模擬退火演算法
出自 MBA智库百科(https://wiki.mbalib.com/)
模擬退火演算法(Simulate Anneal Arithmetic,SAA)
目錄 |
模擬退火演算法(Simulate Anneal Arithmetic,SAA)是一種通用概率演演算法,用來在一個大的搜尋空間內找尋命題的最優解。模擬退火是S.Kirkpatrick, C.D.Gelatt和M.P.Vecchi在1983年所發明。而V.Černý在1985年也獨立發明此演演算法。模擬退火演算法是解決TSP問題的有效方法之一。
模擬退火來自冶金學的專有名詞退火。退火是將材料加熱後再經特定速率冷卻,目的是增大晶粒的體積,並且減少晶格中的缺陷。材料中的原子原來會停留在使內能有局部最小值的位置,加熱使能量變大,原子會離開原來位置,而隨機在其他位置中移動。退火冷卻時速度較慢,使得原子有較多可能可以找到內能比原先更低的位置。
模擬退火的原理也和金屬退火的原理近似:將熱力學的理論套用到統計學上,將搜尋空間內每一點想像成空氣內的分子;分子的能量,就是它本身的動能;而搜尋空間內的每一點,也像空氣分子一樣帶有“能量”,以表示該點對命題的合適程度。演演算法先以搜尋空間內一個任意點作起始:每一步先選擇一個“鄰居”,然後再計算從現有位置到達“鄰居”的概率。
模擬退火演算法的模型[1]
模擬退火演算法可以分解為解空間、目標函數和初始解三部分。
- 模擬退火的基本思想:
- (1) 初始化:初始溫度T(充分大),初始解狀態S(是演算法迭代的起點), 每個T值的迭代次數L
- (2) 對k=1,……,L做第(3)至第6步:
- (3) 產生新解S′
- (4) 計算增量Δt′=C(S′)-C(S),其中C(S)為評價函數
- (5) 若Δt′<0則接受S′作為新的當前解,否則以概率exp(-Δt′/T)接受S′作為新的當前解.
- (6) 如果滿足終止條件則輸出當前解作為最優解,結束程式。終止條件通常取為連續若幹個新解都沒有被接受時終止演算法。
- (7) T逐漸減少,且T->0,然後轉第2步。
演算法對應動態演示圖:

- 模擬退火演算法新解的產生和接受可分為如下四個步驟:
- 第一步是由一個產生函數從當前解產生一個位於解空間的新解;為便於後續的計算和接受,減少演算法耗時,通常選擇由當前新解經過簡單地變換即可產生新解的方法,如對構成新解的全部或部分元素進行置換、互換等,註意到產生新解的變換方法決定了當前新解的鄰域結構,因而對冷卻進度表的選取有一定的影響。
- 第二步是計算與新解所對應的目標函數差。因為目標函數差僅由變換部分產生,所以目標函數差的計算最好按增量計算。事實表明,對大多數應用而言,這是計算目標函數差的最快方法。
- 第三步是判斷新解是否被接受,判斷的依據是一個接受準則,最常用的接受準則是Metropolis準則: 若Δt′<0則接受S′作為新的當前解S,否則以概率exp(-Δt′/T)接受S′作為新的當前解S。
- 第四步是當新解被確定接受時,用新解代替當前解,這隻需將當前解中對應於產生新解時的變換部分予以實現,同時修正目標函數值即可。此時,當前解實現了一次迭代。可在此基礎上開始下一輪試驗。而當新解被判定為捨棄時,則在原當前解的基礎上繼續下一輪試驗。
模擬退火演算法與初始值無關,演算法求得的解與初始解狀態S(是演算法迭代的起點)無關;模擬退火演算法具有漸近收斂性,已在理論上被證明是一種以概率l 收斂於全局最優解的全局優化演算法;模擬退火演算法具有並行性。
模擬退火演算法的簡單應用[1]
作為模擬退火演算法應用,討論貨郎擔問題(Travelling Salesman Problem,簡記為TSP):設有n個城市,用數位(1,…,n)代表。城市i和城市j之間的距離為d(i,j) i, j=1,…,n.TSP問題是要找遍訪每個域市恰好一次的一條迴路,且其路徑總長度為最短.。
求解TSP的模擬退火演算法模型可描述如下:
解空間:解空間S是遍訪每個城市恰好一次的所有迴路,是{1,……,n}的所有迴圈排列的集合,S中的成員記為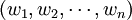 ,並記wn + 1 = w1。初始解可選為(1,……,n)
,並記wn + 1 = w1。初始解可選為(1,……,n)
目標函數:此時的目標函數即為訪問所有城市的路徑總長度或稱為代價函數: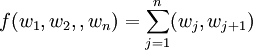
我們要求此代價函數的最小值。
新解的產生 隨機產生1和n之間的兩相異數k和m,若k<m,則將
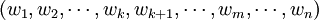
變為:
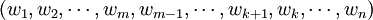
如果是k>m,則將
變為:
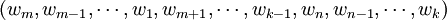
上述變換方法可簡單說成是“逆轉中間或者逆轉兩端”。
也可以採用其他的變換方法,有些變換有獨特的優越性,有時也將它們交替使用,得到一種更好方法。
代價函數差:設將變換為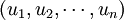 , 則代價函數差為:
, 則代價函數差為:
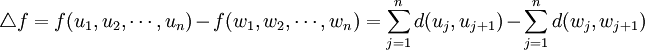
模擬退火演算法求解TSP問題的偽程式[1]
根據上述分析,可寫出用模擬退火演算法求解TSP問題的偽程式:
Procedure TSPSA:
begin
init-of-T; { T為初始溫度}
S={1,……,n}; {S為初始值}
termination=false;
while termination=false
begin
for i=1 to L do
begin
generate(S′form S); { 從當前迴路S產生新迴路S′}
Δt:=f(S′))-f(S);{f(S)為路徑總長}
IF(Δt<0) OR (EXP(-Δt/T)>Random-of-[0,1])
S=S′;
IF the-halt-condition-is-TRUE THEN
termination=true;
End;
T_lower;
End;
End
模擬退火演算法的應用很廣泛,可以較高的效率求解最大截問題(Max Cut Problem)、0-1背包問題(Zero One Knapsack Problem)、圖著色問題(Graph Colouring Problem)、調度問題(Scheduling Problem)等等。
模擬退火演算法的參數控制問題[1]
模擬退火演算法的應用很廣泛,可以求解NP完全問題,但其參數難以控制,其主要問題有以下三點:
(1) 溫度T的初始值設置問題。
溫度T的初始值設置是影響模擬退火演算法全局搜索性能的重要因素之一、初始溫度高,則搜索到全局最優解的可能性大,但因此要花費大量的計算時間;反之,則可節約計算時間,但全局搜索性能可能受到影響。實際應用過程中,初始溫度一般需要依據實驗結果進行若幹次調整。
(2) 退火速度問題。
模擬退火演算法的全局搜索性能也與退火速度密切相關。一般來說,同一溫度下的“充分”搜索(退火)是相當必要的,但這需要計算時間。實際應用中,要針對具體問題的性質和特征設置合理的退火平衡條件。
(3) 溫度管理問題。
溫度管理問題也是模擬退火演算法難以處理的問題之一。實際應用中,由於必須考慮計算複雜度的切實可行性等問題,常採用如下所示的降溫方式:
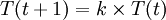
式中k為正的略小於1.00的常數,t為降溫的次數。
基於模擬退火演算法的證券投資最優組合理論研究[2]
證券投資是在證券市場上購買有價證券,以利息、股息或出售贏利等形式取得利潤收益的一項經濟活動。證券投資者最關心的是投資收益率的高低及投資風險的大小,投資者在選擇投資策略時,總希望收益率大而風險最小,但二者不可能同時滿足。初涉股市者往往懼怕風險,不求收益最大而求風險最小確定投資策略使投資風險最小,是投資者最關心的問題。現代證券組合理論是關於在收益不確定條件下投資行為的理論,它由Markowitz提出,且認為理性的投資者應具有“非滿足性”和“風險迴避性”兩個特征。基於Markowitz理論模型,許多學者在定量分析基礎上,結合實際操作內容,對其進行改進,得到很多有效的求解證券組合間題的方法,如一種確定最優組合投資權重的新方法、不允許賣空的組合證券投資決策方法以及不允許賣空的證券組合選擇模型等。在上述方法中,一般均假定Markowitz模型中的協方差矩陣是正定的,但該條件不具有一般性,因而在使用上受到限制本文提出將模擬退火演算法用於求解證券組合問題,探討如何在預期收益率一定的條件下,使得投資風險最小。
一、模擬退火演算法模擬
退火演算法是基於迭代求解策略的一種隨機尋優演算法,它從一較高初溫開始,利用具有概率突跳特性的Metrpols抽樣策略在解空間中進行隨機搜索,伴隨溫度的不斷下降重覆抽樣過程,直至得到問題的全局最優解標準模擬退火演算法的一般步驟描述如下:
(1)給定初溫t = t0,隨機產生初始狀態:s = s0,令k=0;
(2)Repeat;
Repeat;
產生新狀態sj = Generate(s);
if min{1,exp[-(C(sj)-C(s))/tk]}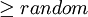 [0,1]s = sj;
[0,1]s = sj;
Until抽樣穩定准則滿足:
退溫tk + 1 = update(tk),並令k=k+1
(3)Until演算法終止準則滿足;
(4)輸出演算法結果。
從以上步驟可以看出,新狀態產生函數、新狀態接受函數、退溫函數、抽樣穩定准則和退火結束準則以及初始溫度是直接影響演算法優化結果的主要環節。由於模擬退火演算法採取隨機搜索策略所以能夠較快地搜索目標函數的全局最優解。
二、模型的建立
設一個金融機構可以選擇的風險證券為n種,每種證券的收益率為ri,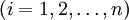 ,則可看作是隨機變數;R是證券i的預期收益率.設這。種風險證券的投資權重為
,則可看作是隨機變數;R是證券i的預期收益率.設這。種風險證券的投資權重為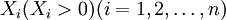 ,則
,則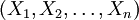 是概率向量;其證券組合的預期收益率為:
是概率向量;其證券組合的預期收益率為: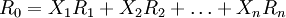 ;用δij表示第i種證券預期收益和第i種證券預期收益的協方差,E是該證券組合的協方差矩陣。
;用δij表示第i種證券預期收益和第i種證券預期收益的協方差,E是該證券組合的協方差矩陣。
為使投資風險最小,間題歸結為求解如下問題:
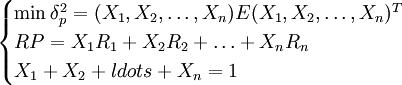
其中第一個關係式反映投資風險極小化是預期收益率一定的條件下的投資目標:第二個關係式是預期收益率滿足一個理想且合理的條件;第三個關係式是概率向量固有性質;RP是供投資決策者選擇證券組合的預期收益率。
在投資中,投資比重可能含有負分量,即對應的證券進行賣空操作,賣空是賣出該證券,將出售的收人投資於其它種類的證券.但是有時不允許賣空,因此本文假設投資比重大於零。
借鑒標準的模擬退火演算法,結合上述模型,具體分析過程如下:。
步驟1:確定初始投資概率向量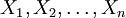 ,滿足X1 + X2 + ldots + Xn = 1。計算目標函數值
,滿足X1 + X2 + ldots + Xn = 1。計算目標函數值![J(X_1,X_2,\ldots,X_n)=(X_1,X_2,\ldots,X_n)E(X_1,X_2,\ldots,X_n)^T+\left[RP-(X_1R_1,X_2R_2,X_nR_n)\right]^2](/w/images/math/b/1/a/b1ae6102dea74e1a89046fd00949fdd7.png) 。
。
確定最大的迴圈迭代次數L,在實際計算中,可將L定為一固定數礦,其中n^2為變數個數,置k=1;
步賺2;隨機迭取變數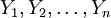 可在[0,1]內選取),進行歸一化處理,使之成為概率量。令
可在[0,1]內選取),進行歸一化處理,使之成為概率量。令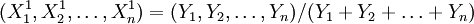 ,計算新目標函數值
,計算新目標函數值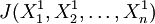 ;
;
步驟3:比較兩個目標函數值如果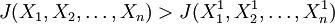 ,則用新向量代替原向量
,則用新向量代替原向量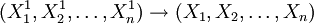 ;
;
步驟4:若不滿足停止判據且尚未達到最大迭代次數,則置k=k十1,轉步驟2;否則停止計算,輸出最終結果。停止判據可以設為:
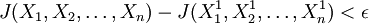 。
。
其中ε為預先設定的小的正數。
實證分析。
下麵結合上述具體過程,利用實例說明在收益率RP固定情況下,求風險最小的投資組成的可行性。若一個證券組合由三個證券組成,根據歷史資料,由前述協方差矩陣計算公式,得出其協方差矩陣的估計值如下:。

其中收益率RP以及三個證券的預期收益率由程式輸人,運行結果如表1所示。
程式運行結果
| 輸人 | R1 = 0.24;R2 = 0.15;R3 = O.33 | ||||
| RP=0.75 | RP=0.95 | ||||
| 輸出結果 | I | II | III | IV | |
| X1 | 0.356600 | 0.166200 | 0.460700 | 0.711900 | |
| X2 | 0.397493 | 0.291663 | 0.420600 | 0.059233 | |
| X3 | 0.245907 | 0.542137 | 0.118700 | 0.228867 | |
| csfx | 0.295987 | 0.248332 | 0.571878 | 0.507709 | |
| jsfx | 0.235932 | 0.336376 | 0.448742 | 0.582512 | |
| X[1] | 0.132252 | 0.166200 | 0.332737 | 0.711900 | |
| X[2] | 0.248348 | 0.291663 | 0.073387 | 0.059233 | |
| X[3] | 0.619401 | 0.542137 | 0.593876 | 0.228867 | |
通過結合分析可得到如下結論:
(1)隨著組合證券預期收益率RP的增大,組合證券投資的風險嚴格增大。
(2)計算的投資比例向量可直接作為投資比例繫數,雖然計算結果不一定最優,但至少可保證結果令人滿意。
(3)由表1數據可以看出,由於隨機產生初始投資向量與新產生的投資向量,因此在輸人量相同情況下,可導致最終輸出結果不一致,因此可適當增加其迭代次數或將進一步縮小程式停止判據條件範圍,反覆調試,即可得到滿意的組合證券投資比例向最。
(4)若最終計算的風險值jsfx大於初始風險值csfx時,則輸出初始投資向量;否則用新產生的投資向量代替初始投資向量,這符合投資者心理行為。投資者希望提高投資的收益率,但增加的風險會遠遠超過投資者的實際(或者心理)承受能力,因此投資者應權衡收益與風險的利弊,做出慎重選擇。
基於模擬退火演算法的證券組合優化解決方法,它不要求馬氏模型中的協方差矩陣具有任何特性,計算得到的投資概率向量可直接作為投資比例繫數,為證券投資者提供了理論依據。







{kind=link}
寫的太好了