時間序列分解法
出自 MBA智库百科(https://wiki.mbalib.com/)
時間序列分解法(Time-series Decomposition)
目錄 |
時間序列分解法是數年來一直非常有用的方法,這種方法包括譜分析、時間序列分析和傅立葉級數分析等。
時間序列y可以表示為以上四個因素的函數,即:
Yt = f(Tt,St,Ct,It)
時間序列分解的方法有很多,較常用的模型有加法模型和乘法模型。
加法模型為: Yt = Tt + St + Ct + It
乘法模型為:
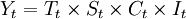
(1)運用移動平均法剔除長期趨勢和周期變化,得到序列TC。然後再用按月(季)平均法求出季節指數S。
(2)做散點圖,選擇適合的曲線模型擬合序列的長期趨勢,得到長期趨勢T。
(3)計算周期因素C。用序列TC除以T即可得到周期變動因素C。
(4)將時間序列的T、S、C分解出來後,剩餘的即為不規則變動,即:
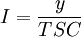
時間序列一般包括四類因素,長期趨勢因素、季節變動因素、迴圈變動因素和不規則變動因素。四種因素的組合形式一般有以下幾類, 其中記Xt為時間序列的全變動;Tt為長期趨勢;St為季節變動;Ct為迴圈變動;It為不規則變動,它總是存在著的。
1) 乘法模式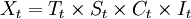 ,其中,
,其中,
a) Xt與Tt有相同的量綱,St為季節指數,Ct為迴圈指數,兩者皆為比例數;
b) 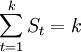
c) It是獨立隨機變數序列,服從正態分佈。
2)加法模式 Xt = Tt + St + Ct + It
這種形式要求滿足條件:
a) Xt,Tt,St,Ct,It均有相同的量綱;
b) 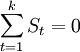 ,k為季節性周期長度;
,k為季節性周期長度;
c) It是獨立隨機變數序列,服從正態分佈。
3) 混合模式 
a) Xt與Tt,Ct,It有相同的量綱,St是季節指數,為比例數;
b)
c) It是獨立隨機變數序列,服從正態分佈。
時間序列分解法試圖從時間序列中區分出這四種潛在的因素,特別是長期趨勢因素(T)、季節變動因素(S)和迴圈變動因素(C)。顯然,並非每一個預測對象中都存在著T、S、C這三種趨勢,可能是其中的一種或兩種。一個具體的時間序列究竟由哪幾類變動組合,採取哪種組合形式,應根據所掌握的資料、時間序列及研究目的來確定。
分解法的基礎是容易理解而且直觀的。不過最重要的是它為預測和檢驗提供了獨特和非常有用的資料。我們用一個例題來說明各個因素分解的步驟。
設有某產品十二年(91年-02年)的季度銷售額數據。見表4.3中的第二列,共有48個數據。如果將這些數據畫在圖上(圖.1),可以看出有明顯的長期趨勢和季節變動。利用分解法,假設這48個數據可表示為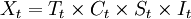 。這裡Xt是這些原始數據,通過分析原始數據X來確定T、C、S(剩下的為I)。
。這裡Xt是這些原始數據,通過分析原始數據X來確定T、C、S(剩下的為I)。

1.移動平均數
把最初的四個數據(表示91年4個季度的值)相加求平均值得到(X1 + X2 + X3 + X4) / 4 = 2741.334。這個數是沒有季節性的,而且隨機性因素也很小甚至沒有。因為隨機性圍繞中間值波動,將四個數相加,正負波動在一定程度上相互抵消了,所以可認為其中已無隨機性。同樣將第二個至第五個數據相加平均, 也不包含季節性,而且其隨機性因素也很小。如此我們可得到45個數據。它們不包含季節性,而且隨機性因素很小甚至沒有。也就是說它們只包括長期趨勢和迴圈變動兩部分(T×C)。這45個數據組成的序列我們稱之為移動平均數序列,用MA來表示,MA=T×C。
2.季節性
由於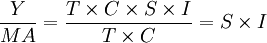 (1)
(1)
因此將觀察值除以移動平均數得到的比率值就只包含季節性和隨機性,從而這些比率包括了確定季節性因素所需要的信息。如果某個比率的值>100,意味著實際值X比移動平均數(T×C)要大。由於X中包含季節性和隨機性,因而當比率值大於100時,就意味著這個季度的季節性和隨機性高於平均數。反之,如果比率小於100,則表示季節性和隨機性低於平均數。
表.2 某產品48個季度的銷售數據及數據分解
季度 觀察值Xt 移動平均值T×C S×I比率% 長期趨勢T 迴圈變動C% 1 3017.60 —— —— 2774.81 —— 2 3043.54 —— —— 2813.77 —— 3 2094.35 2741.334 76.339 2852.73 96.10 4 2809.84 2805.632 100.150 2891.69 97.02 5 3274.80 2835.569 115.490 2930.65 96.76 6 3163.28 2840.558 111.361 2969.61 95.65 7 2114.31 2894.240 73.052 3008.57 96.20 8 3024.57 2907.411 104.030 3047.53 95.40 9 3327.48 2989.961 111.288 3086.49 96.87 10 3493.48 3071.367 113.744 3125.45 98.27 11 3439.93 3187.921 76.537 3164.41 100.74 12 3490.79 3277.322 106.514 3203.37 102.31 13 3685.08 3319.258 111.021 3242.33 102.37 14 3661.23 3303.883 110.816 3281.29 100.69 15 2378.43 3296.073 72.159 3320.25 99.27 16 3459.55 3337.209 103.666 3359.21 99.34 17 3849.63 3347.198 115.010 3398.17 98.50 18 3701.18 3413.185 108.438 3437.13 99.30 19 2642.38 3444.678 76.706 3476.09 99.10 20 3585.52 3501.936 102.387 3515.05 99.63 21 4078.66 3553.405 114.782 3554.01 99.98 22 3907.06 3597.425 108.607 3592.97 100.12 23 2818.46 3723.421 75.695 3631.93 102.52 24 4089.50 3788.657 107.941 3670.89 103.21 25 4339.61 3849.043 112.745 3709.85 103.75 26 4148.60 3874.540 107.101 3748.81 103.35 27 2976.45 3872.325 75.315 3787.77 102.23 28 4084.64 3848.029 106.149 3826.73 100.56 29 4242.42 3810.274 111.342 3865.69 98.57 30 3997.58 3801.414 105.160 3904.65 97.36 31 2881.01 3789.311 76.030 3943.61 96.09 32 4036.23 3818.788 105.694 3982.57 95.89 33 4360.33 3909.526 111.531 4021.53 97.21 34 4360.53 3982.320 109.497 4060.49 98.07 35 3172.18 4029.203 78.730 4099.45 98.29 36 4223.76 4111.740 102.724 4138.41 99.36 37 4690.48 4195.228 111.805 4177.37 100.43 38 4694.48 4237.770 110.777 4216.33 100.51 39 3342.35 4326.237 77.258 4255.29 101.67 40 4577.63 4394.982 104.156 4294.25 102.35 41 4965.46 4477.872 110.889 4333.21 103.34 42 5026.05 4509.818 111.447 4372.17 103.15 43 3470.14 4496.895 77.167 4411.13 101.94 44 4525.94 4570.210 99.031 4450.09 102.70 45 5258.71 4611.094 114.045 4489.05 102.72 46 5489.58 4642.750 111.778 4528.01 102.53 47 3596.76 4481.667 80.255 4566.97 98.13 48 3881.60 —— —— 4605.93 ——
由式(1)可知,如果能將S×I中的隨機性部分去掉,則就得到了季節性指數。要做到這一點,只需註意到隨機性指的是偶然性、沒有一定模式、圍繞中間值0上下波動。因此通過平均就能去掉隨機性的影響。將表4.3中“S×I比率”這一欄列成表4.6的形式,將各年同一季度的數據放在同一列之中,求相同各季度的平均值,得第一至第四季度的平均數分別為112.72,109.88,76.28,103.86。由於從1991年至2002年各年中相同季度的數值加以平均消除了大部分隨機性,因此這四個平均數僅僅代表了季節性。用代數式表示即為
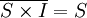 (2)
(2)
其中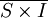 中上面的橫線表示季節平均。
中上面的橫線表示季節平均。
表3 產品銷售額的季節性指數
年份 各季度季節指數 第一季度 第二季度 第三季度 第四季度 1991 — — 76.40 100.15 1992 115.49 111.36 73.05 104.03 1993 111.29 113.74 76.54 106.51 1994 111.02 110.82 72.16 103.67 1995 115.01 108.44 76.71 102.39 1996 114.78 108.61 75.70 107.94 1997 112.75 107.10 75.32 106.15 1998 111.34 105.16 76.03 105.69 1999 111.53 109.50 78.73 102.72 2000 111.81 110.78 77.26 104.16 2001 110.89 111.45 77.17 99.03 2002 111.84 111.78 80.26 — 平均數 112.72 109.88 76.28 103.86 修正平均數 111.95 109.13 75.76 103.16
表3中的四個平均值相加的和為402.74,它不等於400。為了使各季節指數的平均數等於100,必須進行簡單的調整。如果400被合計數402.74來除,結果是0.9932。以0.9932乘以各季節的平均數得到111.95,109.13,75.76,103.16等(見表中最後一行)。現在這四個季節指數的和為400,它們的含義就更加清楚了,例如第二季度的109.13就表示第二季度比全年平均數高出9.13%,第三季度的75.76表示第三季度比全年低24.24%。

3.長期趨勢和迴圈變動
前面介紹的公式MA=T×C表示了一組迴圈變動—長期趨勢數值。在多數情況下這樣已能滿足要求,但有時仍需要把迴圈變動和長期趨勢分離開來。為了做到這一點,我們只需確定一種能最好的描述數據長期趨勢的類型。例如長期趨勢可以是線性的、二次的、S曲線或其它。對於本例,如果將數據在圖上畫出來,可以看出線性的長期趨勢是比較合適的:
Tt = a + bt (.3)
t = 1,2,3…48。用最小二乘法可求得模型的最佳擬合參數為:
a = 2735.85, b = 38.96
因此趨勢直線方程為
T_t=2735.85+38.96t
如圖4所示。用此方程即可求得每個季度的趨勢值。如第20季度(2000年的第四季度)趨勢值為
T_{20}=a+bt=3515.05
由於MA=T×C,因此
MA/T=(T\times C)/T=C (4)
應用上式即可求得迴圈變動值C。如第45季度的迴圈變動值C_{45}等於表3中的移動平均數除以T_{45},即
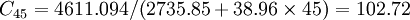
如同季節指數,迴圈指數也採取百分比率。其值大於100的表明該季度經濟活動水平高於所有季度的平均值,而小於100的迴圈指數所表明的情況則剛好相反。
迴圈因數比較複雜,且其變動周期較長,因而在短期預測中可以忽略不計,或將其歸入到趨勢變化之中(稱為趨勢—迴圈因數)。人們更關心的是趨勢和季節的識別。
至此我們完成了對原始數據Xt的分解工作,其步驟總結如下:
1) 用MA=T×C分析長期趨勢和迴圈變動;
2) 用 分析季節性和隨機性;
分析季節性和隨機性;
3) 用分析季節性;
4) 用趨勢外推法中介紹的方法來分析長期趨勢;
5) 用MA / T = C分析迴圈變動。
總之,分解法提供了分析時間序列各種因素的手段,它使用簡單,只需用加法、乘法和除法等簡單代數運算即可,而且分解法非常直觀,能給企業提供一定時期內的大量信息。
用分解法確定了季節指數、趨勢值和迴圈指數之後,就可以根據上面總結的步驟進行預測了。我們對2003年第一季度(第49季度)進行預測。數據的基本關係式為
X=T×C×S×I
由於隨機性無法直接進行預測,進行預測的關係式為:
X=T×C×S
於是,計算出第49季度的T49,C49,S49值即可求得第49季度的預測值。
表3中已得到第一季度的季節指數為111.95,由趨勢方程求得

最後迴圈指數通常要根據判斷估算出來,或者用某種方法預測得到。這裡我們假定通過判斷為:C49 = 98,於是

同樣可以對第50、51季度進行預測。
1. 居中移動平均數
為了求得移動平均數MA,上面我們是將相鄰的4個原始數據相加取平均得到一個數,這樣在表4.5的第三列中就少了三個數據。於是產生了這樣一個問題:最初的四個數據被平均時,它們的平均數應該置於何處?嚴格講應該放在第二季度和第三季度的中間((1+4)/2=2.5,第2.5個季度)。其餘數據取平均時也有類似的問題。但實際數據是表示各個季度而不是半個季度的,這裡我們只好將平均數放在靠後半個季度的地方。假如對平均數再取平均的話就不會產生這樣的問題了,因為如第一季度至第四季度的平均數2741.34是指第2.5季度,而第二季度至第五季度的平均數是指第 3.5季度,則它們的平均數就是指第3個季度((2.5+3.5)/2=3)。稱如此的平均數為居中移動平均數,於是居中移動平均數比原始數據少四個(首尾各兩個)。
現在,實際值除以居中移動平均值所得的比率(還是S×I)也可以用來計算季度指數,具體的與上面所述完全一樣。這樣求得的四個季度的季節指數分別為112.20,109.44,75.37,103.17,其和為400.18,非常接近於400,這是因為移動平均數居中的緣故。
2.分解法的改進
在上面所敘述的分解法基礎上,我們也可作一些改進,如:
1) 修正原始數據中工作日或營業日的差額。由於各個月度(或季度)的工作日是不盡相同的,這就會影響到銷售額或別的所要預測的變數。因此首先必須對數據進行校正。如對月度數據的校正可通過原始數據乘以30對工作日的比率來進行,即將各月度的原始數據折算到工作日均為30天的統一情況。
2) 利用統計方法來淘汰極值(即修改或捨去超出標準差的三倍範圍的數值),在分解法實施之前先對數據進行預處理。
3) 按上一節求得的季節性指數還可進一步改進,併進行動態的調整,因為實際上季節指數並不一定是一成不變的,它本身亦是一個變化的時間序列。
還應註意到用分解法進行預測時,迴圈因素的確定是最為困難的。如有什麼秘訣的話,那就是應具備足夠數量的歷史數據,以使管理人員瞭解迴圈模式是從哪裡開始重覆的,必要時可用圖表方法來幫助確定。由於迴圈模式可能會發生變化,按照管理人員的判斷對迴圈模式作一些調整無疑是必要的。
在前面的兩個子節中,我們是以周期為4的季度數據的一個例題來說明分解法的分解步驟和預測程式。對周期為12月度數據、周期為7的日常數據等其它情況,運用分解法的程式完全類似,在此不再舉例討論。
分解法能幫助解釋歷史數據為什麼變化,能使管理人員分別預計各局部模式的變化。這些局部模式不僅能用以預測,而且也可用於管理之中,再加上它容易被管理人員所理解,因此分解法在直觀上吸引了許多管理人員的註意,從而被大量的用於實際問題的預測。經過成千上萬個時間序列的反覆檢驗,分解法被證明其效率和準確性都是較高的。當然這種證明是經驗的而非理論的,這也是它的主要缺點。它不能用統計的方法來檢驗,也不能建立置信區間。實際上,分解法僅適用於那些季節性較強的中期預測、短期預測,當預測目標受外界干擾較大時,其預測能力會明顯減弱。
案例一:運用時間序列分解法進行銷售預測[1]
時間序列是由一個包括了4個部分的模型組合而成,即T、S、C、R。假定影響時間序列的這四個因素彼此相互作用、非獨立,那麼我們採用相乘的模型[4,P460],即Y,=T×C×S×R。該方法包括以下四個步驟:1.用4季度移動平均法確定季節性指數[4,P463]。其基本原理是用移動平均法來度量趨勢和周期性組合(TC)。這種做法可以消除季節性和隨機變動的影響,即S和R。做法如下:(1)計算時間序列中的4季度移動平均值(TC_1),例:(500+350+250+400)/4=375。
(2)對4季度移動平均值再求其移動平均值的中點值(TC_2)[2],例:(375+362.5/2=368.75)。
計算真實銷售額(3)計算真實銷售額(Y_1)與移動平均值(TC_2)的比率,這個比率實際上表示的季節性和隨機變動綜合作用的部分[2],即SR=Y/TC。
(4)把計算處的比率值按季度排列,例如
第一季度的SR值分別是:1.263、1.367、1.467、1.222、1.348;
第二季度的SR值分別是:1.037、0.762、0.812、0.853、0.879;
第三季度的SR值分別是:0.678、0.640、0.522、0.588、0.700;
第四季度的SR值分別是:1.003、1.067、1.206、1.275、1.116。
然後後按季度分別計算平均比率以便剔除隨機變動(R)的影響,而該平均比率稱為季節性因數(S_1)。例:對於第一季度的計算:(1.263+1.367+1.467+1.222+1.348)/5=1.333 4。依次類推計算第二、三、四季度的s1分別得:1.33 4、0.908 6、0.625 6、1.153 4。(5)對季節性因數(S1)進行調整,調整後的季節性因數(用S2表示)。
例:第一季度的S2計算:1.333 40-0.005 25=1.328 15,其中0.00525=(1.333 4+0.908 6+0.625 6+1.153 4-4)/5。同樣,第二、三、四季度的S2分別是:0.903 35、0.620 35、1.148 15。上述(1)、(2)、(3)、(4)、(5)的計算結果如下表。

2.從原始時間序列中剔除季節性變化影響,即進行非季節性處理[2]。從附圖中觀測銷售額與時期是否有線性變化趨勢。通過觀測發現:1994~1995年銷售額有下降的趨勢,1996-1999年銷售額有上升的趨勢。但是,前兩年下降的趨勢不明顯,後四年一直是上升趨勢。因此,可以近似看作銷售額(Y)與時間(t)有線性關係,並依據非季節性數據作線性回歸方程:Y2 = a + bt其中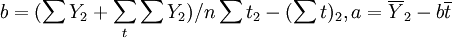 。
。

將表3中的數據代入上述公式得:Y=149.673+20.882t (3)
3.將t=25、26、27、28代人第二步求得的回歸方程(3),並乘上相應的季節性因數S2,則得出2000年每一季度的銷售額預測值。即:Y25 = 892.149、Y26 = 625.665、Y_27=442.612、Y28 = 843.1664,在附圖上作出上述回歸方程(3)的圖形。
採用時間序列分解法時,必須觀察時間t與非季節性數據Y_2的趨勢關係。若t與Y2的趨勢變化是近似於線性的,則可用線性回歸方程預測;若Y2對t來說是呈幾何級數增長,則宜用指數曲線回歸方程;若是其他變化,必須採用相應的其他回歸方程。
採用線性回歸方程來預測,但是由於前兩年的數值是下降的,後四年的數值是上升的,因此,使得該回歸方程的擬合度不是很好。但是,這種影響程度會隨著t的增加而減弱,最終不會影響預測的精確度,因為總趨勢是上升的。,採用時間序列分解法預測時,由於前兩年的數值有下降的趨勢,而擬合的是上升趨勢的線性回歸方程,因此,用該方法預測短期(1-2年)的銷售額不准確,通過附圖可以看出。
- 西安電子科技大學.《決策與預測》第4章 確定型時間序列預測方法.

評論(共4條)
我覺得用MA平滑後剔除的應該是季節因素,而非上文所說的長期趨勢和周期變化。按原文說法剔除後 與之後得到TC序列感覺邏輯上有些矛盾。希望有大神回答一下。
我覺得用MA平滑後剔除的應該是季節因素,而非上文所說的長期趨勢和周期變化。按原文說法剔除後 與之後得到TC序列感覺邏輯上有些矛盾。希望有大神回答一下。
我看了有些書,覺得說法也自相矛盾。這篇文章說的還算是清楚,先算趨勢迴圈,再在原數據中去掉趨勢迴圈計算季節指數,趨勢預測是為了對原數據進行預測。




求s2的時候應該各季度加和除以4而不是5