时间序列预测法
出自 MBA智库百科(https://wiki.mbalib.com/)
时间序列预测法(Time Series Forecasting Method)
目录 |
一种历史资料延伸预测,也称历史引伸预测法。是以时间数列所能反映的社会经济现象的发展过程和规律性,进行引伸外推,预测其发展趋势的方法。
时间序列,也叫时间数列、历史复数或动态数列。它是将某种统计指标的数值,按时间先后顺序排到所形成的数列。时间序列预测法就是通过编制和分析时间序列,根据时间序列所反映出来的发展过程、方向和趋势,进行类推或延伸,借以预测下一段时间或以后若干年内可能达到的水平。其内容包括:收集与整理某种社会现象的历史资料;对这些资料进行检查鉴别,排成数列;分析时间数列,从中寻找该社会现象随时间变化而变化的规律,得出一定的模式;以此模式去预测该社会现象将来的情况。
第一步 收集历史资料,加以整理,编成时间序列,并根据时间序列绘成统计图。时间序列分析通常是把各种可能发生作用的因素进行分类,传统的分类方法是按各种因素的特点或影响效果分为四大类:(1)长期趋势;(2)季节变动;(3)循环变动;(4)不规则变动。
第二步 分析时间序列。时间序列中的每一时期的数值都是由许许多多不同的因素同时发生作用后的综合结果。
第三步 求时间序列的长期趋势(T)季节变动(s)和不规则变动(I)的值,并选定近似的数学模式来代表它们。对于数学模式中的诸未知参数,使用合适的技术方法求出其值。
第四步 利用时间序列资料求出长期趋势、季节变动和不规则变动的数学模型后,就可以利用它来预测未来的长期趋势值T和季节变动值s,在可能的情况下预测不规则变动值I。然后用以下模式计算出未来的时间序列的预测值Y:
加法模式T+S+I=Y
乘法模式T×S×I=Y
如果不规则变动的预测值难以求得,就只求长期趋势和季节变动的预测值,以两者相乘之积或相加之和为时间序列的预测值。如果经济现象本身没有季节变动或不需预测分季分月的资料,则长期趋势的预测值就是时间序列的预测值,即T=Y。但要注意这个预测值只反映现象未来的发展趋势,即使很准确的趋势线在按时间顺序的观察方面所起的作用,本质上也只是一个平均数的作用,实际值将围绕着它上下波动。
时间序列分析基本特征[1]
1.时间序列分析法是根据过去的变化趋势预测未来的发展,它的前提是假定事物的过去延续到未来。
时间序列分析,正是根据客观事物发展的连续规律性,运用过去的历史数据,通过统计分析,进一步推测未来的发展趋势。事物的过去会延续到未来这个假设前提包含两层含义:一是不会发生突然的跳跃变化,是以相对小的步伐前进;二是过去和当前的现象可能表明现在和将来活动的发展变化趋向。这就决定了在一般情况下,时间序列分析法对于短、近期预测比较显著,但如延伸到更远的将来,就会出现很大的局限性,导致预测值偏离实际较大而使决策失误。
2.时间序列数据变动存在着规律性与不规律性
时间序列中的每个观察值大小,是影响变化的各种不同因素在同一时刻发生作用的综合结果。从这些影响因素发生作用的大小和方向变化的时间特性来看,这些因素造成的时间序列数据的变动分为四种类型。
(1)趋势性:某个变量随着时间进展或自变量变化,呈现一种比较缓慢而长期的持续上升、下降、停留的同性质变动趋向,但变动幅度可能不相等。
(2)周期性:某因素由于外部影响随着自然季节的交替出现高峰与低谷的规律。
(3)随机性:个别为随机变动,整体呈统计规律。
(4)综合性:实际变化情况是几种变动的叠加或组合。预测时设法过滤除去不规则变动,突出反映趋势性和周期性变动。
时间序列预测法可用于短期预测、中期预测和长期预测。根据对资料分析方法的不同,又可分为:简单序时平均数法、加权序时平均数法、移动平均法、加权移动平均法、趋势预测法、指数平滑法、季节性趋势预测法、市场寿命周期预测法等。
简单序时平均数法 也称算术平均法。即把若干历史时期的统计数值作为观察值,求出算术平均数作为下期预测值。这种方法基于下列假设:“过去这样,今后也将这样”,把近期和远期数据等同化和平均化,因此只能适用于事物变化不大的趋势预测。如果事物呈现某种上升或下降的趋势,就不宜采用此法。
加权序时平均数法 就是把各个时期的历史数据按近期和远期影响程度进行加权,求出平均值,作为下期预测值。
简单移动平均法 就是相继移动计算若干时期的算术平均数作为下期预测值。
加权移动平均法 即将简单移动平均数进行加权计算。在确定权数时,近期观察值的权数应该大些,远期观察值的权数应该小些。
上述几种方法虽然简便,能迅速求出预测值,但由于没有考虑整个社会经济发展的新动向和其他因素的影响,所以准确性较差。应根据新的情况,对预测结果作必要的修正。
指数平滑法 即根据历史资料的上期实际数和预测值,用指数加权的办法进行预测。此法实质是由内加权移动平均法演变而来的一种方法,优点是只要有上期实际数和上期预测值,就可计算下期的预测值,这样可以节省很多数据和处理数据的时间,减少数据的存储量,方法简便。是国外广泛使用的一种短期预测方法。
季节趋势预测法 根据经济事物每年重复出现的周期性季节变动指数,预测其季节性变动趋势。推算季节性指数可采用不同的方法,常用的方法有季(月)别平均法和移动平均法两种:a.季(月)别平均法。就是把各年度的数值分季(或月)加以平均,除以各年季(或月)的总平均数,得出各季(月)指数。这种方法可以用来分析生产、销售、原材料储备、预计资金周转需要量等方面的经济事物的季节性变动;b.移动平均法。即应用移动平均数计算比例求典型季节指数。
市场寿命周期预测法 就是对产品市场寿命周期的分析研究。例如对处于成长期的产品预测其销售量,最常用的一种方法就是根据统计资料,按时间序列画成曲线图,再将曲线外延,即得到未来销售发展趋势。最简单的外延方法是直线外延法,适用于对耐用消费品的预测。这种方法简单、直观、易于掌握。
案例一:可提费用的时间序列预测[2]
一、可提费用概述
可提费用是人寿保险保费收人中重要的组成部分,是目前国内人寿保险公司运营的基本保证。它的变化规律,对于保险公司的资金计划、预算管理、以及发展规划等行为起到至关重要的作用.因此合理、相对准确地预测可提费用对于保险公司在管理决策和发展规划方面起到重要的作用。
可提费用与诸多因素有关,且这些因素多属于不确定性因素,如:市场的成长性、客户的持续缴费(选择期缴方式的客户)、季节性因素、新产品的开发与投放、央行的利率政策等,而且由于不同产品类型的收入规律和不同国家的经济、社会水平不同,规律也不同,又因为人寿保险的产品保障类型组合非常复杂,统一的预测模式几乎不可能实现.但研究结果表明,可提费用的逐月累计余额构成的时间序列是一个有规则的周期波动,具有明显的趋势性和季节性,月度数据周期为12,这是由中国会计财年决定的(也有一些业务收入的月发生具有明显的季节因素),利用季节模型还可有效刻画年内的波动规律。
二、时间序列预测法
1.逐步自回归(StepAR)模型:StepAR模型是有趋势、季节因素数据的模型类。
2.Winters Method—Additive模型:它是将时势和乘法季节因素相结合,考虑序列中有规律节波动。
3.ARlMA模型:它是处理带有趋势、季节因平稳随机项数据的模型类[3]。
4.Winters Method—Muhiplicative模型:该方将时同趋势和乘法季节因素相结合,考虑序列规律的季节波动。时间趋势模型可根据该序列律的季节波动对该趋势进行修正。为了能捕捉到季节性,趋势模型包含每个季节的一个季节参季节因子采用乘法季节因子。随机时间序列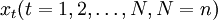 整理汇总历史上各类保险的数据得到逐月的数据,Winters Method-Multiplicative模型表示为
整理汇总历史上各类保险的数据得到逐月的数据,Winters Method-Multiplicative模型表示为
xt = (a + bt)s(t) + εt (1)
其中a和b为趋势参数,s(t)为对应于时刻t的这个季节选择的季节参数,修正方程为。
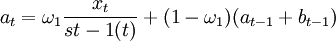 ,
,
bt = ω2(at − at − 1) + (1 − ω2)bt − 1 (2)
其中:xt,at,bt,分别为序列在时刻t的实测值、平滑值和平滑趋势s{t-1}(t)选择在季节因子被修正之前对应于时刻t的季节因子的过去值。
在该修正系统中,趋势多项式在当前周期中总是被中心化,以便在t以后的时间里预报值的趋势多项式的截距参数总是修正后的截距参数at。向前τ个周期的预报值是。
xt + τ = (at + btτ)st(t + τ)(3)
当季节在数据中改变时季节参数被修正,它使用季节实测值与预报值比率的平均值。
5.GARCH(ARCH)模型
带自相关扰动的回归模型为。
xt = ξtβ + vt,
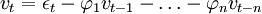 ,
,
εt = N(0,σ2) (4)
其中:xt为因变量;ξt为回归因子构成的列向量;\beta为结构参数构成的列向量;εt为均值是0、方差是一的独立同分布正态随机变量。
服从GARCH过程的序列xt,对于t时刻X的条件分布记为
xt | φt − 1˜N(0,ht) (5)
其中\phi_{t-1}表示时间t-1前的所有可用信息,条件方差。
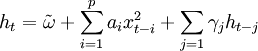 (6)。
(6)。
其中p≥0,q>0,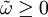 ,
,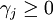 。
。
当p=0时,GARCH(p,q)模型退化为ARCH(p)模型,ARCH参数至少要有一个不为0。
GARCH回归模型可写成
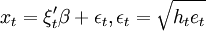 ,
,
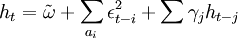 ,
,
et˜ N(0,1) (7)
也可以考虑服从自回归过程的扰动或带有GARCH误差的模型,即AR(n)-GARCH(p,q)。
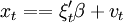 ,
,
,
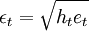
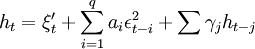 (8)
(8)
三、预测分析与结论
在具体应用时,可在使用模型前依据数据特征对数据进行一些变换,如Log,Logistic,Cox—Box等变换。实际数据如表所示,数据是年内累计的。

其数据散布图如图所示,其中纵轴表示“当年可提费用”,时间从2001-02~2003-11,共计34个月。

从图中可以看出,该序列具有明显的趋势性和季节性(周期).在具体应用时.可在使用模型之前依据数据特征对数据进行一些变换,如Log,Logistic,Cox-Box等变换.得到各个模型拟合的残差平方和统计量、R-Square统计量和AIC统计量。如下表所示。

其中GARCH模型SAS系统采用极大似然方法.由于随机误差的方差太大,极大似然不能被执行,GARCH模型不能被建立.综合考虑模型{敛合的残差平方和统计量、R-Square统计量和AIC统计量,可以看出在各个预报模型中稳健的方法为Log ARIMA(1,1,0)×(O,1,O),因此选择Log ARIMA(1,l,0)×(O,1.o)预报模型,具体应用过程中,在模拟ARIMA(1,1,0)×(O,l,0)模型之前对数据进行Log变换,即yt=ln(xt)。那么总体可提费用的数据序列{xt}t=1,2,…,N,N=34)由Log ARIMA(1,1.0)X(0.1,0)预报模型进行预测所产生的参数估计如下表

从而,对数据Log变换后拟合参数的模型为
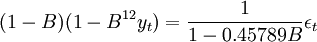 (9)
(9)
其中得到的对未来12个月的预报值段95%置信限(下表)和预报图及95%置信限图(下图),历史数据(2001-02~2003-11)包括在用于预报图所给范围的图形里,在预报周期的开始位置有一条参考线。


然后,利用得到的外推预报值{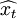 (l)},将其与实际值相比较,得到实际精度.将各个模型得到的003-12,2004-01,2004-02,2004-03预测值与实数据比较的误差分析结果如上表所示。
(l)},将其与实际值相比较,得到实际精度.将各个模型得到的003-12,2004-01,2004-02,2004-03预测值与实数据比较的误差分析结果如上表所示。
从误差分析看出,理论最佳模型具有次优的实际预测误差,而理论次优模型具有最优的实际预测误差。
某一城市从1984年到1994年中,每年参加体育锻炼的入口数,排列起来,共有10个数据构成一个时间序列。我们希望用某个数学模型,根据这10个历史数据,来预测1995年或以后若干年中每年的体育锻炼人数是多少,以便于该城市领导人制订一个有关体育健身的发展战略或整个工作计划。不同的时间序列有不同的特征,例如一个人在一年中每天消耗的粮食基本上是相同的,把这365个数字排列起来。发现它所构成的时间序列总保持在一定水平,上下相差不太大,我们称它是"平稳"时间序列。它的取值和具体是哪个时期无关,只和时期的长短有关。一般来说.只有属于平稳过程的时间序列.才是可以被预测的。







{kind=link}
非常不错