标准偏差
出自 MBA智库百科(https://wiki.mbalib.com/)
标准偏差(Std Dev,Standard Deviation)
目录 |
标准偏差(也称标准离差或均方根差)是反映一组测量数据离散程度的统计指标。是指统计结果在某一个时段内误差上下波动的幅度。是正态分布的重要参数之一。是测量变动的统计测算法。它通常不用作独立的指标而与其它指标配合使用。
标准偏差在误差理论、质量管理、计量型抽样检验等领域中均得到了广泛的应用。因此, 标准偏差的计算十分重要, 它的准确与否对器具的不确定度、测量的不确定度以及所接收产品的质量有重要影响。然而在对标准偏差的计算中, 不少人不论测量次数多少, 均按贝塞尔公式计算。
数学表达式:
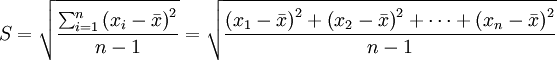
- S-标准偏差(%)
- n-试样总数或测量次数,一般n值不应少于20-30个
- i-物料中某成分的各次测量值,1~n;

- 在价格变化剧烈时,该指标值通常很高。
- 如果价格保持平稳,这个指标值不高。
- 在价格发生剧烈的上涨/下降之前,该指标值总是很低。
标准偏差的计算步骤是:
步骤一、(每个样本数据 - 样本全部数据之平均值)2。
步骤二、把步骤一所得的各个数值相加。
步骤三、把步骤二的结果除以 (n - 1)(“n”指样本数目)。
步骤四、从步骤三所得的数值之平方根就是抽样的标准偏差。
六个计算标准偏差的公式[1]
设对真值为X的某量进行一组等精度测量, 其测得值为l1、l2、……ln。令测得值l与该量真值X之差为真差占σ, 则有 σ1 = li − X
σ2 = l2 − X
……
σn = ln − X
我们定义标准偏差σ为
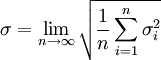
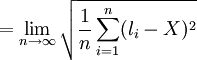 (1)
(1)
由于真值X都是不可知的, 因此真差σ占也就无法求得, 故式只有理论意义而无实用价值。
由于真值是不可知的, 在实际应用中, 我们常用n次测量的算术平均值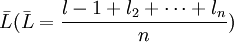 来代表真值。理论上也证明, 随着测量次数的增多, 算术平均值最接近真值, 当
来代表真值。理论上也证明, 随着测量次数的增多, 算术平均值最接近真值, 当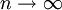 时, 算术平均值就是真值。
时, 算术平均值就是真值。
于是我们用测得值li与算术平均值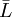 之差——剩余误差(也叫残差)Vi来代替真差σ , 即
之差——剩余误差(也叫残差)Vi来代替真差σ , 即
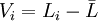
设一组等精度测量值为l1、l2、……ln
则 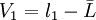
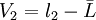
……
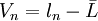
通过数学推导可得真差σ与剩余误差V的关系为
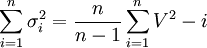
将上式代入式(1)有
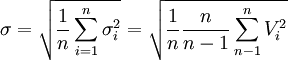
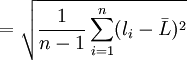 (2)
(2)
式(2)就是著名的贝塞尔公式(Bessel)。
它用于有限次测量次数时标准偏差的计算。由于当时,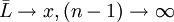 ,可见贝塞尔公式与σ的定义式(1)是完全一致的。
,可见贝塞尔公式与σ的定义式(1)是完全一致的。
应该指出, 在n有限时, 用贝塞尔公式所得到的是标准偏差σ的一个估计值。它不是总体标准偏差σ。因此, 我们称式(2)为标准偏差σ的常用估计。为了强调这一点, 我们将σ的估计值用“S ” 表示。于是, 将式(2)改写为
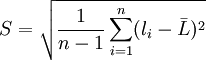 (2')
(2')
在求S时, 为免去求算术平均值的麻烦, 经数学推导(过程从略)有
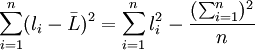
于是, 式(2')可写为
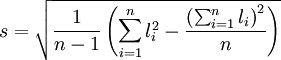 (2")
(2")
按式(2")求S时, 只需求出各测得值的平方和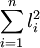 和各测得值之和的平方艺
和各测得值之和的平方艺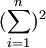 , 即可。
, 即可。
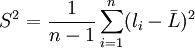
数学上已经证明S2是总体方差σ2的无偏估计。即在大量重复试验中, S2围绕σ2散布, 它们之间没有系统误差。而式(2')在n有限时,S并不是总体标准偏差σ的无偏估计, 也就是说S和σ之间存在系统误差。概率统计告诉我们, 对于服从正态分布的正态总体, 总体标准偏差σ的无偏估计值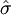 为
为
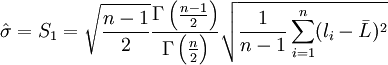 (3)
(3)
令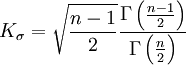
则 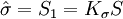
即S1和S仅相差一个系数Kσ,Kσ是与样本个数测量次数有关的一个系数, Kσ值见表。
计算Kσ时用到
Γ(n + 1) = nΓ(n)
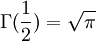
Γ(1) = 1

由表1知, 当n>30时, 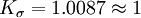 。因此, 当n>30时, 式(3')和式(2')之间的差异可略而不计。在n=30~50时, 最宜用贝塞尔公式求标准偏差。当n<10时, 由于Kσ值的影响已不可忽略, 宜用式(3'), 求标准偏差。这时再用贝塞尔公式显然是不妥的。
。因此, 当n>30时, 式(3')和式(2')之间的差异可略而不计。在n=30~50时, 最宜用贝塞尔公式求标准偏差。当n<10时, 由于Kσ值的影响已不可忽略, 宜用式(3'), 求标准偏差。这时再用贝塞尔公式显然是不妥的。
将σ的定义式(1)中的真值X用算术平均值代替且当n有限时就得到
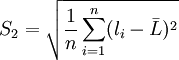
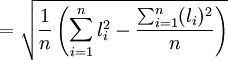 (4)
(4)
式(4)适用于n>50时的情况, 当n>50时,n和(n-1)对计算结果的影响就很小了。
2.5标准偏差σ的极差估计由于以上几个标准偏差的计算公式计算量较大, 不宜现场采用, 而极差估计的方法则有运算简便, 计算量小宜于现场采用的特点。
极差用"R"表示。所谓极差就是从正态总体中随机抽取的n个样本测得值中的最大值与最小值之差。
若对某量作次等精度测量测得l1、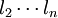 ,且它们服从正态分布, 则
,且它们服从正态分布, 则
R = lmax − lmin
概率统计告诉我们用极差来估计总体标准偏差的计算公式为
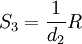 (5)
(5)
S3称为标准偏差σ的无偏极差估计, d2为与样本个数n(测得值个数)有关的无偏极差系数, 其值见表2

由表2知, 当n≤15时,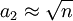 , 因此, 标准偏差σ更粗略的估计值为
, 因此, 标准偏差σ更粗略的估计值为
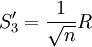 (5')
(5')
还可以看出, 当200≤n≤1000时,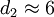 因而又有
因而又有
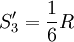 (5")
(5")
显然, 不需查表利用式(5')和(5")了即可对标准偏差值作出快速估计, 用以对用贝塞尔公式及其他公式的计算结果进行校核。
应指出,式(5)的准确度比用其他公式的准确度要低, 但当5≤n≤15时,式(5)不仅大大提高了计算速度, 而且还颇为准确。当n>10时, 由于舍去数据信息较多, 因此误差较大, 为了提高准确度, 这时应将测得值分成四个或五个一组, 先求出各组的极差R1、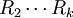 , 再由各组极差求出极差平均值
, 再由各组极差求出极差平均值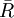 。
。
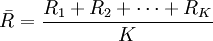
极差平均值和总体标准偏差的关系为
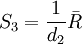
需指出, 此时d2大小要用每组的数据个数n而不是用数据总数N(=nK)去查表2。再则, 分组时一定要按测得值的先后顺序排列,不能打乱或颠倒。
平均误差的定义为
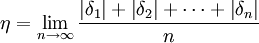
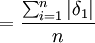
误差理论给出
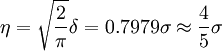 (A)
(A)
可以证明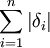 与
与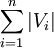 的关系为
的关系为
(证明从略)
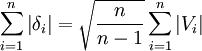
于是 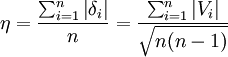 (B)
(B)
由式(A)和式(B)得
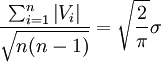
从而有
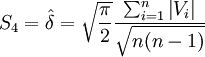
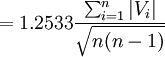
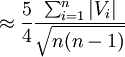
式(6)就是佩特斯(C.A.F.Peters.1856)公式。用该公式估计δ值, 由于\right|V\right|不需平方,故计算较为简便。但该式的准确度不如贝塞尔公式。该式使用条件与贝塞尔公式相似。
标准偏差的应用实例[1]
对标称值Ra = 0.160 < math > μm < math > 的一块粗糙度样块进行检定, 顺次测得以下15个数据:1.45,1.65,1.60,1.67,1.52,1.46,1.72,1.69,1.77,1.64,4.56,1.50,1.64,1.74和1.63μm, 试求该样块Rn的平均值和标准偏差并判断其合格否。
解:1)先求平均值
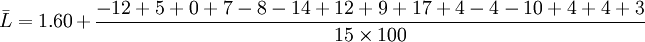
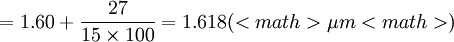
2)再求标准偏差S
若用无偏极差估计公式式(5)计算, 首先将测得的, 15个数据按原顺序分为三组, 每组五个, 见表3。
表3
组号 l_1 l_5 R 1 1.48 1.65 1.60 1.67 1.52 0.19 2 1.46 1.72 1.69 1.77 1.64 0.31 3 1.56 1.50 1.64 1.74 1.63 0.24
因每组为5个数据, 按n=5由表2查得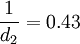
故
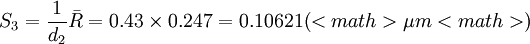
若按常用估计即贝塞尔公式式(2') , 则
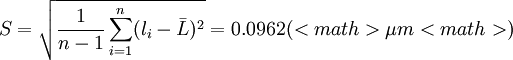
若按无偏估计公式即式(3')计算, 因n=15,由表1查得Kδ = 1.018, 则
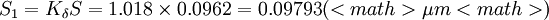
若按最大似然估计公式即式(4')计算, 则
![S_2=\sqrt{\frac{1}{n}\left[\sum^n_{i=1}l^2_i-\frac{(\sum^n_{i=1}l_i)^2}{n}\right]}](/w/images/math/3/a/1/3a1618dde60cf9bc00acc01adfd5ec7f.png)
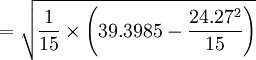
= 0.09296( < math > μm < math > )
若按平均误差估计公式即式(6), 则
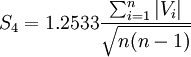
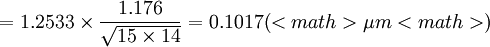
现在用式(5')对以上计算进行校核
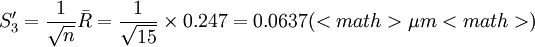
可见以上算得的S、S1、S2、S3和S4没有粗大误差。
由以上计算结果可知0.09296<0.0962<0.0979<0.1017<0.1062
即 S2 < S < S1 < S4 < S3
可见, 最大似然估计值最小, 常用估计值S稍大, 无偏估计值S1又大, 平均误差估计值S4再大, 极差估计值S3最大。纵观这几个值, 它们相当接近, 最大差值仅为0.01324μm。从理论上讲, 用无偏估计值和常用估计比较合适, 在本例中, 它们仅相差0.0017μm。可以相信, 随着的增大, S、S1、S2、S3和S4之间的差别会越来越小。
就本例而言, 无偏极差估计值S3和无偏估计值S1仅相差0.0083μm, 这说明无偏极差估计是既可以保证一定准确度计算又简便的一种好方法。
JJG102-89《表面粗糙度比较样块》规定Ra的平均值对其标称值的偏离不应超过+12%~17%, 标准偏差应在标称值的4%~12%之间。已得本样块二产,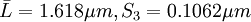 产均在规定范围之内, 故该样块合格。
产均在规定范围之内, 故该样块合格。
标准差(Standard Deviation)各数据偏离平均数的距离(离均差)的平均数,它是离差平方和平均后的方根。用σ表示。因此,标准差也是一种平均数。标准差是方差的算术平方根。 标准差能反映一个数据集的离散程度。平均数相同的,标准差未必相同。
例如,A、B两组各有6位学生参加同一次语文测验,A组的分数为95、85、75、65、55、45,B组的分数为73、72、71、69、68、67。这两组的平均数都是70,但A组的标准差为17.08分,B组的标准差为2.16分,说明A组学生之间的差距要比B组学生之间的差距大得多。
标准偏差(Std Dev,Standard Deviation) - 统计学名词。一种量度数据分布的分散程度之标准,用以衡量数据值偏离算术平均值的程度。标准偏差越小,这些值偏离平均值就越少,反之亦然。标准偏差的大小可通过标准偏差与平均值的倍率关系来衡量。

评论(共10条)
可以請教一題嗎? 甲組:2.9 2.9 3.0 3.1 3.1 乙組:2.8 3.0 3.0 3.0 3.2 我計算出平均值各是3.0 平均偏差 D甲:0.08 / D乙:0.08 可是標準偏差S是怎麼算出來呢?
可以請教一題嗎? 甲組:2.9 2.9 3.0 3.1 3.1 乙組:2.8 3.0 3.0 3.0 3.2 我計算出平均值各是3.0 平均偏差 D甲:0.08 / D乙:0.08 可是標準偏差S是怎麼算出來呢?
按上面的计算步骤来算,甲:0.1;乙:0.141。不知道对不对
按上面的计算步骤来算,甲:0.1;乙:0.141。不知道对不对
我也认为甲是0.1,乙是0.14
所以意思是「標準偏差=標準差」嗎?
看不太懂
按楼主的意思应该是这样






{kind=link}
谢谢了,非常有用。正不知道怎么办呢,万分感谢