STAR模型
出自 MBA智库百科(https://wiki.mbalib.com/)
目录 |
STAR模型全称为平滑转移自回归模型(smooth transition autoregression),是非线性时间序列模型中的参数模型,各个参数有很强的经济背景,始于2003年诺贝尔经济学奖得主Granger和瑞典著名统计学家 于1993 年的研究论文, 此后大量的理论和应用研究发现这一模型确实很好的模拟了商业周期、汇率以及失业率等经济、金融时间序列对均衡的偏离和回复现象。
于1993 年的研究论文, 此后大量的理论和应用研究发现这一模型确实很好的模拟了商业周期、汇率以及失业率等经济、金融时间序列对均衡的偏离和回复现象。
STAR模型的内涵[1]
STAR模型的经济学含义是经济集合体中所有变化主要由不同行为个体变化引起,并非所有个体同时对某个经济信号做出反映而相互影响。因此不同于离散转移模型,平滑转移回归模型的转移是基于转移变量的连续过程(Hansen,1999)。当不确定区制转变的时间且新区制还未产生的时候,平滑转移回归模型有效的体现了区制转移行为,所以该模型能够捕捉在转移阶段变量的动态特征。同时具备非线性和区制转移的特征使得该模型成为研究经济变量的重要工具。
选择STAR模型对中国实际汇率非线性态势进行实证预测研究的原因是:平滑转移自回归模型不用像马尔可夫机制转换模型那样需要提出预先假设、捕捉不到状态的变化;同时门限模型的错误设定问题也在一定程度上得到缓解;而ARCH类模型只能解决残差的非线性问题;只有STAR模型可以追踪在两个极端机制之间的平滑改变或渐进变化,最易模拟汇率动态变化的非线性路径。
STAR模型的形式及线性检验[2]
设STAR模型形式为
公式一: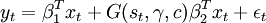
其中β1,β2表示参数向量,
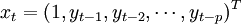
εt˜i.i.d.N(0,σ2)
G(st,γ,c)为转移函数,st为转移变量。常用的转移函数形式包括Logistis形式(LSTAR)和指数形式(ESTAR)。
Logistis形式的转移函数为
公式二: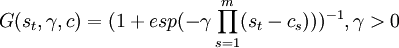
参数γ决定了机制转换的平滑程度,γ越大机制转换越陡峭。当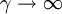 时,模型的指数部分衰减得非常快,模型的转换几乎是瞬间完成的。
时,模型的指数部分衰减得非常快,模型的转换几乎是瞬间完成的。
指数形式的转移函数为
公式三:G(st,γ,c) = 1 − esp( − γ(st − c)2),γ > 0
显然,ESTAR的转移函数关于st = c对称;若转换速度参数 或
或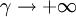 ,G(st,γ,c)都将退化为常数(O或1)。
,G(st,γ,c)都将退化为常数(O或1)。
STAR模型线性检验的基本思想是令H0:γ = 0,进而G(·)=1/2,此时模型将退化为线性模型。但这样会使参数向量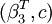 成为无法识别的冗余参数。针对这一问题,Luukkonen等提出将转移函数按照泰勒级数展开,并在此基础上构造LM类型的统计量(以下简称LST统计量).对于LSTAR模型,将转移函数按照3阶泰勒级数展开得到:
成为无法识别的冗余参数。针对这一问题,Luukkonen等提出将转移函数按照泰勒级数展开,并在此基础上构造LM类型的统计量(以下简称LST统计量).对于LSTAR模型,将转移函数按照3阶泰勒级数展开得到:
公式四: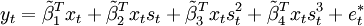
其中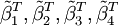 表示估计后的参数向量。
表示估计后的参数向量。
原假设转化为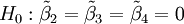 ,使用的LM统计量为
,使用的LM统计量为
公式五: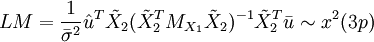
其中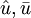 表示残差误差的估计向量
表示残差误差的估计向量
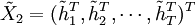

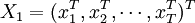
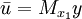
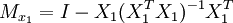
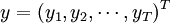
在实际应用时,STAR模型线性检验的步骤为
1)在线性原假设下估计模型,计算其残差平方和SSR0;2)估计辅助回归式,即公式四,计算其残差平方和SSR1;3)根据公式六或公式七计算统计量的值;
公式六: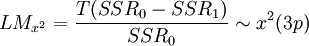
公式七: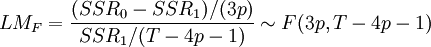
Gonzalez等指出在一般情况下,该统计量具有较好的检验水平和功效,但如果样本容量较小,则会出现严重的检验水平扭曲,并且如果样本容量小于4p,该检验失效。
STAR模型的结构构成[3]
STAR模型的结构是围绕以下三个关系组织的:
(1)资本积累影响利润的关系:在一定的实际资本积累与增长水平下,以当前价格表示的需求可按收入项目予以计算(同其他模型相反,这里没有关于工资率的方程,而且工资单一利润分红是直接决定的)。
(2)利润影响资本积累的关系:厂商按现行价格的投资依自筹资金(如在FIFI和DECA模型中那样)以及外部投资可能性两者而定(这些又转而依靠家庭储蓄而定)。
(3)增长影响利润的关系:利润水平依实际产出和资本存量,以及以往年份继承下来的金融结构而定。
前两组关系完全决定了现行价格(按价值量)和特别是名义生产水平以及有效利润三者之间的平衡,但是它们必须与增长率相一致。因此,价格水平的决定必须使生产在价值量与实物量间达到一致。这里没有明确的价格方程(如在ZOGOL或DECA模型中那样),只有一种“隐含的”使要求的与实现的利润率相均衡的确定方法(Mazier,1975)。
STAT模型的结构看上去十分原始;如果根据凯恩斯主义的价值观来看,它引入了实际生产中影响供给的因素(如FIFI模型所做的)。实物一价值分配决定是模型的核心部分,并能够理解现实流行的停滞膨胀。不过,它来自对历史的模拟,即通货膨胀的决定是有倾向性的(Boyer等,1973),而且对确定价格水平用的利润增长关系的有效性表示怀疑。厂商获得的利益在模型的动态特性中也起着重要作用[它同R.M·古德温(Goodwin)理论模型具有某些相似之处](R.M.Goodwin,1951)。






