经济计量法
出自 MBA智库百科(https://wiki.mbalib.com/)
目录 |
由于增长会计法存在着较多缺陷,后人提出很多经济计量方法,以期借助各种经济计量模型和计量工具准确地估算出全要素生产率。本文主要比较两种计量方法,即隐性变量法和潜在产出法。
1. 隐性变量法(LV)
隐性变量法(latent variable approach ,LV) 的基本思路是,将全要素生产率视为一个隐性变量即未观测变量,从而借助状态空间模型(state space model) 利用极大似然估计给出全要素生产率估算。具体估算中,为了避免出现伪回归,需要进行模型设定检验包括数据平稳性检验和协整检验。平稳性检验和协整检验的方法很多,常见的有ADF (the Augmented Dickey2Fuller) 单位根检验和JJ(Johanson and Juselius ,1990) 协整检验。由于产出、劳动力和资本存量数据的趋势成分通常是单位根过程且三者之间不存在协整关系,所以往往利用产出、劳动力和资本存量的一阶差分序列来建立回归方程。采用C - D 生产函数,且假设规模收益不变,则有如下观测方程:
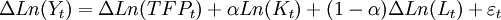 (1)
(1)
其中,ΔLn(TFPt) 为全要素生产率增长率,假设其为一个隐性变量,且遵循一阶自回归即AR (1) 过程,则有如下状态方程:
ΔLn(TFPt) = ρΔLn(TFPt − 1) + υt (2)
其中,ρ为自回归系数,满足| ρ| < 1 ,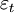 为白噪声。这样,利用状态空间模型,通过极大似然估计同时估算出观测方程(1) 和状态方程(2) ,从而得到全要素生产率增长的估算值。隐性变量法的最大优点在于,不再将全要素生产率视为残差,而是将其视为一个独立的状态变量,这样将全要素生产率从残差中分离出来,从而剔除掉一些测算误差对全要素生产率估算的影响。同时,在具体估算时,还充分考虑了数据非平稳性带来的伪回归问题。
为白噪声。这样,利用状态空间模型,通过极大似然估计同时估算出观测方程(1) 和状态方程(2) ,从而得到全要素生产率增长的估算值。隐性变量法的最大优点在于,不再将全要素生产率视为残差,而是将其视为一个独立的状态变量,这样将全要素生产率从残差中分离出来,从而剔除掉一些测算误差对全要素生产率估算的影响。同时,在具体估算时,还充分考虑了数据非平稳性带来的伪回归问题。
2. 潜在产出法(PO)
索洛残差法和隐性变量法在估算全要素生产率时,都暗含着一个重要的假设即认为经济资源得到充分利用,此时,全要素生产率增长就等于技术进步率。换言之,这两种方法在估算全要素生产率时,都忽略了全要素生产率增长的另一个重要组成部分———能力实现改善( improvement incapacity realization) 即技术效率提升的影响。潜在产出法(potential output approach ,PO) 也称边界生产函数法(frontier production function) 正是基于上述考虑提出的,其基本思路是遵循法雷尔(Farrell ,1957) 的思想,将经济增长归为要素投入增长、技术进步和能力实现改善(技术效率提升) 三部分,全要素生产率增长就等于技术进步率与能力实现率改善之和;估算出能力实现率和技术进步率,便给出全要素生产率增长率。[1]
设Ry , t为产出增长率, RTP,t为技术进步率, CRt 为能力实现率, Ryx,t 为要素投入增长所带来的产出增长率, RTFP,t为全要素生产率增长率,则
有:Ry,t = RTP,t + ΔCRt + Ryx,t (3)
且全要素生产率增长率等于技术进步率与能力实现率变化之和,即:
RTFP,t = RTP,t + ΔCRt (4)
能力实现率CRt 测度了现有生产能力的利用程度,反映了现实经济的生产技术效率,通常利用产出缺口来度量。产出缺口的估算方法很多,目前较为流行的是HP滤波(Hodrick-Prescott,1990) ,它是通过最小化(T为样本期) :
![\sum_{t=1}^T (LnY_t-LnY_{t}^{*})^2+\lambda \sum_{t=2}^{T-1}[Ln(Y_{t+1}^{*})-(LnY_{t}^{*}-LnY_{t-1}^{*})]^2](/w/images/math/e/b/8/eb82647b4805e104ae781c556725160a.png) (5)
(5)
从而将现实产出的自然对数LnYt 分解为趋势成分(即潜在产出的自然对数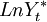 和周期性成分
(即产出缺口
和周期性成分
(即产出缺口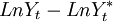 )。[2]
)。[2]
如前所述,索洛残差法和隐性变量法估算的全要素生产率增长率就等于技术进步率,鉴于索洛残差法较为粗糙,所以我们利用隐性变量法估算的全要素生产率增长率作为技术进步率RTP ,这样利用公式(4) 便得到全要素生产率的估算。潜在产出法最大的优点在于,全面考虑了技术进步和能力实现改善对全要素生产率增长的影响,且借助这种方法可以更全面地分析经济增长源泉。但它的缺点也很明显,主要体现在它是建立在产出缺口估算基础上,而无论用何种方法估算产出缺口,都会存在估算误差,从而导致全要素生产率增长率估算偏差。
- ↑ 潜在产出法可分为两类:一是参数随机边界分析(stochastic frontier analysis,SFA) ,其中较为流行的方法为Hildreth and Houck(1968) 的随机系数面板模(random coefficient panel model) ,这类方法可以很好地处理度量误差,但需要给出生产函数形式和分布的明确假设,对于样本量较少的实证研究而言,存在着较大问题(Gong and Sickles ,1992) 。二是非参数数据包络分析(data envelopmentanalysis ,DEA) ,这种方法直接利用线性优化给出边界生产函数与距离函数的估算,无需对生产函数形式和分布做出假设,从而避免了较强的理论约束。但这两类方法只适合于面板数据,并不能单独估算出某一主体的全要素生产率增长,所以本文没有采用这两种方法。
- ↑ 郭庆旺、贾俊雪(2004a) 详细比较分析了潜在产出与产出缺口的三种估算方法。







{kind=link}