层次分析法
出自 MBA智库百科(https://wiki.mbalib.com/)
层次分析法(The analytic hierarchy process,简称AHP),也称层级分析法
目录 |
层次分析法(The analytic hierarchy process)简称AHP,在20世纪70年代中期由美国运筹学家托马斯·塞蒂(T.L.saaty)正式提出。它是一种定性和定量相结合的、系统化、层次化的分析方法。由于它在处理复杂的决策问题上的实用性和有效性,很快在世界范围得到重视。它的应用已遍及经济计划和管理、能源政策和分配、行为科学、军事指挥、运输、农业、教育、人才、医疗和环境等领域。
层次分析法的基本思路与人对一个复杂的决策问题的思维、判断过程大体上是一样的。不妨用假期旅游为例:假如有3个旅游胜地A、B、C供你选择,你会根据诸如景色、费用和居住、饮食、旅途条件等一些准则去反复比较这3个候选地点.首先,你会确定这些准则在你的心目中各占多大比重,如果你经济宽绰、醉心旅游,自然分别看重景色条件,而平素俭朴或手头拮据的人则会优先考虑费用,中老年旅游者还会对居住、饮食等条件寄以较大关注。其次,你会就每一个准则将3个地点进行对比,譬如A景色最好,B次之;B费用最低,C次之;C居住等条件较好等等。最后,你要将这两个层次的比较判断进行综合,在A、B、C中确定哪个作为最佳地点。
1、建立层次结构模型。在深入分析实际问题的基础上,将有关的各个因素按照不同属性自上而下地分解成若干层次,同一层的诸因素从属于上一层的因素或对上层因素有影响,同时又支配下一层的因素或受到下层因素的作用。最上层为目标层,通常只有1个因素,最下层通常为方案或对象层,中间可以有一个或几个层次,通常为准则或指标层。当准则过多时(譬如多于9个)应进一步分解出子准则层。
2、构造成对比较阵。从层次结构模型的第2层开始,对于从属于(或影响)上一层每个因素的同一层诸因素,用成对比较法和1—9比较尺度构造成对比较阵,直到最下层。
3、计算权向量并做一致性检验。对于每一个成对比较阵计算最大特征根及对应特征向量,利用一致性指标、随机一致性指标和一致性比率做一致性检验。若检验通过,特征向量(归一化后)即为权向量:若不通过,需重新构造成对比较阵。
4、计算组合权向量并做组合一致性检验。计算最下层对目标的组合权向量,并根据公式做组合一致性检验,若检验通过,则可按照组合权向量表示的结果进行决策,否则需要重新考虑模型或重新构造那些一致性比率较大的成对比较阵。
运用层次分析法有很多优点,其中最重要的一点就是简单明了。层次分析法不仅适用于存在不确定性和主观信息的情况,还允许以合乎逻辑的方式运用经验、洞察力和直觉。也许层次分析法最大的优点是提出了层次本身,它使得买方能够认真地考虑和衡量指标的相对重要性。
将问题包含的因素分层:最高层(解决问题的目的);中间层(选择为实现总目标而采取的各种措施、方案所必须遵循的准则。也可称策略层、约束层、准则层等);最低层(用于解决问题的各种措施、方案等)。把各种所要考虑的因素放在适当的层次内。用层次结构图清晰地表达这些因素的关系。
〔例1〕 购物模型
某一个顾客选购电视机时,对市场正在出售的四种电视机考虑了八项准则作为评估依据,建立层次分析模型如下:

〔例2〕 选拔干部模型
对三个干部候选人y1、y2 、y3,按选拔干部的五个标准:品德、才能、资历、年龄和群众关系,构成如下层次分析模型: 假设有三个干部候选人y1、y2 、y3,按选拔干部的五个标准:品德,才能,资历,年龄和群众关系,构成如下层次分析模型

比较第 i 个元素与第 j 个元素相对上一层某个因素的重要性时,使用数量化的相对权重aij来描述。设共有 n 个元素参与比较,则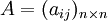 称为成对比较矩阵。
称为成对比较矩阵。
成对比较矩阵中aij的取值可参考 Satty 的提议,按下述标度进行赋值。aij在 1-9 及其倒数中间取值。
- aij = 1,元素 i 与元素 j 对上一层次因素的重要性相同;
- aij = 3,元素 i 比元素 j 略重要;
- aij = 5,元素 i 比元素 j 重要;
- aij = 7, 元素 i 比元素 j 重要得多;
- aij = 9,元素 i 比元素 j 的极其重要;
- aij = 2n,n=1,2,3,4,元素 i 与 j 的重要性介于aij = 2n − 1与aij = 2n + 1之间;
-
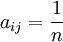 ,n=1,2,...,9, 当且仅当aji = n。
,n=1,2,...,9, 当且仅当aji = n。
成对比较矩阵的特点: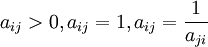 。(备注:当i=j时候,aij = 1)
。(备注:当i=j时候,aij = 1)
对例 2, 选拔干部考虑5个条件:品德x1,才能x2,资历x3,年龄x4,群众关系x5。某决策人用成对比较法,得到成对比较阵如下:
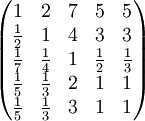
a14 = 5 表示品德与年龄重要性之比为 5,即决策人认为品德比年龄重要。
从理论上分析得到:如果A是完全一致的成对比较矩阵,应该有
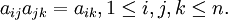
但实际上在构造成对比较矩阵时要求满足上述众多等式是不可能的。因此退而要求成对比较矩阵有一定的一致性,即可以允许成对比较矩阵存在一定程度的不一致性。
由分析可知,对完全一致的成对比较矩阵,其绝对值最大的特征值等于该矩阵的维数。对成对比较矩阵 的一致性要求,转化为要求: 的绝对值最大的特征值和该矩阵的维数相差不大。
检验成对比较矩阵A一致性的步骤如下:
- 计算衡量一个成对比较矩阵 A (n>1 阶方阵)不一致程度的指标CI:
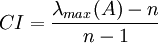
RI是这样得到的:对于固定的n,随机构造成对比较阵A, 其中aij是从1,2,…,9,1/2,1/3,…,1/9中随机抽取的. 这样的A是不一致的, 取充分大的子样得到A的最大特征值的平均值
| n | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| RI | 0 | 0 | 0.58 | 0.90 | 1.12 | 1.24 | 1.32 | 1.41 | 1.45 |
注解:
- 从有关资料查出检验成对比较矩阵 A 一致性的标准RI:RI称为平均随机一致性指标,它只与矩阵阶数 n 有关。
- 按下面公式计算成对比较阵 A 的随机一致性比率 CR:
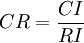 。
。
- 判断方法如下: 当CR<0.1时,判定成对比较阵 A 具有满意的一致性,或其不一致程度是可以接受的;否则就调整成对比较矩阵 A,直到达到满意的一致性为止。
例如对例 2 的矩阵
计算得到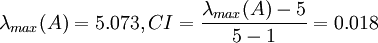 ,查得RI=1.12,
,查得RI=1.12,
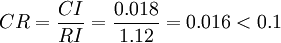
这说明 A 不是一致阵,但 A 具有满意的一致性,A 的不一致程度是可接受的。
此时A的最大特征值对应的特征向量为U=(-0.8409,-0.4658,-0.0951,-0.1733,-0.1920)。 这个向量也是问题所需要的。通常要将该向量标准化:使得它的各分量都大于零,各分量之和等于 1。该特征向量标准化后变成U = (0.475,0.263,0.051,0.103,0.126)Z。经过标准化后这个向量称为权向量。这里它反映了决策者选拔干部时,视品德条件最重要,其次是才能,再次是群众关系,年龄因素,最后才是资历。各因素的相对重要性由权向量U的各分量所确定。
求A的特征值的方法,可以用 MATLAB 语句求A的特征值:〔Y,D〕=eig(A),D为成对比较阵 的特征值,Y的列为相应特征向量。
在实践中,可采用下述方法计算对成对比较阵A = (aij)的最大特征值λmax(A)和相应特征向量的近似值。
定义
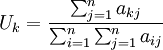 ,
,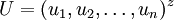
可以近似地看作A的对应于最大特征值的特征向量。
计算
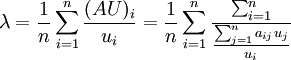
可以近似看作A的最大特征值。实践中可以由λ来判断矩阵A的一致性。
现在来完整地解决例 2 的问题,要从三个候选人y1,y2,y3中选一个总体上最适合上述五个条件的候选人。对此,对三个候选人y = y1,y2,y3分别比较他们的品德(x1),才能(x2),资历(x3),年龄(x4),群众关系(x5)。
先成对比较三个候选人的品德,得成对比较阵
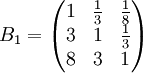
经计算,B1的权向量
ωx1(Y) = (0.082,0.236,0.682)z
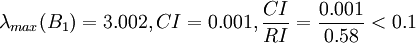
故B1的不一致程度可接受。ωx1(Y)可以直观地视为各候选人在品德方面的得分。
类似地,分别比较三个候选人的才能,资历,年龄,群众关系得成对比较阵
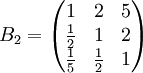
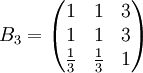
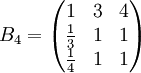
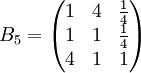
通过计算知,相应的权向量为
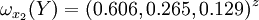
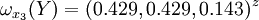
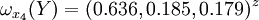
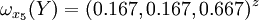
它们可分别视为各候选人的才能分,资历分,年龄分和群众关系分。经检验知B2,B3,B4,B5的不一致程度均可接受。
最后计算各候选人的总得分。y1的总得分
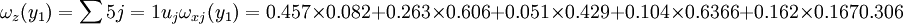
从计算公式可知,y1的总得分ω(y1)实际上是y1各条件得分ωx1(y1) ,ωx2(y1) ,...,ωx5(y1) ,的加权平均, 权就是各条件的重要性。同理可得y2,Y3 的得分为
ωz(y2) = 0.243,ωz(y3) = 0.452
| 0.457 | 0.263 | 0.051 | 0.103 | 0.126 | 总得分 | |
| Y1 | 0.082 | 0.606 | 0.429 | 0.636 | 0.167 | 0.305 |
| Y2 | 0.244 | 0.265 | 0.429 | 0.185 | 0.167 | 0.243 |
| Y3 | 0.674 | 0.129 | 0.143 | 0.179 | 0.667 | 0.452 |
即排名:Y3 > Y1 > Y2
比较后可得:候选人y3是第一干部人选。
例如,某人准备选购一台电冰箱,他对市场上的6种不同类型的电冰箱进行了解后,在决定买那一款式时,往往不是直接拿电冰箱整体进行比较,因为存在许多不可比的因素,而是选取一些中间指标进行考察。例如电冰箱的容量、制冷级别、价格、型号、耗电量、外界信誉、售后服务等。然后再考虑各种型号冰箱在上述各中间标准下的优劣排序。借助这种排序,最终作出选购决策。在决策时,由于6种电冰箱对于每个中间标准的优劣排序一般是不一致的,因此,决策者首先要对这7个标准的重要度作一个估计,给出一种排序,然后把6种冰箱分别对每一个标准的排序权重找出来,最后把这些信息数据综合,得到针对总目标即购买电冰箱的排序权重。有了这个权重向量,决策就很容易了。
运用AHP法进行决策时,需要经历以下5个步骤:
1、建立系统的递阶层次结构;
2、构造两两比较判断矩阵;(正互反矩阵)
3、针对某一个标准,计算各备选元素的权重;
4、计算当前一层元素关于总目标的排序权重。
5、进行一致性检验。
如果所选的要素不合理,其含义混淆不清,或要素间的关系不正确,都会降低AHP法的结果质量,甚至导致AHP法决策失败。
为保证递阶层次结构的合理性,需把握以下原则:
1、分解简化问题时把握主要因素,不漏不多;
2、注意相比较元素之间的强度关系,相差太悬殊的要素不能在同一层次比较。
1、建立递阶层次结构;
2、构造两两比较判断矩阵;(正互反矩阵)
对各指标之间进行两两对比之后,然后按9分位比率排定各评价指标的相对优劣顺序,依次构造出评价指标的判断矩阵。
3、针对某一个标准,计算各备选元素的权重;
关于判断矩阵权重计算的方法有两种,即几何平均法(根法)和规范列平均法(和法)。
(1)几何平均法(根法)
计算判断矩阵A各行各个元素mi的乘积;
计算mi的n次方根;
对向量进行归一化处理;
该向量即为所求权重向量。
(2)规范列平均法(和法)
计算判断矩阵A各行各个元素mi的和;
将A的各行元素的和进行归一化;
该向量即为所求权重向量。
计算矩阵A的最大特征值?max
对于任意的i=1,2,…,n, 式中为向量AW的第i个元素
(4)一致性检验
构造好判断矩阵后,需要根据判断矩阵计算针对某一准则层各元素的相对权重,并进行一致性检验。虽然在构造判断矩阵A时并不要求判断具有一致性,但判断偏离一致性过大也是不允许的。因此需要对判断矩阵A进行一致性检验。

本条目由以下用户参与贡献
村姑,funwmy,苦行者,Vulture,Zfj3000,Lolo,001,Angle Roh,18°@鷺島,Mathfei,Jiejie,Cabbage,刘永祥,Yixi,Yutian85,快乐的风,Luckyxia0703,Freeheart,陈蹊,Ywlshuwei,Dan,阿南,y桑,chonglie,卢晔,LuyinT,spiitfrie,M id c23aeccbd78f69e05067a552d39e7ef8.评论(共54条)
谢谢,已更正。
能不能给出一些运用AHP的例子呢?谢谢
现已给某一购房者的情况为例,望指教。
举出的实例,数据有误,请作者是否考虑交验一下。
因该条目为网友贡献,无法获知其出处,已对其内容进行了更改,感谢您的指正,MBA智库百科是可以自由编辑的,您也可以直接参与编辑修改。
超过9阶RI表能否提供 急需 谢谢
9 10 11 12 13 14 15
1.45 1.49 1.51 1.48 1.56 1.57 1.58
不好意思,上邊 表格沒處理好
实际上这个方法使用简单的数学知识就可以完全说明白,里面比较复杂的就是开平方,其它的就是加减乘除找平均数啥的。
国外的MBA教程上,都是使用最简单的方法在教原理和过程,实在搞不明白国内的教程为什么一定要用这些看起来很高深的东西。。。。
明显有错误!
MBA智库是可以自由编辑的,有误之处期待您的参与完善,或者您指出错误之处,以便完善。
实际上这个方法使用简单的数学知识就可以完全说明白,里面比较复杂的就是开平方,其它的就是加减乘除找平均数啥的。
国外的MBA教程上,都是使用最简单的方法在教原理和过程,实在搞不明白国内的教程为什么一定要用这些看起来很高深的东西。。。。
我觉得一看就懂 只要线性代数还记得的话。。。
到底是satty教授还是saaty教授啊???
是T.L.Saaty
谢谢......
请问最大特征根怎么求得?谢谢!
用matlab可以直接求得
实际上这个方法使用简单的数学知识就可以完全说明白,里面比较复杂的就是开平方,其它的就是加减乘除找平均数啥的。
国外的MBA教程上,都是使用最简单的方法在教原理和过程,实在搞不明白国内的教程为什么一定要用这些看起来很高深的东西。。。。
这个方法很简单啊
谢谢指正,原文已修正!~
求最大特征值只需要先列向量求和归一,求出特征向量,然后通过归一后向量与特征向量的对应比的平均数,得出近似最大特征值(与精确值相差很小)。
特征值的求法课利用mathematica软件:利用函数Eigenvalues[N[{{},{},{},...}]]便可求出
%层次分析法的matlab程序 disp('请输入判断矩阵A(n阶)'); A=input('A='); [n,n]=size(A); x=ones(n,100); y=ones(n,100); m=zeros(1,100); m(1)=max(x(:,1)); y(:,1)=x(:,1); x(:,2)=A*y(:,1); m(2)=max(x(:,2)); y(:,2)=x(:,2)/m(2); p=0.0001;i=2;k=abs(m(2)-m(1)); while k>p i=i+1; x(:,i)=A*y(:,i-1); m(i)=max(x(:,i)); y(:,i)=x(:,i)/m(i); k=abs(m(i)-m(i-1)); end a=sum(y(:,i)); w=y(:,i)/a; t=m(i); disp('权向量');disp(w); disp('最大特征值');disp(t); %以下是一致性检验 CI=(t-n)/(n-1);RI=[0 0 0.52 0.89 1.12 1.26 1.36 1.41 1.46 1.49 1.52 1.54 1.56 1.58 1.59]; CR=CI/RI(n); if CR<0.10 disp('此矩阵的一致性可以接受!'); disp('CI=');disp(CI); disp('CR=');disp(CR); else disp('此矩阵的一致性不可以接受!'); end
Saaty吧
很不错但我想知道判断 矩阵中的值是怎么给的多谢
请多人(专家)按照九级打分,取平均值,然后计算。
很不错但我想知道判断 矩阵中的值是怎么给的多谢
由对本项目熟悉的人员(专家)打分,取平均值。
应该是 Saaty, Thomas L 刚看完他的英文版原著
应该是“Saaty”,而不是“Satty”,估计这是个拼写手误
你的是对的,我给改过来的,MBA智库百科是可以自由编辑的,你有更多的资源可以和我们一起编辑分享纠正哦~
好繁琐啊,选来选去也只是相对较优的策略,就是一句话综合自己的需求考虑呗。
很不错但我想知道判断 矩阵中的值是怎么给的多谢
一般是专家打分法






提出者是美国运筹学家T.L.Satty,而不是seaty?能否确认一下?