向量空间模型
出自 MBA智库百科(https://wiki.mbalib.com/)
- 向量空间模型(Vector Space Model,VSM)
目录 |
什么是向量空间模型[1]
向量空间模型是由Salton等人于20世纪60年代末提出,是一种简便、高效的文本表示模型,其理论基础是代数学。向量空间模型把用户的查询要求和数据库文档信息表示成由检索项构成的向量空间中的点,通过计算向量之间的距离来判定文档和查询之间的相似程度。然后,根据相似程度排列查询结果。向量空间模型的关键在于特征向量的选取和特征向量的权值计算两个部分。
向量空间模型的基本原理[2]
- 1.文档向量的构造
对于任一文档 ,我们可以把它表示为如下t维向量的形式:
,我们可以把它表示为如下t维向量的形式:
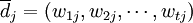
其中,向量分量wtj代表第i个标引词ki在文档dj中所具有的权重,t为系统中标引词的总数。在布尔模型中,wtj的取值范围是{0,1};在向量空间模型中,由于采用“部分匹配”策略,wtj的取值范围是一个连续的实数区间[0,1]。
在检索的前处理中,一篇文档中会标引出多个不同的标引词,而这些标引词对表达该篇文档主题的能力往往是不同的。也就是说,每个标引词应该具有不同的权值。如何计算文档向量中每个标引词的权值,不仅关系到文档向量的形成,也关系到后续的检索匹配结果。
标引词权重的大小主要依赖其在不同环境中的出现频率统计信息,相应的权重就分成局部权重和全局权重。
局部权重(Local Weight)ltj是按第i个标引词在第j篇文档中的出现频率计算的权重。它以提高查全率为目的,对在文档中频繁出现的标引项给予较大的权重。
全局权重(Global Weight)gt则是按第i个标引词在整个系统文档集合中的分布确定的权重。它以提高查准率为目的,对在许多文档中都出现的标引项给予较低的权重,而对仅在特定文档中出现频次较高的标引项给予较大的权重。计算全局权重的典型方法就是逆文档频率IDF(Inverse Document Frequency)加权法。
gi = log(N / ni)
其中,N为系统文档总数,ni为系统中含有标引词ki的文档数。
- 2.提问向量的构造
在向量空间模型中,用户的信息需求被转换为提问向量,并用与文档向量类似的表示形式表示,即
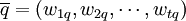
这里,t为系统中标引词的总数,向量分量wtq表示第i个标引词ki在提问q中的权值,且有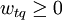 。对于查询语词的权值,Sahon和Buckley认为可以采用如下的方法:
。对于查询语词的权值,Sahon和Buckley认为可以采用如下的方法:

式中,freqiq为标引词ki在表述用户信息需求的文本内容中所出现的次数,而maxtfq则是在表述用户信息需求的文本内容中所使用的所有标引词出现次数的最大值。
- 3.文档与提问向量相似度的计算
在文档与提问向量化表示的基础之上,文档与查询提问之间的相关程度(即相似度)就可以由它们各自向量在t维空间的相对位置来决定。
向量间相似程度的度量方法有很多种,主要有内积法(Inner Product)、Dice法(Dice Coefficient)、Jaccard法(Jaccard Coefficient)和余弦法(Cosine Coefficient)。
较常用的度量方法是提问向量和文档向量间的内积法,其计算公式如下:

其中,QTi是检索提问中检索项i的权值,DTi是文档中标引项i的权值,N为总的项数。
当每个向量都通过余弦法进行加权后,则内积法转换为余弦法。余弦法采用的相似度计算指标是两个向量夹角的余弦函数。
向量空间模型的分析[2]
向量空间模型最早起源于文本信息检索实践,对揭示信息检索的基本原理做出过重要贡献。在VSM中,研究人员成功地将非结构化的文本信息表示成向量形式,为随后的各种文本信息处理操作奠定了数学计算的基础。向量空间模型在检索处理中所具有的先进技术特征主要表现在以下几个方面。
(1)对标引词的权重进行了改进,其权重的计算可以通过对标引项出现频率的统计方法自动完成,使问题的复杂性大为降低,从而改善了检索效果。
(2)将文档和查询简化为标引词及其权重集合的向量表示,把对文档内容和查询要求的处理简化为向量空间中向量的运算。
(3)采用部分匹配策略,使得在算法层面上基于多值相关性的判断处理得以实现。
(4)根据文档和查询之间的相似度对检索结果进行排序,使对检索结果数量的控制与调整具有相当的弹性与自由度,有效地提高了检索效率。
当然,向量空间模型理论也存在着明显的缺陷,具体包括以下几个方面。
(1)从文档中抽取出的各标引词之间的关系做了相互独立的基本假定,这会失掉大量的文本结构信息,如文档句子中词序的信息,因此降低了语义的准确性。
(2)相似度的计算鼍较大,当有新文档加入时,必须重新计算标引词的权重。
(3)在标引项权重的计算中,对不同语言单位构成的项都只考虑其统计信息,而仅以该信息来反映标引项的重要性,显然缺乏全面性







{kind=link}