概率论模型
出自 MBA智库百科(https://wiki.mbalib.com/)
- 概率论模型(Probabilistic Model)
目录 |
什么是概率论模型[1]
概率论模型是基于概率排序原理,在概率框架中处理信息检索问题。模型中假设特征项之间是相互独立的,该模型是基于概率原则:给定一个用户查询q和文档集中的一个文档dj,概率模型试图估计用户找到其感兴趣的文档dj的概率,概率模型假设这个相关概率只是依赖于查询和文档表示。进而假设模型在文档集中存在一个子集,它是查询q的结果集。理想结果集记为R,它使得总体的相关概率最大。集合R中的文档被认为是与查询相关的,不在集合R中的文档则被认为是不相关的。
概率论模型基本上是一种基于贝叶斯决策理论的自适应模型。与前两种模型不同的是,它的查询式子不是直接由用户编定的。而是由系统通过某种归纳式学习过程(相关反馈)来构造一个决策函数去表示信息查询。
概率论模型的基础[2]
概率论模型的基础是概率,预估计信息资源与用户需求的相关性,根据相关性大小进行排序,排到最前面的文档将会是最有可能满足用户需求的文档。Van Rijsbergen和Robertson等人提出的概率检索模型的基本思想是根据先前检索过程中得到的相关性先验信息来计算文档集合中每篇文档成为相关文档的概率,并根据统计理论(如贝叶斯决策等)来确定哪些文档可作为输出文档集。相关工作中,将布尔检索和概率检索模型有机地结合起来,但它在没有获得样本文档之前,无法估计词条相关性且该方法复杂度较大。
概率论模型的基本准则[3]
概率论模型的基本准则是:文本按照与查询的概率相关性大小排序,排在前面的文本是最有可能被获取的文本,即如果文本满足如下公式则该文本被获取:
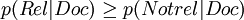
其中,p(Rel | Doc)表示文本Doc与查询有关的条件概率;p(Notrel | Doc)表示文本Doc与查询不相关的条件概率。根据贝叶斯规则,上述公式可以改写成
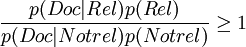
所获取的文本可以利用上述公式的左端进行排序。
利用概率论模型的关键是如何计算左端式子中的概率。如果查询由一个词组成,或者组成查询的词之间相互独立,那么查询词的权重可以由下式计算:
![w=\frac{r/(R-r)}{(n-r)/[N-n-(R-r)]}](/w/images/math/3/6/9/3699b421eacbfce64b9e490436e4c819.png)
式中,N是文本库中文本的数量;n是文本库中包含该词的文本数量;R是与查询相关的文本数目(相关的文本数目在训练文本库中是已知的);r是与查询相关而且包含该词的文本数目。
这样查询q可以表示为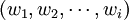 ,其中,叫wi由上述公式计算得到。文本d表示为
,其中,叫wi由上述公式计算得到。文本d表示为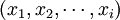 ,其中,如果词存在于文本中,则对应的xi = 1,反之则xi = 0。查询q与文本d之间的相似度函数定义为
,其中,如果词存在于文本中,则对应的xi = 1,反之则xi = 0。查询q与文本d之间的相似度函数定义为
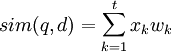
利用概率论模型的典型系统有Kwok与Robertson等,它们在利用样本计算词权重的过程中考虑了词在文档中出现的频率,其中Kwok系统还考虑了词在整个样本集合中出现的频率。概率论模型的效果要明显优于布尔模型,但比向量空间模型略差。
概率论模型的一个特例是贝叶斯网络,由于该模型适合于超文本系统,因此在超文本信息成为当前信息获取主流信息的情况下,该模型的应用越来越广泛。







{kind=link}