相對熵
出自 MBA智库百科(https://wiki.mbalib.com/)
相對熵(Relative Entropy; KL散度; Kullback–Leibler divergence; KLD; 信息散度; 信息增益)
目錄 |
相對熵是指兩個概率分佈P和Q差別的非對稱性的度量。 相對熵是用來 度量使用基於Q的編碼來編碼來自P的樣本平均所需的額外的比特個數。典型情況下,P表示數據的真實分佈,Q表示數據的理論分佈,模型分佈,或P的近似分佈。
對於離散隨機變數,其概率分佈P 和 Q的相對熵可按下式定義為
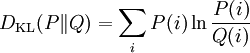 。即按概率P求得的P和Q的對數差的平均值。相對熵僅當概率P和Q各自總和均為1,且對於任何i皆滿足Q(i) > 0及P(i) > 0時,才有定義。式中出現0ln0的情況,其值按0處理。
。即按概率P求得的P和Q的對數差的平均值。相對熵僅當概率P和Q各自總和均為1,且對於任何i皆滿足Q(i) > 0及P(i) > 0時,才有定義。式中出現0ln0的情況,其值按0處理。
對於連續隨機變數,其概率分佈P和Q可按積分方式定義為 [1]
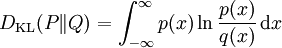 ,其中p和q分別表示分佈P和Q的密度。
更一般的,若P和Q為集合X的概率測度,且Q關於P絕對連續|絕對連續,則從P到Q的相對熵定義為
,其中p和q分別表示分佈P和Q的密度。
更一般的,若P和Q為集合X的概率測度,且Q關於P絕對連續|絕對連續,則從P到Q的相對熵定義為
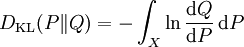 ,
其中,假定右側的表達形式存在,則
,
其中,假定右側的表達形式存在,則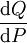 為Q關於P的拉東-尼科迪姆定理|R–N導數。
為Q關於P的拉東-尼科迪姆定理|R–N導數。
相應的,若P關於Q絕對連續|絕對連續,則
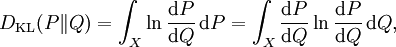
即為P關於Q的相對熵。
相對熵的值為非負數:
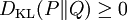 ,
,
由吉布斯不等式可知,當且僅當P = Q時DKL(P||Q)為零。
儘管從直覺上相對熵是個度量|度量或距離函數, 但是它實際上並不是一個真正的度量或距離。因為相對熵不具有對稱性:從分佈P到Q的距離(或度量)通常並不等於從Q到P的距離(或度量)。
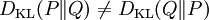
自信息和相對熵
I(m) = DKL(δim | pi),
互信息和相對熵
- I(X;Y) = DKL(P(X,Y) | | P(X)P(Y)) = EXDKL(P(Y | X) | | P(Y)) = EYDKL(P(X | Y) | | P(X))
信息熵和相對熵
- H(X) = ExI(x) = logN − DKL(P(X) | | PU(X))
條件熵和相對熵
- H(X | Y) = logN − DKL(P(X,Y) | | PU(X)P(Y)) = (i)logN − DKL(P(X,Y) | | P(X)(Y)) − DKL(P(X) | | PU(X)) = H(X) − I(X;Y) = iilogN − EYDKLP(X | Y) | | PU(X)
交叉熵和相對熵
H(p,q) = Ep[ − logq] = H(p) + DKL(p | q)。
- ↑ C. Bishop (2006). Pattern Recognition and Machine Learning. p. 55.






