偏最小二乘法
出自 MBA智库百科(https://wiki.mbalib.com/)
偏最小二乘法(partial least squares method)
目录 |
偏最小二乘法是一种新型的多元统计数据分析方法,它于1983年由伍德(S.Wold)和阿巴诺(C.Albano)等人首次提出。近几十年来,它在理论、方法和应用方面都得到了迅速的发展。
长期以来,模型式的方法和认识性的方法之间的界限分得十分清楚。而偏最小二乘法则把它们有机的结合起来了,在一个算法下,可以同时实现回归建模(多元线性回归)、数据结构简化(主成分分析)以及两组变量之间的相关性分析(典型相关分析)。这是多元统计数据分析中的一个飞跃。
偏最小二乘法在统计应用中的重要性体现在以下几个方面:
偏最小二乘法是一种多因变量对多自变量的回归建模方法。偏最小二乘法可以较好的解决许多以往用普通多元回归无法解决的问题。
偏最小二乘法之所以被称为第二代回归方法,还由于它可以实现多种数据分析方法的综合应用。
主成分回归的主要目的是要提取隐藏在矩阵X中的相关信息,然后用于预测变量Y的值。这种做法可以保证让我们只使用那些独立变量,噪音将被消除,从而达到改善预测模型质量的目的。但是,主成分回归仍然有一定的缺陷,当一些有用变量的相关性很小时,我们在选取主成分时就很容易把它们漏掉,使得最终的预测模型可靠性下降,如果我们对每一个成分进行挑选,那样又太困难了。
偏最小二乘回归可以解决这个问题。它采用对变量X和Y都进行分解的方法,从变量X和Y中同时提取成分(通常称为因子),再将因子按照它们之间的相关性从大到小排列。现在,我们要建立一个模型,我们只要决定选择几个因子参与建模就可以了
H Wold作为PLS的创始人,在70年代的经济学研究中引入了偏最小二乘法进行路径分析,创建了非线性迭代偏最小二乘算法(Nonlinear Iterative Partial Least Squares algorithm,NIPALS),至今仍然是PLS中最常用和核心的算法。HW.old的儿子S Wold和C Albano等人在1983年提出了偏最小二乘回归的概念,用来解决计量化学中变量存在多重共线性,解释变量个数大于样本量的问题,如在光谱数据分析中。上世纪90年代,出现了多种NIPALS算法的扩展,如迭代法、特征根法、奇异值分解法等。1993年,de Jong提出了一种与NIPALS不同的算法,称为简单偏最小二乘(Simple Partial Least Squares,SIMPLS)。1996年,在法国召开了偏最小二乘回归方法的理论和应用国际学术专题研讨会,就PLS的最新进展,以及PLS在计量化学、工业设计、市场分析等领域的应用进行了交流,极大的促进了PLS的算法研究和应用研究。目前,PLS在化学、经济学、生物医学、社会学等领域都有很好的应用。
PLS在上世纪90年代引入中国,在经济学、机械控制技术、药物设计及计量化学等方面有所应用,但是在生物医学上偏最小二乘法涉及相对较少。对该方法的各种算法和在实际应用中的介绍也不系统,国内已有学者在这方面做了一些努力,但作为一种新兴的多元统计方法,还不为人所熟知。
偏最小二乘回归是对多元线性回归模型的一种扩展,在其最简单的形式中,只用一个线性模型来描述独立变量Y与预测变量组X之间的关系:
Y = b0 + b1X1 + b2X2 + ... + bpXp
在方程中,b0是截距,bi的值是数据点1到p的回归系数。
例如,我们可以认为人的体重是他的身高、性别的函数,并且从各自的样本点中估计出回归系数,之后,我们从测得的身高及性别中可以预测出某人的大致体重。对许多的数据分析方法来说,最大的问题莫过于准确的描述观测数据并且对新的观测数据作出合理的预测。
多元线性回归模型为了处理更复杂的数据分析问题,扩展了一些其他算法,象判别式分析,主成分回归,相关性分析等等,都是以多元线性回归模型为基础的多元统计方法。这些多元统计方法有两点重要特点,即对数据的约束性:
变量X和变量Y的因子都必须分别从X'X和Y'Y矩阵中提取,这些因子就无法同时表示变量X和Y的相关性。
预测方程的数量永远不能多于变量Y跟变量X的数量。
偏最小二乘回归从多元线性回归扩展而来时却不需要这些对数据的约束。在偏最小二乘回归中,预测方程将由从矩阵Y'XX'Y中提取出来的因子来描述;为了更具有代表性,提取出来的预测方程的数量可能大于变量X与Y的最大数。
简而言之,偏最小二乘回归可能是所有多元校正方法里对变量约束最少的方法,这种灵活性让它适用于传统的多元校正方法所不适用的许多场合,例如一些观测数据少于预测变量数时。并且,偏最小二乘回归可以作为一种探索性的分析工具,在使用传统的线性回归模型之前,先对所需的合适的变量数进行预测并去除噪音干扰。
因此,偏最小二乘回归被广泛用于许多领域来进行建模,象化学,经济学,医药,心理学和制药科学等等,尤其是它可以根据需要而任意设置变量这个优点更加突出。在化学计量学上,偏最小二乘回归已作为一种标准的多元建模工具。
作为一个多元线性回归方法,偏最小二乘回归的主要目的是要建立一个线性模型:Y=XB+E,其中Y是具有m个变量、n个样本点的响应矩阵,X是具有p个变量、n个样本点的预测矩阵,B是回归系数矩阵,E为噪音校正模型,与Y具有相同的维数。在通常情况下,变量X和Y被标准化后再用于计算,即减去它们的平均值并除以标准偏差。
偏最小二乘回归和主成分回归一样,都采用得分因子作为原始预测变量线性组合的依据,所以用于建立预测模型的得分因子之间必须线性无关。例如:假如我们现在有一组响应变量Y(矩阵形式)和大量的预测变量X(矩阵形式),其中有些变量严重线性相关,我们使用提取因子的方法从这组数据中提取因子,用于计算得分因子矩阵:T=XW,最后再求出合适的权重矩阵W,并建立线性回归模型:Y=TQ+E,其中Q是矩阵T的回归系数矩阵,E为误差矩阵。一旦Q计算出来后,前面的方程就等价于Y=XB+E,其中B=WQ,它可直接作为预测回归模型。
偏最小二乘回归与主成分回归的不同之处在于得分因子的提取方法不同,简而言之,主成分回归产生的权重矩阵W反映的是预测变量X之间的协方差,偏最小二乘回归产生的权重矩阵W反映的是预测变量X与响应变量Y之间的协方差。
在建模当中,偏最小二乘回归产生了pxc的权重矩阵W,矩阵W的列向量用于计算变量X的列向量的nxc的得分矩阵T。不断的计算这些权重使得响应与其相应的得分因子之间的协方差达到最大。普通最小二乘回归在计算Y在T上的回归时产生矩阵Q,即矩阵Y的载荷因子(或称权重),用于建立回归方程:Y=TQ+E。一旦计算出Q,我们就可以得出方程:Y=XB+E,其中B=WQ,最终的预测模型也就建立起来了。
案例一:偏最小二乘法在顾客满意度评价中的运用[1]
一、顾客满意度指数含义及研究意义
所谓顾客满意度,是指顾客通过对一个产品或服务的感知效果/结果与其期望值相比较后所形成的愉悦或失望的感觉状态,即是消费者对商品、品牌或企业的满意程度。顾客满意度理论是2O世纪九十年代管理科学的最新发展之一,它抓住了管理科学“以人为本”的本质。在市场经济高度发达的今天。任何一个企业能否以市场为中心,以顾客为中心,让顾客满意,决定着该企业能否在市场上立足,决定着企业所占市场份额的大小。因而,对顾客满意度的研究对企业来说十分重要,有着现实的指导意义。
二、顾客满意度指数模型及偏最小二乘法操作原理
对顾客满意度指数模型的研究最早起于瑞典,发展于美国。瑞典率先于1989年建立了全国性的顾客满意度指数,美国和欧盟相继建立了各自的顾客满意度指数——美国顾满意度指数(ACSI)和欧洲顾客满意度指数(ECSI)。另外。新西兰、加拿大和台湾等国家和地区也在几个重要的行业建立了顾客满意度指数。在这些模型中几乎都涉及顾客期望、感知质量、顾客满意度、顾客抱怨和顾客忠诚度这些指标(图)。

然而,在现实的操作中,这些都是定性指标,很难进行衡量,而且还有一些隐变量也不易观测,这些问题为建立顾客满意度模型带来了困难。但是。偏最小二乘法(PLS)能克服这些问题,得到比较好的估计效果。偏最小二乘法类似于主成分回归的方式克服多重共线性的问题。它是将主成分分析与多元回归结合起来的叠代估计。是一种因果建模的方法。瑞典、美国和欧盟模型都使用这种方法进行估计。在ACSI模型估计中,该方法对不同隐变量的测量变量子集抽取主成分,放在回归模型系统中使用,然后调整主成分权数,以最大化模型的预测能力。
三、偏最小二乘法在顾客满意度指数中的运用
对于包含隐变量的结构方程模型,目前最经常使用的估计方法是PLS方法和LISP,EL方法。
设在顾客满意度测评中有q个因变量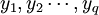 和P个自变量
和P个自变量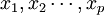 。为了研究因变量和自变量之间的统计关系,我们观察了n个样本点,由此构造了自变量和因变量的数据表:
。为了研究因变量和自变量之间的统计关系,我们观察了n个样本点,由此构造了自变量和因变量的数据表:
![X=[x_1,x_2L,x_p]_{nxp}=\begin{cases}X_{11} X_{12} L X_{1p}\\X_{21} X_{22} L X_{2p}\\L L L L\\X_{n1} X_{n2} L X_{np}\end{cases}](/w/images/math/d/a/0/da0984285ba7aa375da1154361435b86.png)
![Y=[y_1,y_2L,y_p]_{nxp}=\begin{cases}y_{11} y_{12} L y_{1p}\\y_{21} y_{22} L y_{2p}\\L L L L\\y_{n1} y_{n2} L y_{np}\end{cases}](/w/images/math/a/6/8/a686da36b7c2947c96acb86ae309b454.png)
偏最小二乘法回归的做法是首先在自变量集中提取第一潜因子t1(t1是 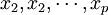 的线性组合,且尽可能多地提取原自变量集中的变异信息,比如第一主分量);同时,在因变量集中也提取第一潜因u1(u1为
的线性组合,且尽可能多地提取原自变量集中的变异信息,比如第一主分量);同时,在因变量集中也提取第一潜因u1(u1为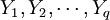 的线性组合),并要求t1和u1相关程度达到最大。然后建立因变量Y与t1的回归,如果回归方程已达到满意的精度,则算法终止。否则继续进行第二轮潜在因子的提取,直到能达到满意的精度为止。若最终对自变量集提取1个潜因子
的线性组合),并要求t1和u1相关程度达到最大。然后建立因变量Y与t1的回归,如果回归方程已达到满意的精度,则算法终止。否则继续进行第二轮潜在因子的提取,直到能达到满意的精度为止。若最终对自变量集提取1个潜因子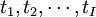 的回归式,然后再表示为Y与原自变量的回归方程式。
的回归式,然后再表示为Y与原自变量的回归方程式。
PLS的算法步骤如下:
1、把自变量和因变量都进行标准化处理,以消除测量时由于采用不同的量纲和数量级所引起的差异。标准化处理的公式是:
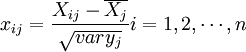 ;
;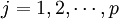
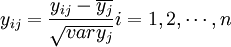 ;
;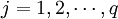
X经标准化处理后的数据矩阵记为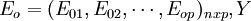 经标准化处理后数据矩阵为
经标准化处理后数据矩阵为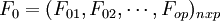 。
。
2、提取主成分,逐步回归法。记t1是Eo的第一个成分。t1 = E0w1,w1是E0的第一个轴。它是一个单位向量,即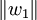 ;u1是F0的第一个成分,u1 = Foc1,c1是F0的第一个轴,它是一个单位向量,即
;u1是F0的第一个成分,u1 = Foc1,c1是F0的第一个轴,它是一个单位向量,即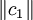 。
。
在建立顾客满意度指数建模时,要求t1和u1能很好地分别代表自变量x和因变量Y中的数据变异信息,根据主成分分析原理应该有: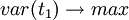
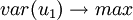
而另一方面,在顾客满意度指数建模时,又要求t1对u1具有最大的解释能力,由典型相关分析思路,t1和u1的相关程度应达到最大值,即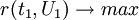 。实质上是要求t1,u1的协方差达到最大。
。实质上是要求t1,u1的协方差达到最大。
因此,顾客满意度指数测评模型的偏最小二乘回归的正规数学表达式为求下列优化问题.即 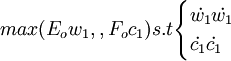 第一步,从X中提取第一主成分t_1(t_1为向量),提取的原则是t_1与Y之间的协方差达到最大,即求矩阵
第一步,从X中提取第一主成分t_1(t_1为向量),提取的原则是t_1与Y之间的协方差达到最大,即求矩阵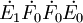 的最大特征值所对应的特征向量w1,然后求成分t1和残差矩阵E1,其计算公式如下:
的最大特征值所对应的特征向量w1,然后求成分t1和残差矩阵E1,其计算公式如下: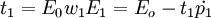 式中
式中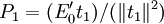 ;第二步,求矩阵
;第二步,求矩阵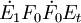 的最大特征值所对应的特征向量w2,然后求成分t2和残差矩阵E2,其计算公式:
的最大特征值所对应的特征向量w2,然后求成分t2和残差矩阵E2,其计算公式:
t2 = E1w2
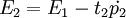 式中
式中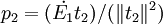
……
第m步,重复以上步骤,求成分tm = Em − 1wm,这里wm是矩阵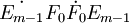 的最大特征值所对应的特征向量,直到提取的主成分t_m对模型预测效果的边际贡献不显著为止。
的最大特征值所对应的特征向量,直到提取的主成分t_m对模型预测效果的边际贡献不显著为止。
如果根据交叉有效性,确定共抽取m个成分t1,t2,L,tm可以得到一个满意的预测模型,则求F0在t1,t2,L,tm上的普通最小二乘回归方程为。
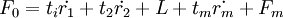
最后,将还原成为Y * 关于x * = Eoj的回归方程形式,即,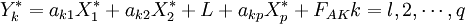
就得到了顾客满意度指数测评模型。
运用偏最小二乘法对顾客满意度指数进行估计和评析,能较好地估计出顾客满意度测评模型,从而帮助企业发现企业运行中的薄弱环节,对复杂多变的市场了如指掌,推动企业经营体制和机制的改革,帮助企业制定正确的发展战略和市场政策。
- ↑ 薛艳.偏最小二乘法在顾客满意度评价中的运用[J].合作经济与科技,2006,(7)

评论(共12条)
举几个实例分析分析,让我们学的人更明白,谢谢
增加了新的案例和新的内容,希望对您有帮助!
不要列出具体的数学算法,很多MBA学生对那个不敢兴趣。只简单说说1.什么情况下用偏最小二乘法,而不用其他方法,比如SEM,2.偏最小二乘法与最大似然估计是什么关系,区别何在,3.用什么软件能做出最小二乘法,软件间差异如何。等等。这些问题可能对学生帮助更大。
不要列出具体的数学算法,很多MBA学生对那个不敢兴趣。只简单说说1.什么情况下用偏最小二乘法,而不用其他方法,比如SEM,2.偏最小二乘法与最大似然估计是什么关系,区别何在,3.用什么软件能做出最小二乘法,软件间差异如何。等等。这些问题可能对学生帮助更大。
难怪各种预测模型被很多MBA学生滥用的一塌糊涂,就是因为连具体的算法都不明白,只会拿来就用,也不管用的对不对
难怪各种预测模型被很多MBA学生滥用的一塌糊涂,就是因为连具体的算法都不明白,只会拿来就用,也不管用的对不对
樓上說得好
难怪各种预测模型被很多MBA学生滥用的一塌糊涂,就是因为连具体的算法都不明白,只会拿来就用,也不管用的对不对
同意






非常好,我要下载