潜语义标引模型
用手机看条目
出自 MBA智库百科(https://wiki.mbalib.com/)
- 潜语义标引模型(Latent Semantic Analysis,LSA)
目录 |
[编辑]
什么是潜语义标引模型[1]
潜语义标引模型是由S.Derewester和S.T.Dumais提出,其将标引词之间、文献之间的相关关系以及标引词与文献之间的语义关联都考虑在内,将文献向量和提问向量映射到与语义概念相关联的较低维度的空间中,从而把文献的标引词向量空间转化为语义概念空间;然后再在降维了的语义概念空间中,计算文献向量和提问向量的相似度,然后根据所得的相似度把排列结果返回给用户。
[编辑]
潜语义标引模型的主要思想[2]
潜语义标引模型的主要思想是将文档和查询向量映射到与概念相关联的空间,这可以通过把索引项向量映射到维数较低的空间来实现。这种观点认为,在维数降低了的空间中的检索可能优于在索引项集合中的检索。潜在语义分析同向量空间模型类似,都是采用空间向量表示文本,但通过奇异值分解(Singular Value Decomposition,SVD)等处理,消除了同义词、多义词的影响,提高了后续处理的精度。因而在信息检索、信息过滤、相关反馈、信息聚类/分类、跨语言信息检索、信息理解和判断及预测等方面都有广泛的应用。
假设有一个文本集,包含n个文档,用到了t个词汇,构造“词项-文档矩阵”(Term-Document-MatriX,TDM):
| d1 | d2 |  | dn | |
| k1 ![M_{t \times n}=[M_{i,j}]=k_2](/w/images/math/d/6/d/d6d6e93e7704d59edd77715879bf1105.png)  kt | 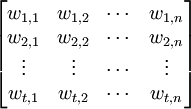
| |||
对矩阵的每一个元素mi,j,可以为其分配一个权值叫wi,j,表示词项ki在文档dj中的权重。由于任意一个文档总是由有限个词汇,而不是由所有t个词汇构成的,所以M必是一个稀疏矩阵。
潜语义标引模型的关键思想是将文档和词汇映射到一个低维的向量空间,即潜在语义空间。潜语义标引模型利用奇异分解SVD的方法实现这种降维。
[编辑]
[编辑]







{kind=link}