |
| 1 | 12 | 12 | -0.2 | 0.48 |
| 1.2 | 14 | 16.8 | 0 | 0 |
| 1.4 | 12 | 16.8 | 0.2 | 0.48 |
| 1.6 | 6 | 9.6 | 0.4 | 0.96 |
| 合计 | 50 | 60 | — | 2.88 |
试计算平均亩产量的抽样平均误差,并以95%的概率保证估计这块麦地的亩产量和总产量:
解:样本平均产量 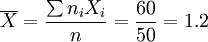 (公斤)
(公斤)
样本单位标准差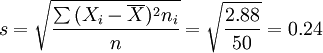 (公斤)
(公斤)
样本单位的抽样平均误差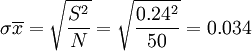 (公斤)
(公斤)
这块麦地的面积是: (平方米),折合为
(平方米),折合为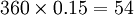 (亩)。
(亩)。
由于样本单位垅长是2米,所以每亩含样本单位数是:
1/2×总垅长÷面积=1/2×36000/54≈333(个)。
平均亩产量=样本平均产量×每亩含样本单位数,即平均亩产量
1.2×18000/54=400(公斤)
平均亩产量的抽样平均误差=每亩含样本单位数×样本单位数的抽样平均误差,即为
18000/54×0.034=11.33(公斤)
由于概率保证是95%,即α = 0.05,则有Zα / 2 = 1.96。那么,亩产量的置信区间是
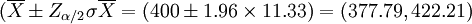
即亩产量估计在377.79公斤到422.21公斤之间。
总产量的置信区间是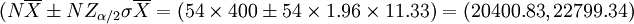
即以95%的概率保证,这块麦地的总产量估计在20401公斤到22799公斤之间。
某企业有职工5000名,现要随机抽取100人进行家庭收入水平调查。
抽取方法:按与研究目的无直接关系的姓名笔划对总体进行排列,把总体划分为K=5000/100=50个相等的间隔,在第1至第50人中随机抽取一名,如抽到第10名,后面间隔依次抽取第60,110,160,210,…直到4960为止,总共抽取50同名职工组成一个抽样总体。







太笼统!!!!1