潛語義標引模型
用手机看条目
出自 MBA智库百科(https://wiki.mbalib.com/)
- 潛語義標引模型(Latent Semantic Analysis,LSA)
目錄 |
[編輯]
什麼是潛語義標引模型[1]
潛語義標引模型是由S.Derewester和S.T.Dumais提出,其將標引詞之間、文獻之間的相關關係以及標引詞與文獻之間的語義關聯都考慮在內,將文獻向量和提問向量映射到與語義概念相關聯的較低維度的空間中,從而把文獻的標引詞向量空間轉化為語義概念空間;然後再在降維了的語義概念空間中,計算文獻向量和提問向量的相似度,然後根據所得的相似度把排列結果返回給用戶。
[編輯]
潛語義標引模型的主要思想[2]
潛語義標引模型的主要思想是將文檔和查詢向量映射到與概念相關聯的空間,這可以通過把索引項向量映射到維數較低的空間來實現。這種觀點認為,在維數降低了的空間中的檢索可能優於在索引項集合中的檢索。潛在語義分析同向量空間模型類似,都是採用空間向量表示文本,但通過奇異值分解(Singular Value Decomposition,SVD)等處理,消除了同義詞、多義詞的影響,提高了後續處理的精度。因而在信息檢索、信息過濾、相關反饋、信息聚類/分類、跨語言信息檢索、信息理解和判斷及預測等方面都有廣泛的應用。
假設有一個文本集,包含n個文檔,用到了t個辭彙,構造“詞項-文檔矩陣”(Term-Document-MatriX,TDM):
| d1 | d2 |  | dn | |
| k1 ![M_{t \times n}=[M_{i,j}]=k_2](/w/images/math/d/6/d/d6d6e93e7704d59edd77715879bf1105.png)  kt | 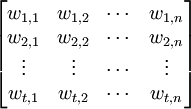
| |||
對矩陣的每一個元素mi,j,可以為其分配一個權值叫wi,j,表示詞項ki在文檔dj中的權重。由於任意一個文檔總是由有限個辭彙,而不是由所有t個辭彙構成的,所以M必是一個稀疏矩陣。
潛語義標引模型的關鍵思想是將文檔和辭彙映射到一個低維的向量空間,即潛在語義空間。潛語義標引模型利用奇異分解SVD的方法實現這種降維。
[編輯]
[編輯]







{kind=link}