網頁消重
出自 MBA智库百科(https://wiki.mbalib.com/)
目錄 |
網頁消重是指刪除重覆的網頁,在消重後的網頁集上建立索引再提供服務,可以保證用戶查詢時不會出現大量重覆的內容,同時也減少了存儲空間。
網頁消重的原因[1]
搜索過程中產生重覆的原因主要有兩個,一個是由於URL本身的構造原因產生搜索結果重覆。例如,虛擬主機技術可能會使得多個不同功能變數名稱映射到同一個IP,當搜索系統用這些功能變數名稱進行搜索時,實際上搜索到的是同一個站點,導致搜索結果重覆。這一類由於URL本身導致網頁重覆的問題相對來說比較容易解決,例如,可以通過建立IP與功能變數名稱的對應表、比較網站前幾頁網頁代碼等方式解決。
網頁重覆的另一個重要原因是不同網站之間對相同的內容重覆引用或同一站點在不同物理位置的鏡像等而導致的,這對於一些熱點內容和重要站點尤其如此。對於這類情況,由於大量重覆網頁不是直接對原有網頁進行複製,而是將轉載引用的內容放到自己網頁的某個特定位置再提供給用戶,或者在鏡像時定製了網頁的內容。這樣,新的網頁就可能在風格、佈局、代碼方面與原有網頁有很大的差別,因而不能使用網頁的形式特征來對網頁消重,消重的依據只能是根據網頁的內容特征。
網頁消重的運用[1]
一般而言,基於內容的消重技術的基本思想是:為每一個網頁計算出一組指紋(Fingerprint),所謂指紋信息是指網頁文本的一種信息特征,通常由一組詞或者一組詞加權重構成。從理論上說,不同網頁的指紋是不同的,若兩個網頁指紋相同或相近,則可以認為這兩個文檔的內容重疊性較高,進而考慮進行消重操作。
常用的基於內容的網頁消重有兩個關鍵的方面,一是如何生成網頁的指紋,二是如何通過比較指紋來判斷網頁是否重覆。
生成網頁的指紋有多種演算法,使用比較廣泛的演算法有MD5散列值演算法。MD5的全稱是Message-Digest Algorithm5(信息—摘要演算法),由美國麻省理工學院於20世紀90年代初開發,經MD2、MD3和MD4發展而來。Message-Digest泛指位元組串的Hash變換,就是把一個任意長度的位元組串變換成一定長的大整數。可以用MD5演算法對網頁的文本產生指紋,通過比較不同文本的指紋,可以判斷兩個頁面是否是相同的頁面。MD5演算法及其C語言實現源代碼在RFC 1321(http://www.faqs.org/rfes/rfcl321.html)中有詳細的描述。
第二個要解決的問題是用什麼樣的標準去判定兩個網頁是相同的。以MD5演算法為例,由於MD5演算法是一種嚴格的信息加密和防篡改演算法,只要摘要內容有一個位元組不同,其散列值就會不同,這樣,如果用兩個網頁的全部正文的位元組串作為生成指紋的內容,就很難保證能夠儘量區分出的近似網頁,因為,只要文本位元組串稍有不同,其散列值就會不同。對其他計算指紋的演算法也同樣存在類似的問題。這樣,就需要精心地選擇用什麼樣的文本摘要去生成文本指紋,怎樣用指紋進行比較。這方面,研究人員做了大量的工作。
美國斯坦福大學的Shivakumar等人提出了一種全文分段簽名方法,其基本思想是把一個網頁按一定的原則分成N段(例如每n行作為一段),然後對每一段進行簽名(即計算指紋),於是每篇文檔可以用N個指紋來表示。在進行網頁的比較時,若網頁N個簽名中有M個相同(M是系統定義的閾值),則認為這些網頁是重覆的。為了減少比較過程的空間複雜度和時間複雜度,全文分段簽名方法還使用由文檔標識、段標識和指紋構成的三元組對網頁進行排序,避免了對所有網頁做兩兩比較,使演算法複雜度有所降低。
北大天網提出了另一種方法,即用向量空間來表示網頁的文本內容,用MD5演算法計算前N個特征向量的散列值(指紋),當兩個網頁的這類指紋相同時,就認為兩者互為近似網頁。
網頁消重的演算法[2]
- 1.演算法基礎
當前比較成功的搜索引擎系統大多是基於關鍵詞匹配和結合向量空間模型來完成用戶的檢索請求的。典型的系統包括Google和天網系統。通常這類系統在對已抓取回來的網頁進行分析時,要提取網頁中出現的關鍵詞和摘要信息,並以關鍵詞作為網頁的特征項。
天網系統在搜集並分析一篇網頁時,提取並記錄了網頁中出現的關鍵詞,同時根據公式賦予每個關鍵詞一個權值,這些關鍵詞的權值構成一個向量空間,可以用來表示該網頁。另外,我們還從網頁中提取了512個位元組的有效文字(指用戶實際訪問該網頁時能看到的文字,在html和其他格式的網頁中,有一些用戶看不到的文字,它們告訴瀏覽器該執行什麼樣的操作及如何顯示網頁,包括字體、顏色、排版等信息)作摘要。當用戶查詢時,摘要同網頁的標題、URL等信息一起顯示給用戶,供用戶瞭解網頁的內容,選擇感興趣的進行瀏覽。
- 2.演算法描述
考慮到基於關鍵詞匹配的搜索引擎系統的特點,結合使用網頁的向量空間模型,我們提出了5種網頁消重演算法,用於快速、有效地發現Web上的轉載網頁。下麵逐一介紹這幾種演算法。在以下的描述中,用Pi表示第i個網頁,其權值最高的前N個關鍵詞構成的特征項集合為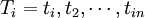 ,其對應的特征向量為
,其對應的特征向量為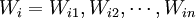 ,其摘要用Abstract(Pi)表示,前N個關鍵詞拼接成的宇符串用Concatenate(Ti)表示,而先對前N個關鍵詞按字母序排序後再拼接成的字元串用Concatenate(sort(Ti)表示。另外,用MD5(X)來表示字元串X的MD5散列值,用Mirror(Pi,Pj)表示Pi和Pj互為轉載網頁,用
,其摘要用Abstract(Pi)表示,前N個關鍵詞拼接成的宇符串用Concatenate(Ti)表示,而先對前N個關鍵詞按字母序排序後再拼接成的字元串用Concatenate(sort(Ti)表示。另外,用MD5(X)來表示字元串X的MD5散列值,用Mirror(Pi,Pj)表示Pi和Pj互為轉載網頁,用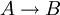 表示“若A成立則B成立”。
表示“若A成立則B成立”。
- 演算法1
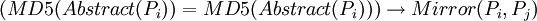
- 演算法2
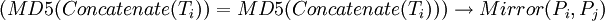
- 演算法3
| (MD5(Concatenate(Ti)) = MD5(Concatenate(Ti))) | 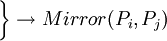
|
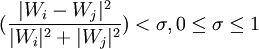
|
- 演算法4
| (MD5(Concatenate(sort(Ti))) = MD5(Concatenate(sort(Ti)))) |
|
|
|
- 演算法5
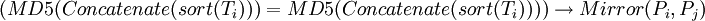
- 3.演算法分析
可以看出,我們設計的第1種演算法採用了對網頁摘要求MD5散列值的方法,當兩個網頁的散列值(占16個位元組)相同時,就認為二者是互為轉載的。由於MD5演算法的嚴格性保證了當兩個網頁的摘要內容有一個位元組不同時,其散列值就不同,這樣就使得本來應作為轉載處理的卻沒有被確定為轉載網頁。為此,我們又基於向量空間模型理論,提出了第2種和第5種演算法。第5種演算法表明,當兩個網頁的權值最高的前N個關鍵詞集合相同時就認為二者是互為轉載的網頁。第2種演算法比第5種要嚴格一些,它不僅要求兩個轉載網頁的前N個關鍵詞相同,其順序也是一致的(按權值排序),因而第2種演算法有可能會漏掉一些轉載網頁。
演算法2和演算法5都只是要求轉載網頁的前N個特征項相同,沒有考慮到這些特征項所構成向量的夾角大小。演算法3和演算法4則分別在演算法2和演算法5的基礎上分別考慮了兩個網頁特征向量的相似度。但向量相似度的計算並沒有使用夾角餘弦值來定義,因為它只度量了兩個向量的夾角大小,而沒有考慮向量的長度。我們認為只有當兩個向量的夾角小,同時其長度相差也小時,二者才是相似的。針對這一點,我們又設計了判斷兩個向量相似度的方法,即演算法3和演算法4的第二個條件
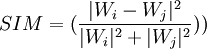
可以看出,SIM能夠同時兼顧向量的夾角和長度兩個因素。當兩個網頁內容毫不相關時(即它們的關鍵詞集合沒有交集),Wi與Wj垂直,SIM的值為l。當兩個網頁相同時,SIM為0。當兩個網頁相似而不相同時,SIM的值介於0和1之間,於是SIM的值成為判斷兩個網頁相似度的標準。另外,類似於演算法5是對演算法2的條件放鬆,演算法4也是對演算法3的放鬆。
後四種演算法都對向量空間模型理論作了較大的簡化。首先,我們只從網頁中出現的所有關鍵片語成的M個特征向量提取了前N個(N<M),這把理論模型的限制放鬆了。之所以可以這樣做是因為:
1)特征向量的前N個分量絕對值大,基本能確定特征向量的方向。取較少的關鍵詞能減少演算法的複雜度。儘管有可能降低其準確度,降低多少,後面的實驗將對其作出評測。
2)轉載網頁的製作人,對網頁稍加改動變成相似網頁時,不能改變其基本意思。而網頁的基本意思一般通過其中出現的高頻詞來反映。後面的(M—N)個詞出現的次數為l或2,相對而言,這些詞的出現是不穩定的,當使用這些詞來判斷相似網頁時,反而會漏掉一大批相似網頁。
其次,後4種演算法都要求前N個關鍵片語成的集合要相同。這卻把理論模型的限制加強了。這主要是由於對演算法複雜度的考慮,判斷兩集合交集大小需要先求出它們的交集。求交集運算的複雜度較大,而把一百萬網頁兩兩求交集,其10lz量級的運算量是我們不敢提及的。我們只能考慮用MD5演算法對集合簽名,實際上就是對關鍵詞序列簽名,來表示集合的相同與不同。簽名演算法有極高的敏感性,作用對象稍有不同就會給結果帶來很大的差異,並且不可能從簽名差異的大小來判斷原簽名對象差異的大小。作這樣的簡化後,有可能出現這樣的情況,位置在N附近的詞在排序上出現的微小變動,如第N個詞與第N+1個詞位置互換了,本來是兩篇相似度很高的文章,可能會被我們的演算法漏掉。這對演算法的影響到底有多大,我們仍需通過實驗來評測。







{kind=link}