向量空間模型
出自 MBA智库百科(https://wiki.mbalib.com/)
- 向量空間模型(Vector Space Model,VSM)
目錄 |
什麼是向量空間模型[1]
向量空間模型是由Salton等人於20世紀60年代末提出,是一種簡便、高效的文本表示模型,其理論基礎是代數學。向量空間模型把用戶的查詢要求和資料庫文檔信息表示成由檢索項構成的向量空間中的點,通過計算向量之間的距離來判定文檔和查詢之間的相似程度。然後,根據相似程度排列查詢結果。向量空間模型的關鍵在於特征向量的選取和特征向量的權值計算兩個部分。
向量空間模型的基本原理[2]
- 1.文檔向量的構造
對於任一文檔 ,我們可以把它表示為如下t維向量的形式:
,我們可以把它表示為如下t維向量的形式:
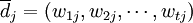
其中,向量分量wtj代表第i個標引詞ki在文檔dj中所具有的權重,t為系統中標引詞的總數。在布爾模型中,wtj的取值範圍是{0,1};在向量空間模型中,由於採用“部分匹配”策略,wtj的取值範圍是一個連續的實數區間[0,1]。
在檢索的前處理中,一篇文檔中會標引出多個不同的標引詞,而這些標引詞對錶達該篇文檔主題的能力往往是不同的。也就是說,每個標引詞應該具有不同的權值。如何計算文檔向量中每個標引詞的權值,不僅關係到文檔向量的形成,也關係到後續的檢索匹配結果。
標引詞權重的大小主要依賴其在不同環境中的出現頻率統計信息,相應的權重就分成局部權重和全局權重。
局部權重(Local Weight)ltj是按第i個標引詞在第j篇文檔中的出現頻率計算的權重。它以提高查全率為目的,對在文檔中頻繁出現的標引項給予較大的權重。
全局權重(Global Weight)gt則是按第i個標引詞在整個系統文檔集合中的分佈確定的權重。它以提高查準率為目的,對在許多文檔中都出現的標引項給予較低的權重,而對僅在特定文檔中出現頻次較高的標引項給予較大的權重。計算全局權重的典型方法就是逆文檔頻率IDF(Inverse Document Frequency)加權法。
gi = log(N / ni)
其中,N為系統文檔總數,ni為系統中含有標引詞ki的文檔數。
- 2.提問向量的構造
在向量空間模型中,用戶的信息需求被轉換為提問向量,並用與文檔向量類似的表示形式表示,即
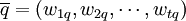
這裡,t為系統中標引詞的總數,向量分量wtq表示第i個標引詞ki在提問q中的權值,且有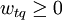 。對於查詢語詞的權值,Sahon和Buckley認為可以採用如下的方法:
。對於查詢語詞的權值,Sahon和Buckley認為可以採用如下的方法:

式中,freqiq為標引詞ki在表述用戶信息需求的文本內容中所出現的次數,而maxtfq則是在表述用戶信息需求的文本內容中所使用的所有標引詞出現次數的最大值。
- 3.文檔與提問向量相似度的計算
在文檔與提問向量化表示的基礎之上,文檔與查詢提問之間的相關程度(即相似度)就可以由它們各自向量在t維空間的相對位置來決定。
向量間相似程度的度量方法有很多種,主要有內積法(Inner Product)、Dice法(Dice Coefficient)、Jaccard法(Jaccard Coefficient)和餘弦法(Cosine Coefficient)。
較常用的度量方法是提問向量和文檔向量間的內積法,其計算公式如下:

其中,QTi是檢索提問中檢索項i的權值,DTi是文檔中標引項i的權值,N為總的項數。
當每個向量都通過餘弦法進行加權後,則內積法轉換為餘弦法。餘弦法採用的相似度計算指標是兩個向量夾角的餘弦函數。
向量空間模型的分析[2]
向量空間模型最早起源於文本信息檢索實踐,對揭示信息檢索的基本原理做出過重要貢獻。在VSM中,研究人員成功地將非結構化的文本信息表示成向量形式,為隨後的各種文本信息處理操作奠定了數學計算的基礎。向量空間模型在檢索處理中所具有的先進技術特征主要表現在以下幾個方面。
(1)對標引詞的權重進行了改進,其權重的計算可以通過對標引項出現頻率的統計方法自動完成,使問題的複雜性大為降低,從而改善了檢索效果。
(2)將文檔和查詢簡化為標引詞及其權重集合的向量表示,把對文檔內容和查詢要求的處理簡化為向量空間中向量的運算。
(3)採用部分匹配策略,使得在演算法層面上基於多值相關性的判斷處理得以實現。
(4)根據文檔和查詢之間的相似度對檢索結果進行排序,使對檢索結果數量的控制與調整具有相當的彈性與自由度,有效地提高了檢索效率。
當然,向量空間模型理論也存在著明顯的缺陷,具體包括以下幾個方面。
(1)從文檔中抽取出的各標引詞之間的關係做了相互獨立的基本假定,這會失掉大量的文本結構信息,如文檔句子中詞序的信息,因此降低了語義的準確性。
(2)相似度的計算鼉較大,當有新文檔加入時,必須重新計算標引詞的權重。
(3)在標引項權重的計算中,對不同語言單位構成的項都只考慮其統計信息,而僅以該信息來反映標引項的重要性,顯然缺乏全面性







{kind=link}