线性辨别模型
出自 MBA智库百科(https://wiki.mbalib.com/)
线性判别式模型(Linear Discriminant Model)
目录 |
线性判别式模型的概述[1]
线性判别式模型是由阿特曼(A1tman)发展起来的一种风险测定模型。它通过使用借款者的各种财务比率和这些比率的权重来对违约风险进行总体的计算,其中各种财务比率的权重是基于违约和非违约借款者过去的情况得到的经验数据。
线性判别式模型采取的函数形式为:
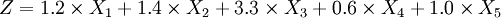
式中,X1表示营运资本与总资本的比率;X2表示保留盈余与总资本的比率;X3表示税前收入与总资产的比率;X4表示股票的市场价值与长期债务账面价值的比率;X5表示销售额与总资产的比率。
Z的值越高,借款者违约风险越低。这样,低的或负的Z值表明借款者属于相对较高的违约风险类别。
假定潜在的借款者的财务比率取下面的数值:X1=0.2,X2=O,X3=-0.2,X4=0.1,X5=2.0。
其中X2为0,X3为负值表明公司最近出现了负收入或亏损。X4表明借款者具有较高的财务杠杆水平。营运资产比率X1和销售资产比率X5表明公司具有较好的流动性,并且保持了它的销售数量。Z值提供了借款者信用风险的总体分数或指标。
Z=1.2×0.2十1.4×0十3.3×(一O.2)十0.6×0.1十1.0×2.0=1.64
根据线性评分模型,任何2值低于1.64的公司都应被看做高风险范围。这样,金融机构在该借款者改善其收益状况之前不应对其发放贷款。
一是它将借款者简单地划分为违约和不违约两类,但是在现实中有多种违约情况,从不支付利息或延迟支付利息到完全不支付所有承诺支付的利息和本金,这种模型难以难确地反映各种情况;
二是公式中的权重是固定不变的,随着实物和金融市场的不断变化,各种财务比率对违约的影响也是在不断变化的,因而这种权重的设定并不淮确;
三是这种模型忽略了重要的难以定量的因素,这些因素在违约和不违约的决策中起到关键性的作用。
例如,借款者的声誉和借款方长期隐含的合约关系都是至关重要的特征。一些宏观因素如经济周期也同样重要。这些因素在线性评分模型中通常被忽略掉了。此外,金融机构也难以充分全面地掌握借款者过去的违约情况,这就增加了回归的难度和不淮确性。
- ↑ 龚明华编著. 现代商业银行业务与经营. 中国人民大学出版社, 2006.03.






