最大似然估計
出自 MBA智库百科(https://wiki.mbalib.com/)
最大似然估計(Maximum Likelihood,ML)
目錄 |
最大似然估計是一種統計方法,它用來求一個樣本集的相關概率密度函數的參數。這個方法最早是遺傳學家以及統計學家羅納德·費雪爵士在1912年至1922年間開始使用的。
“似然”是對likelihood 的一種較為貼近文言文的翻譯,“似然”用現代的中文來說即“可能性”。故而,若稱之為“最大可能性估計”則更加通俗易懂。
最大似然法明確地使用概率模型,其目標是尋找能夠以較高概率產生觀察數據的系統發生樹。最大似然法是一類完全基於統計的系統發生樹重建方法的代表。該方法在每組序列比對中考慮了每個核苷酸替換的概率。
例如,轉換出現的概率大約是顛換的三倍。在一個三條序列的比對中,如果發現其中有一列為一個C,一個T和一個G,我們有理由認為,C和T所在的序列之間的關係很有可能更接近。由於被研究序列的共同祖先序列是未知的,概率的計算變得複雜;又由於可能在一個位點或多個位點發生多次替換,並且不是所有的位點都是相互獨立,概率計算的複雜度進一步加大。儘管如此,還是能用客觀標準來計算每個位點的概率,計算表示序列關係的每棵可能的樹的概率。然後,根據定義,概率總和最大的那棵樹最有可能是反映真實情況的系統發生樹。
給定一個概率分佈D,假定其概率密度函數(連續分佈)或概率聚集函數(離散分佈)為fD,以及一個分佈參數θ,我們可以從這個分佈中抽出一個具有n個值的採樣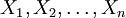 ,通過利用fD,我們就能計算出其概率:
,通過利用fD,我們就能計算出其概率:
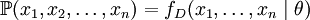
但是,我們可能不知道θ的值,儘管我們知道這些採樣數據來自於分佈D。那麼我們如何才能估計出θ呢?一個自然的想法是從這個分佈中抽出一個具有n個值的採樣X1,X2,...,Xn,然後用這些採樣數據來估計θ.
一旦我們獲得,我們就能從中找到一個關於θ的估計。最大似然估計會尋找關於 θ的最可能的值(即,在所有可能的θ取值中,尋找一個值使這個採樣的“可能性”最大化)。這種方法正好同一些其他的估計方法不同,如θ的非偏估計,非偏估計未必會輸出一個最可能的值,而是會輸出一個既不高估也不低估的θ值。
要在數學上實現最大似然估計法,我們首先要定義可能性:
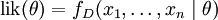
並且在θ的所有取值上,使這個[[函數最大化。這個使可能性最大的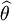 值即被稱為θ的最大似然估計。
值即被稱為θ的最大似然估計。
- 這裡的可能性是指
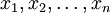 不變時,關於θ的一個函數。
不變時,關於θ的一個函數。
- 最大似然估計函數不一定是惟一的,甚至不一定存在。
考慮一個拋硬幣的例子。假設這個硬幣正面跟反面輕重不同。我們把這個硬幣拋80次(即,我們獲取一個採樣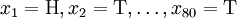 並把正面的次數記下來,正面記為H,反面記為T)。並把拋出一個正面的概率記為p,拋出一個反面的概率記為1 − p(因此,這裡的p即相當於上邊的θ)。假設我們拋出了49個正面,31 個反面,即49次H,31次T。假設這個硬幣是我們從一個裝了三個硬幣的盒子裡頭取出的。這三個硬幣拋出正面的概率分別為p = 1 / 3, p = 1 / 2, p = 2 / 3. 這些硬幣沒有標記,所以我們無法知道哪個是哪個。使用最大似然估計,通過這些試驗數據(即採樣數據),我們可以計算出哪個硬幣的可能性最大。這個可能性函數取以下三個值中的一個:
並把正面的次數記下來,正面記為H,反面記為T)。並把拋出一個正面的概率記為p,拋出一個反面的概率記為1 − p(因此,這裡的p即相當於上邊的θ)。假設我們拋出了49個正面,31 個反面,即49次H,31次T。假設這個硬幣是我們從一個裝了三個硬幣的盒子裡頭取出的。這三個硬幣拋出正面的概率分別為p = 1 / 3, p = 1 / 2, p = 2 / 3. 這些硬幣沒有標記,所以我們無法知道哪個是哪個。使用最大似然估計,通過這些試驗數據(即採樣數據),我們可以計算出哪個硬幣的可能性最大。這個可能性函數取以下三個值中的一個:
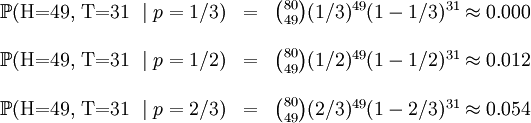
我們可以看到當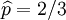 時,可能性函數取得最大值。這就是p的最大似然估計.
時,可能性函數取得最大值。這就是p的最大似然估計.
現在假設例子1中的盒子中有無數個硬幣,對於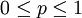 中的任何一個p, 都有一個拋出正面概率為p的硬幣對應,我們來求其可能性函數的最大值:
中的任何一個p, 都有一個拋出正面概率為p的硬幣對應,我們來求其可能性函數的最大值:
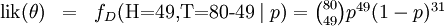
其中.
我們可以使用微分法來求最值。方程兩邊同時對p取微分,並使其為零。
![\begin{matrix} 0 & = & \frac{d}{dp} \left( \binom{80}{49} p^{49}(1-p)^{31} \right) \\ & & \\ & \propto & 49p^{48}(1-p)^{31} - 31p^{49}(1-p)^{30} \\ & & \\ & = & p^{48}(1-p)^{30}\left[ 49(1-p) - 31p \right] \\ \end{matrix}](/w/images/math/f/4/3/f43c984e21445732edf403445fe32ea9.png)
在不同比例參數值下一個二項式過程的可能性曲線 t = 3, n = 10;其最大似然估計值發生在其眾數(數學)併在曲線的最大值處。
其解為p = 0, p = 1,以及p = 49 / 80. 使可能性最大的解顯然是p = 49 / 80(因為p = 0 和p = 1 這兩個解會使可能性為零)。因此我們說最大似然估計值為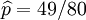 .
.
這個結果很容易一般化。只需要用一個字母t代替49用以表達伯努利試驗中的被觀察數據(即樣本)的'成功'次數,用另一個字母n代表伯努利試驗的次數即可。使用完全同樣的方法即可以得到最大似然估計值:
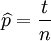
對於任何成功次數為t,試驗總數為n的伯努利試驗。
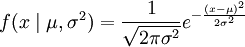
其n個正態隨機變數的採樣的對應密度函數(假設其獨立並服從同一分佈)為:
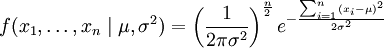
或:
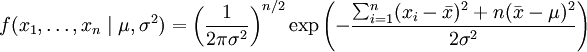 ,
,
這個分佈有兩個參數:μ,σ2. 有人可能會擔心兩個參數與上邊的討論的例子不同,上邊的例子都只是在一個參數上對可能性進行最大化。實際上,在兩個參數上的求最大值的方法也差不多:只需要分別把可能性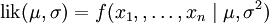 在兩個參數上最大化即可。當然這比一個參數麻煩一些,但是一點也不複雜。使用上邊例子同樣的符號,我們有θ = (μ,σ2).
在兩個參數上最大化即可。當然這比一個參數麻煩一些,但是一點也不複雜。使用上邊例子同樣的符號,我們有θ = (μ,σ2).
最大化一個似然函數同最大化它的自然對數是等價的。因為自然對數log是一個連續且在似然函數的值域內嚴格遞增的函數。[註意:可能性函數(似然函數)的自然對數跟信息熵以及Fisher信息聯繫緊密。求對數通常能夠一定程度上簡化運算,比如在這個例子中可以看到:
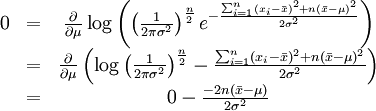
這個方程的解是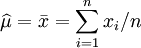 . 這的確是這個函數的最大值,因為它是μ裡頭惟一的拐點並且二階導數嚴格小於零。
. 這的確是這個函數的最大值,因為它是μ裡頭惟一的拐點並且二階導數嚴格小於零。
同理,我們對σ求導,並使其為零。
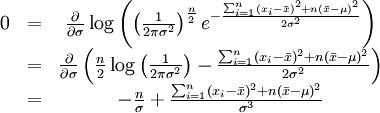
這個方程的解是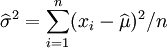 .
.
因此,其關於θ = (μ,σ2)的最大似然估計為:
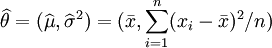 .
.
如果 是 θ的一個最大似然估計,那麼α = g(θ)的最大似然估計是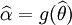 . 函數 g 無需是一個——映射。
. 函數 g 無需是一個——映射。
最大似然估計函數在採樣樣本總數趨於無窮的時候達到最小方差(其證明可見於Cramer-Rao lower bound)。當最大似然估計非偏時,等價的,在極限的情況下我們可以稱其有最小的均方差。對於獨立的觀察來說,最大似然估計函數經常趨於正態分佈。
最大似然估計的非偏估計偏差是非常重要的。考慮這樣一個例子,標有1到n的n張票放在一個盒子中。從盒子中隨機抽取票。如果n是未知的話,那麼n的最大似然估計值就是抽出的票上標有的n,儘管其期望值的只有(n + 1) / 2. 為了估計出最高的n值,我們能確定的只能是n值不小於抽出來的票上的值。
最大似然估計的一般求解步驟[1]
基於對似然函數L(θ)形式(一般為連乘式且各因式>0)的考慮,求θ的最大似然估計的一般步驟如下:
(1)寫出似然函數
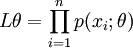 (總體X為離散型時)
(總體X為離散型時)
或 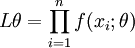 (總體X為連續型時)
(總體X為連續型時)
(2)對似然函數兩邊取對數有
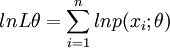
或 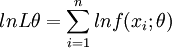
(3)對lnL\theta求導數並令之為0:
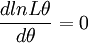
此方程為對數似然方程。解對數似然方程所得,即為未知參數 的最大似然估計值。
例1
設總體X~N(μ,σ2),μ,σ2為未知參數,X1,X2...,Xn是來自總體X的樣本,X1,X2...,Xn是對應的樣本值,求μ與σ2的最大似然估計值。
解 X的概率密度為
f(x;μ,σ2)=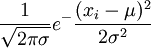 (
(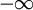 <x<+
<x<+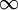 ),
),
可得似然函數如下:
L(μ,σ2)=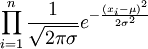
取對數,得
lnL(μ,σ2)=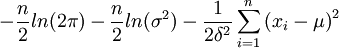
令
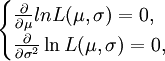
可得
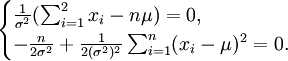
解得
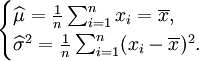
故μ和δ2的最大似然估計量分別為
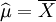 ,
,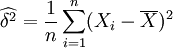
- ↑ 王翠香編著.概率統計.北京大學出版社,2010.02







例子好難哦~ 不理解~ 哎 我太淺薄了