KMRW聲譽模型
出自 MBA智库百科(https://wiki.mbalib.com/)
KMRW聲譽模型(KMRW Reputation Model)
目錄 |
KMRW聲譽模型有時也稱KMRW模型“四人幫模型”,是由戴維·M·克雷普斯(David M.Kreps)、保羅·米格羅姆(Paul Milgrom)、約翰·羅伯茨(John Roberts)和羅伯特·威爾遜 (Robert Wilson)所建立的。
KMRW聲譽模型證明,參與人對其他參與人支付函數或戰略空間的不完全信息對均衡結果有重要影響,合作行為在有限次重覆博弈中會出現,只要博弈重覆次數足夠長。
KMRW聲譽模型對有限重覆博弈中信譽效應(既合作現象)做出了很好的解釋。
在完全信息情況下,不論博弈重覆多少次,只要重覆的次數是有限的,唯一的子博弈精煉納什均衡是每個參與人在每次博弈中選擇靜態均衡戰略(假定靜態博弈的納什均衡是唯一的),即有限次重覆不可能導致參與人的合作行為。特別地,在有限次重覆囚徒博弈中,每次都選擇“坦白”是每個囚徒的最優戰略。 這一結果似乎與人們的直觀感覺不一致。阿克賽爾羅德(Axelrod,1981和1984年)的錦標賽實驗結果表明,在200次有限次重覆囚徒博弈中,合作行為頻繁出現,而“針鋒相對”戰略是最穩健的戰略。
“理什囚徒”只是對我們已經熟悉的“囚徒”及其行為的一個簡單化概括,這裡可以理解為機會主義者,或者非合作型參與人; “非理性囚徒”是對具有不同於我們熟悉的行為方式的另一類囚徒的概括,這裡可以理解為講義氣重信譽的人,或者合作型參與人
他們證明,參與人對其他參與人支付函數或戰略空間的不完全信息對均衡結果有重要影響,只要博弈重覆的次數足夠多,合作行為在有限次重覆博弈中就會出現。在其模型中,囚徒博弈中的每個參與人並不知道對方的類型,即是“理性的”,還是“非理性的”,非理性的交易方只選擇觸發策略。每個參與人對自己類型的瞭解屬於私有信息,只知道對方屬於非理性的概率為P。在此條件下,在T階段重覆囚徒博弈中,如果每個囚徒都有P>0的概率是非理性的(即只選擇“針鋒相對”或“冷酷戰略”),如果T足夠大,n那麼存在一個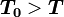 ,使得下列戰略組合構成一個精煉貝葉斯均衡:
所有理性囚徒在
,使得下列戰略組合構成一個精煉貝葉斯均衡:
所有理性囚徒在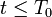 階段選擇合作(抵賴),在
階段選擇合作(抵賴),在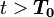 階段選擇不合作(坦白);並且,非合作階段的數量
階段選擇不合作(坦白);並且,非合作階段的數量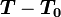 只與p有關,而與T無關。
只與p有關,而與T無關。
Kreps等人的思想後來被總結為KMRW定理。KWRM定理的一個直觀解釋是(張維迎,1996),每一個參與人儘管在選擇合作時可能面臨被對手出賣的風險(從而可能得到一個較低的現階段支付),若對方是合作類型的話,如果他選擇不合作,就暴露了自己是非合作型的,從而失去了獲得長期合作收益的可能。只要博弈重覆的次數足夠多,未來收益的損失就超過短期被出賣的損失。因此,即使他們在本性上並不是合作型的,在博弈開始時每一個參與人都想樹立一個合作形象(使對方認為自己是喜歡合作的),而只有在博弈快結束時,參與人一次性地把自己過去建立的聲譽用盡,合作才會停止(因為此時,短期收益很大而未來損失很小)。該模型的出色解釋力在於,大量的事實表明,將參與人外生的具有合作傾向假定並非合理,大多數的合作發生於對自身利益的考慮。在一些長期的交易關係中,交易各方都會致力於建立形象和維護聲譽,雖然這些聲譽在短期來看並非是經濟的,但長期的合作收入流的補償卻表明這種聲譽的建立是最優的選擇。
Klein(1997)更加明確地指出,現代社會複製聲譽的主要手段是現代組織,包括企業組織、社團組織(如宗教團體,商會),以及大量的中介組織。Tadelis(1999)認為聲譽是企業一項重要的無形資產,它附屬於企業的名稱並由其展現 。在他的模型中,企業唯一的資產是與企業聲譽相聯繫的企業名稱,對企業名稱的交易就等於企業聲譽的交易。
在T階段重覆囚徒博弈中,如果每個囚徒都有P>0的概率是非理性的(即只選擇“針鋒相對”或“冷酷戰略”),如果T足夠大,n那麼存在一個 ,使得下列戰略組合構成一個精煉貝葉斯均衡:
所有理性囚徒在 階段選擇合作(抵賴),在階段選擇不合作(坦白);並且,非合作階段的數量 只與p有關,而與T無關。
KMRW 模型中有以下幾點需要強調:
(1)KMRW分析主要適應於多階段重覆博弈。並且信息是不對稱的,參與人是非完全理性的;
(2)KMRW模型的出發點。只要階段博弈重覆次數足夠多。參與人有足夠的耐心。即使P非常小,這種小小的不確定性也對參與人有著較大的影響;
(3)Kreps等人對序貫均衡證明瞭在T階段重覆博弈中,如果存在P>0的概率。參與人是非理性的(即只採取針鋒相對策略或冷酷策略),如果T夠大.任何一個參與人選擇背叛的階段數是存在著一個上限的。這個上限依賴於P及階段博弈的盈利而與T無關,即參與人在相當多的階段存在著合作;
(4)如果對階段博弈的盈利即P強加上若幹條件,參與人對針鋒相對策略的最優反應將是合作下去直到博弈的最後一個階段。
儘管每一個囚徒在選擇合作時冒著被其他囚徒出賣的風險(從而可能得到一個較低的現階段支付),但如果他選擇不合作,就暴露了自己是非合作型的,從而失去了獲得長期合作收益的可能,如果對方是合作型的話;
如果博弈重覆的次數足夠多,未來收益的損失就超過了短期被出賣的損失,因此,在博弈的開始,每一個參與人都想樹立一個合作形象(使對方認為自己是喜歡合作的),即使他在本性上並不是合作型的;
只有在博弈快結束的時候,參與人才會一次性地把自己的過去建立的聲譽利用盡,合作才會停止,因為此時,短其收益很大而未來損失很小;
KMRW定理解釋了“大智若愚”,這裡,智者囚徒博弈中的理性囚徒(非合作型),“愚者”即囚徒博弈中的非理性囚徒(合作型)。 在許多情況下,大智若愚確實是“智者”追求自己利益的最佳方式。
只要博弈重覆的次數足夠長,參與人有足夠的耐心(只要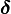 足夠接近於1),即使(有關參與人類型的)小小的不確定性,也可能引起均衡結果的重大改變(很小的p就可以保證合作均衡的出現,但如果p=0,合作均衡不可能出現)。 當然,合作均衡的可能性依賴於我們有關非理性參與人行為的假定。比如,如果我們假定,不論對方選擇什麼,非理性囚徒總是選擇D(合作),那麼,合作均衡就不會出現,因為,給定非理性囚徒總是選擇D的情況下,C是理性囚徒的占優戰略。如果不論你如何損害對方的利益,對方總是“以德報怨”、"仇將恩報"。
足夠接近於1),即使(有關參與人類型的)小小的不確定性,也可能引起均衡結果的重大改變(很小的p就可以保證合作均衡的出現,但如果p=0,合作均衡不可能出現)。 當然,合作均衡的可能性依賴於我們有關非理性參與人行為的假定。比如,如果我們假定,不論對方選擇什麼,非理性囚徒總是選擇D(合作),那麼,合作均衡就不會出現,因為,給定非理性囚徒總是選擇D的情況下,C是理性囚徒的占優戰略。如果不論你如何損害對方的利益,對方總是“以德報怨”、"仇將恩報"。
KWRW模型解開了有限重覆博弈的悖論,但也帶來了均衡的多重性問題。 弗登伯格和馬司肯(1986年)證明,類似完全信息無限重覆博弈的“無名氏定理”在不完全信息有限重覆博弈中也成立,只要博弈重覆的次數足夠長,參與人有足夠的耐心,任何滿足個人理性的可行支付向量,都可以作為精煉貝葉斯均衡結果出現,不論p多麼小。







{kind=link}
沒看懂,能不能說的明確一點啊