检验效能
出自 MBA智库百科(https://wiki.mbalib.com/)
检验效能(power of test)
目录 |
什么是检验效能[1]
检验效能或把握度,是指两总体确有差别,按α水准能发现它们有差别的能力。用1-β表示其概率大小。
检验效能的估计[1]
检验效能只取单侧,一般认为检验效能至少取0.80。β表示第二类错误的概率,其大小很难确切估计。一般借助于求uβ,再查u值表估计β,然后求1-β。
假设检验结果出现P>α时,则不拒绝检验假设H0,称差别无统计学意义,临床常叫“阴性”结果。但“阴性”结果有两种可能:①β较小,即1-β较大,或当样本含量n>400时,就认为被比较的指标间很可能无差别。②β较大,即1-β较小,如小于0.80(也有学者认为小于0.70),且n<400时,便认为所比较的指标间很可能差异有统计学意义,由于样本含量不足未 能发现,是“假阴性”结果。因此在估算样本含量时,要考虑检验效能。部分计算uβ的公式是由样本含量估算式、通过恒等变换导出,故统计符号与意义均相同。
常用计算uβ的公式如下。
1.两样本均数比较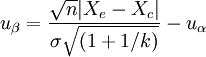 (1)
(1)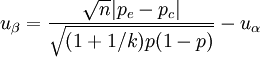 (2)
(2)3.病例对照研究
非配对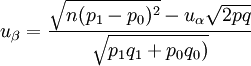 (3)
(3)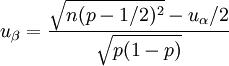 (4)
(4)![u_\beta=\frac{[n(p_1-p_0)^2]-u_\alpha[(1+1/c)pq]^{1/2}}{[p_0q_0+p_1q_1/c]^{1/2}}](/w/images/math/0/2/a/02aa0b72993e6891e9c6cc3975e97a0f.png) (5)
(5)例1 某医师研究药物对宫缩及外阴创伤的镇痛效果,若新药组观察40例、镇痛率 75%,旧药组观察60例、镇痛率55%,当单侧U0.05 = 1.6449,问该试验检验效能如何?
本例试验组有效率pe = 0.75、样本含量ne = 40;对照组有效率pc = 0.55、样本含量nc = 60,平均有效率P=(40×0.75+60×0.55)/(40+60)=0.63;k=60/40=1.5,又试验组n=40、对照组kn=60,已知U0.05 = 1.6449,代入式(2),得: (2)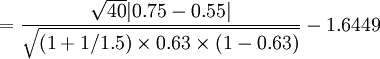
以uβ = 0.3845查u值表,得0.40>β>0.30,即0.60<1-β<0.70。故该试验检验效能为0.60~0.70,可认为该试验检验效能小,与样本含量不足有关。
检验效能的决定因素[2]
检验效能的大小主要与以下四个因素有关。
(1)总体差别的大小:正确选择被试因素及其水平,这是实验成败的首要环节。被试因素的有效性越强,H0与H1涉及的不同总体均数之间的差距越大,两者在分布上的重叠面积就越小。由于β较小,1-β就必然较大。
(2)检验水准(α)的大小:通常H0与H1两个总体存在一定的重叠面积,界值移动必然引起α与β同时改变。由于α与β存在反变关系,故通过增大口值可提高检验效能1-β。然而假设检验的目的大多是希望提示被试因素有效性高,应当要求d值越小越好;若将α值过分增大,显然是不恰当的。相反,如将α过分缩小,势必引起β增大,检验效能降低。因此,在实验设计时,必须合理地兼顾α与β。在通常情况下,实验设计时α取0.05,β取0.10或0.05。
(3)标准差的大小:由于α与β呈反比,两全其美的方法就是使两个相互比较的总体分布都很集中,重叠面积缩小,这样就可收到α与β均减小的效果。在两个总体均数与样本含量固定的条件下,各总体分布的面积不变,但其扩布范围与标准差成正比。因此,尽量减小个体差异,严格控制实验条件,认真遵守操作规程,努力使标准差减小到合理水平,这是提高检验效能的重要途径之一。
(4)样本含量的多少:在两总体均数与标准差固定的条件下,尽管总体分布的扩布范围不变,但随着样本含量(n)增大,标准误缩小,总体分布趋向集中,α与β都减小,因而检验效能增加。所以,对于提高检验效能而言,增大样本含量,这也是一种两全其美的办法。在理论上,任何真实存在的差异不论大小与有无实际意义,只要有足够大的咒,通过假设检验都可以检出具有统计意义。然而在科研中必须首先考虑差异程度的实际意义,不能盲目地扩大样本含量。同时也应看到:样本含量由n增大至m倍(即m×n),标准误仅缩小至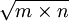 倍。例如,样本含量由n增至9n,标准误
倍。例如,样本含量由n增至9n,标准误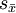 仅减至原来的1/3。因此,通过增大n来提高检验效能,其代价是相当高的,在数量上必须适可而止。
仅减至原来的1/3。因此,通过增大n来提高检验效能,其代价是相当高的,在数量上必须适可而止。
检验效能的意义[3]
检验效能,又称假设检验的功效(power of a test),用1-β表示,其意义是,当所研究的总体与H0确有差别时,按照检验水准α能够发现它(拒绝H0)的概率。若1-β=0.90,则意味着当H0不成立时,理论上在100次抽样实验中,在α检验水准上平均有90次能拒绝H0。检验效能可用小数(或百分数)表示,一般取0.99、0.95、0.90、0.80、0.50。研究中要求的检验效能越高,所需的样本含量也越大。样本含量、客观事物差异的大小、个体间变异的大小和α值都是影响检验功效的要素。当样本含量固定时,α与β呈反向变化的关系,即α增大,β减小,反之亦然;若欲同时减小α与β,则只有增加样本含量。因此,若要增大检验效能(增大1-β,减小β),一是增大α,二是增大样本含量。
检验效能虽然不是设计时需要解决的,但在查阅文献和借鉴前人经验时应当认真考虑。当假设检验根据P>0.05做出无统计学意义的结论时,研究者则面临着犯Ⅱ型错误的可能性,应当考虑是否总体间的差异确实存在,但由于检验效能不足而未能把该差异反映出来。







{kind=link}
第一行的概念错了是按啊发 发现其差异的能力不是。贝塔