网页净化
出自 MBA智库百科(https://wiki.mbalib.com/)
- 网页净化(Noise Reduction)
目录 |
网页净化是根据网页结构,识别网页中不同类型的内容块,舍弃噪声信息,如导航信息、广告信息、版权信息等,剥离出正文信息。它是主题相关度计算、资源查重、自动摘要、自动分类及元数据抽取的前提,是预处理阶段不可缺少的环节。
网页净化的目的[1]
网页净化的目的是获取HTML页面中的正文信息,同时,网页净化可以显著简化网页内标签结构的复杂性,并减小网页的大小,从而节省后续处理过程的时间和空间开销。下图给出了网页内容分区的一个示例。

HTML是一种标记语言,它的标签在功能上可以分为两类:一类是用于规划网页布局的标签,如<table>、<tr>、<td>、<div>、<P>等,它们将网页内容分成若干个部分,并确定每个部分在网页中的显示位置,从而形成视觉上可以区分的正文信息块、导航信息块、广告信息块及版权信息块等内容,这些标记是识别网页信息块的基础;另一类标签是描述网页数据项显示属性的标签,如 <a>、<img>、<font>、<b>、<H3>等,其中,<a>表示数据项是超链接,<img>表示数据项是图形,其他标签定义了数据项显示的字体属性,通过对这类标签的分析,可以确定内容块中数据的属性信息。一般情况下,正文信息以纯文本为主,导航信息包含大量超链接,广告信息通常包括图形信息,且其位置一般不在页面的中心,而版权内容则包括一些特殊的信息内容,如“版权”、“权利”、“all rights reserved”、“copy right”等,这样,可根据HTML的上述标签及特殊信息进行网页净化。
几种网页净化方法[2]
先将HTML中的标签按照功能分类,然后提取出适合网页净化的标签树。将HTML标签分为两类:
1)规划网页布局的标签。网页是由若干内容块组成,而内容块是由特定的标签(容器标签)规划出。常用的容器标签有<table>、<tr>、<td>、<P>、<div>等。
2)属性标签。网页中除了描述布局结构的标签外,HTML中还定义了一套标签来描述网页中的内容。比如:<b>标签说明它所包含的内容用粗体来显示。依据容器标签构造标签树中的节点,其他类型的标签信息作为它所在的内容块的属性。
标签树构造完成后,网页净化过程就变为对标签树中节点的剪裁。依据内容块中词频数与图片数和超链接数的比值可以为每个内容块设定一个类型,分为主题型、多链接型、图片型三种。如果内容块中词项数与图片数的比值小于某个阈值,该内容块是图片型;如果内容块中词项数与图片数的比值小于某个阈值,该内容块就是图片型;如果内容块中作为链接导航文字出现的词项数与该块中总词项数的比值小于某个阈值,该内容块就是多链接型,否则为主题类型。
Web上的网页根据内容可以分为三类:有主题网页、目录网页和图片网页。三种网页的净化方法各不相同。在目录型网页中,大多数的内容块都是多链接型的。在网页的布局上,重要的信息通常分布在网页中间区域,而网页边缘信息的重要性相对较弱。因此,对于目录型网页,我们可以将网页中间区域的内容块作为网页的主题内容,而边缘的内容块则通过与主题内容计算相似性的方法来决定取舍。对于图片网页,由于网页中文字较少,因而传统的向量表示不够准确,在这种情况下,保留网页中间区域的图片型内容块就可以完成网页净化的功能。有主题网页的净化过程如下:首先,识别出网页中的主题内容块,然后,依据主题内容在剩余内容块中识别出与主题相关的内容块,最后剩下的内容块就是噪声内容块。主题内容块的识别是依据如下启发式规则:一篇有主题网页中的正文通常是用成段的文字来描述,中间通常不会加入大量的超链接,而非正文信息通常是伴随着超链接出现的。因此,在有主题网页中,如果一个内容块是主题类型的,则该内容块中的内容为网页主题内容的一部分。依据该规则,深度优先遍历DOM树并依次记录主题类型的内容块,就得到该网页的主题内容。得到主题内容后,剩余内容块的主题相关性是通过与主题内容的相似性来判断的。相似性计算公式大多采用向量计算公式。因此首要的工作是内容块的特征向量表示,即表示为:
( )
)
计算公式如下

其中,BN为网页中内容块的总数;n为网页中不同关键词的总数;BWeightj为网页中内容块j的权重,它的值由一个内容块中的重要标签来决定;BTfj为关键词i出现在内容块j中的词频。与主题内容相关性较小的即为噪声。
在判断ST树中噪音元素节点时基于以下两点假设:①如果ST树中某个元素节点下的类型节点越多则该节点越重要,类型节点越少则该节点越不重要;②元素节点包含的内容越多样,该节点越重要。通过这两点来衡量元素节点的重要性。对于一个网站的ST树即SST树来说,内部节点和叶节点采用不同的处理方式。
对于SST中内部节点E,它的重要程度用CompImp(E)表示,计算方式如下
![Comp Im p(E)=(1- r^1)Node Im p(E)+r^1\sum_{i=1}^1[P_iComp Im p(S_i)]](/w/images/math/a/8/7/a871ab94d38162e6d6a8b2bcf492572b.png)
其中:
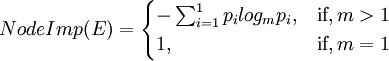
式中,l代表元素节点E的子类型节点的个数;Pi是网页使用E节点的第i个子类型的概率,即出现第i个子类型的网页个数与总网页个数的比值;Si是E的子类型节点;r是一个大于零的可调参数;另外:
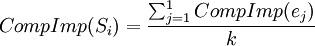
CompImp(Si)表示类型节点Si的重要程度,ei表示Si中的元素节点,K表示Si中元素节点的个数。对于SST树中的叶节点E,重要程度计算公式如下,
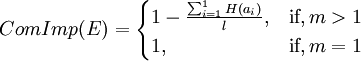
其中ai表示节点E中的特征项,如词语,图像文件,链接等;1是节点E中特征项的个数;m是含有E节点的网页个数;H(ai)是E节点的信息熵。H(ai)计算公式如下:
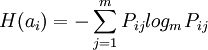
其中Pij表示含有节点E的网页中出现ai的概率。
噪声的判断:如果SST中元素节点E的所有后继节点的重要程度以及自身的重要程度小于某个阈值则认为E是噪声。实验表明这种网页净化方法能有效地提高网页分类系统的性能。
基于标签树的净化方法在依据规划网页布局的标签(<table>、<tr>、<td>、<P>、<div>等)和属性标签构建完标签树后,依据内容块中词频数与图片数和超链接数的比值将内容块分为主题型、多链接型、图片型三种。将Web上的网页根据内容分为有主题网页、目录网页和图片网页。对于目录型网页,将网页中间区域的内容块作为网页的主题内容,而边缘的内容块则通过与主题内容计算相似性的方法来决定取舍。对于图片网页,由于网页中文字较少,因而传统的向量表示不够准确,在这种情况下,保留网页中间区域的图片型内容块就可以完成网页净化的功能。有主题网页的净化过程如下:首先,识别出网页中的主题内容块,然后,依据主题内容在剩余内容块中识别出与主题相关的内容块,最后剩下的内容块就是噪音内容块。主题内容块的识别是依据如下启发式规则:一篇有主题网页中的正文通常是用成段的文字来描述,中间通常不会加入大量的超链,而非正文信息通常是伴随着超链出现的。
基于标签树的净化方法的缺点:对于目录型网页和图片型网页,净化方法比较粗糙。对于目录型网页是将中间内容作为主题内容,但中间区域的划分不是很明确;对于图片型网页,只是保留中间部分。另外网页块的划分方法有待改进。有些网页常常将同一个新闻或内容用多个<P>或<div>分割开来,根据标签树的构建方法同一个新闻或内容会划分到不同的内容块中,不能将同一个新闻或内容划分到同一个内容块中。
ST树中判断噪音元素节点时基于以下两点假设:①如果ST树中某个元素节点下的类型节点越多则该节点越重要,类型节点越少则该节点越不重要;②元素节点所包含的基于ST树的净化方法的缺点:这方法的缺点主要产生于SST树的构建,在构建某
个网站的SST树时,必须保证该网站是按照同一种风格来构建的。如果一个网站中大多数网页使用不同的风格,则这些网页的DOM树也可能完全不一样,可能没有相同的类型节点,这样就不容易构建良好的SST树,进而会影响到基于ST树的净化算法。






