相对熵
出自 MBA智库百科(https://wiki.mbalib.com/)
相对熵(Relative Entropy; KL散度; Kullback–Leibler divergence; KLD; 信息散度; 信息增益)
目录 |
相对熵是指两个概率分布P和Q差别的非对称性的度量。 相对熵是用来 度量使用基于Q的编码来编码来自P的样本平均所需的额外的比特个数。典型情况下,P表示数据的真实分布,Q表示数据的理论分布,模型分布,或P的近似分布。
对于离散随机变量,其概率分布P 和 Q的相对熵可按下式定义为
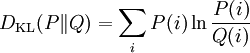 。即按概率P求得的P和Q的对数差的平均值。相对熵仅当概率P和Q各自总和均为1,且对于任何i皆满足Q(i) > 0及P(i) > 0时,才有定义。式中出现0ln0的情况,其值按0处理。
。即按概率P求得的P和Q的对数差的平均值。相对熵仅当概率P和Q各自总和均为1,且对于任何i皆满足Q(i) > 0及P(i) > 0时,才有定义。式中出现0ln0的情况,其值按0处理。
对于连续随机变量,其概率分布P和Q可按积分方式定义为 [1]
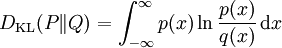 ,其中p和q分别表示分布P和Q的密度。
更一般的,若P和Q为集合X的概率测度,且Q关于P绝对连续|绝对连续,则从P到Q的相对熵定义为
,其中p和q分别表示分布P和Q的密度。
更一般的,若P和Q为集合X的概率测度,且Q关于P绝对连续|绝对连续,则从P到Q的相对熵定义为
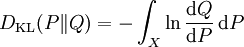 ,
其中,假定右侧的表达形式存在,则
,
其中,假定右侧的表达形式存在,则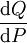 为Q关于P的拉东-尼科迪姆定理|R–N导数。
为Q关于P的拉东-尼科迪姆定理|R–N导数。
相应的,若P关于Q绝对连续|绝对连续,则
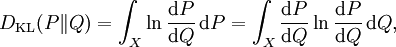
即为P关于Q的相对熵。
相对熵的值为非负数:
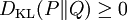 ,
,
由吉布斯不等式可知,当且仅当P = Q时DKL(P||Q)为零。
尽管从直觉上相对熵是个度量|度量或距离函数, 但是它实际上并不是一个真正的度量或距离。因为相对熵不具有对称性:从分布P到Q的距离(或度量)通常并不等于从Q到P的距离(或度量)。
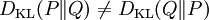
自信息和相对熵
I(m) = DKL(δim | pi),
互信息和相对熵
- I(X;Y) = DKL(P(X,Y) | | P(X)P(Y)) = EXDKL(P(Y | X) | | P(Y)) = EYDKL(P(X | Y) | | P(X))
信息熵和相对熵
- H(X) = ExI(x) = logN − DKL(P(X) | | PU(X))
条件熵和相对熵
- H(X | Y) = logN − DKL(P(X,Y) | | PU(X)P(Y)) = (i)logN − DKL(P(X,Y) | | P(X)(Y)) − DKL(P(X) | | PU(X)) = H(X) − I(X;Y) = iilogN − EYDKLP(X | Y) | | PU(X)
交叉熵和相对熵
H(p,q) = Ep[ − logq] = H(p) + DKL(p | q)。
- ↑ C. Bishop (2006). Pattern Recognition and Machine Learning. p. 55.






