判别分析
出自 MBA智库百科(https://wiki.mbalib.com/)
判别分析(discriminant analysis)
目录 |
判别分析又称为线性判别分析(Linear Discriminant Analysis)产生于20世纪30年代,是利用已知类别的样本建立判别模型,为未知类别的样本判别的一种统计方法。近年来,判别分析在自然科学、社会学及经济管理学科中都有广泛的应用。判别分析的特点是根据已掌握的、历史上每个类别的若干样本的数据信息,总结出客观事物分类的规律性,建立判别公式和判别准则。当遇到新的样本点时,只要根据总结出来的判别公式和判别准则,就能判别该样本点所属的类别。判别分析按照判别的组数来区分,可以分为两组判别分析和多组判别分析。
判别分析(Discriminatory Analysis)的任务是根据已掌握的1批分类明确的样品,建立较好的判别函数,使产生错判的事例最少,进而对给定的1个新样品,判断它来自哪个总体。
根据资料的性质,分为定性资料的判别分析和定量资料的判别分析;采用不同的判别准则,又有费歇、贝叶斯、距离等判别方法。
费歇(FISHER)判别思想是投影,使多维问题简化为一维问题来处理。选择一个适当的投影轴,使所有的样品点都投影到这个轴上得到一个投影值。对这个投影轴的方向的要求是:使每一类内的投影值所形成的类内离差尽可能小,而不同类间的投影值所形成的类间离差尽可能大。
贝叶斯(BAYES)判别思想是根据先验概率求出后验概率,并依据后验概率分布作出统计推断。所谓先验概率,就是用概率来描述人们事先对所研究的对象的认识的程度;所谓后验概率,就是根据具体资料、先验概率、特定的判别规则所计算出来的概率。它是对先验概率修正后的结果。
距离判别思想是根据各样品与各母体之间的距离远近作出判别。即根据资料建立关于各母体的距离判别函数式,将各样品数据逐一代入计算,得出各样品与各母体之间的距离值,判样品属于距离值最小的那个母体。
判别分析的方法有参数方法和非参数方法。参数方法假定每个类的观测来自(多元)正态分布总体,各类的分布的均值(中心)可以不同。非参数方法不要求知道各类所来自总体的分布,它对每一类使用非参数方法估计该类的分布密度,然后据此建立判别规则。
记X为用来建立判别规则的P维随机变量,S为合并协方差阵估计,t=1,...,G为组的下标,共有G个组。记nt为第t组中训练样本的个数,m_t为第t组的自变量均值向量,St为第t组的协方差阵, | St | 为St的行列式,qt为第t组出现的先验概率,p(t|x)为自变量为x的观测属于第t组的后验概率,ft(x)为第t组的分布密度在X=x处的值,f(x)为非条件密度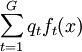 。
。
按照Bayes理论,自变量为x的观测属于第t组的后验概率p(t | x) = qtft(x) / f(x)。于是,可以把自变量X的取值空间R^P划分为G个区域Rt,t=1,...,G,使得当X的取值x属于R_t时后验概率在第t组最大,即

建立的判别规则为:计算自变量x到每一个组中心的广义平方距离,并把x判入最近的类。广义平方距离的计算可能使用合并的协方差阵估计或者单独的协方差阵估计,并与先验概率有关,定义为
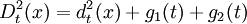
其中
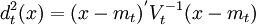

Vt = St (使用单个类的协方差阵估计)或 Vt = S(使用合并的协方差阵估计)。mt可以用第t组的均值\overline{X_t}代替。在使用合并协方差阵时,

其中x'S − 1x是共同的可以不考虑,于是在比较x到各组中心的广义平方距离时,只要计算线性判别函数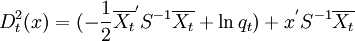 ,当x到第t组的线性判别函数最大时把x对应观测判入第t组。在如果使用单个类的协方差阵估计Vt = St则距离函数是x的二次函数,称为二次判别函数。
,当x到第t组的线性判别函数最大时把x对应观测判入第t组。在如果使用单个类的协方差阵估计Vt = St则距离函数是x的二次函数,称为二次判别函数。
后验概率可以用广义距离表示为
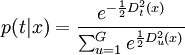
因此,参数方法的判别规则为:先决定是使用合并协方差阵还是单个类的协方差阵,计算x到各组的广义距离,把x判入最近的组;或者计算x属于各组的后验概率,把x判入后验概率最大的组。如果x的最大的后验概率都很小(小于一个给定的界限),则把它判入其它组。
非参数判别方法仍使用Bayes后验概率密度的大小来进行判别,但这时第t组在x处的密度值ft(x)不再具有参数形式,不象参数方法那样可以用mt和St(或St)表示出来。非参数方法用核方法或最近邻方法来估计概率密度ft(x)。
最近邻估计和核估计也都需要定义空间中的距离。除了可以用欧氏距离外,还可以用马氏(Mahalanobis)距离,定义为:
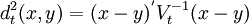
其中Vt为以下形式之一:
Vt = S合并协方差阵
Vt = diag(S)合并协方差阵的对角阵
Vt = St第t组内的协方差阵
Vt = diag(St)第t组内的协方差阵的对角阵
Vt = I单位阵,这时距离即普通欧氏距离







{kind=link}