编译码器
出自 MBA智库百科(https://wiki.mbalib.com/)
编译码器(COder-DECoder,CODEC)
目录 |
什么是编译码器[1]
编译码器是一种新颖CMOS数字集成电路,它采用编码方式将控制信号输出,再以译码方式接收,是实现数字遥控的关键部件。可广泛用于报警系统,无绳电话及寻呼系统,楼寓对讲系统、数据采集系统等领域。
编译码器的组成[2]
CCITTG.722编码方案的编、译码器组成如图1和图2所示。
 | 
|
1.编码器
1)发送正交镜像滤波器QMF
发送QMF的作用是将音频全频带50~7000Hz划分为低频区(50~4000Hz)和高频区(4000~7000Hz)两个子带,它是一个带通数字滤波器。发送QMF的输入信号是由发送端音频部分送来的输出信号,取样频率为16kHz。另一方面,低频区子带和高频区子带的ADPCM的输入信号DL、DH则分别是取样频率为8kHz的来自发送QMF的输出信号。发送及接收音频部分的组成如图3所示,发送及接收部分的QMF组成如图4所示。


2)低频区子带的ADPCM编码器
低频区子带的ADPCM编码器的输入是低频输入信号XL与预测信号SL相减的差值信号EL,差值信号EL的量化采用60量级的非线性自适应量化器,各量化样点用6bit的编码表示。该量化器的输出信号IL作为低频区自带编码器的输出,以48kb/s的速率传送到译码器。
量化器的输出信号IL在自适应预测器经反馈后,LSB的2bit被消减,变为4bit的IL信号,该信号使用的量化器是按量化规格因子△进行自适应量化的,具有15个量化级的自适应逆量化器。经此量化器后得到量化差值信号RLt,此信号RLt与预测信号SL叠加生成重建信号RLt。
在低频子带ADPCM编码器及译码器中,使用4bit而不是6bit的编码,并且因为有效地防止了两个LSB所插入的数据信号流入自适应预测器的反馈环,从而避免了编码器和译码器因速率模式的误匹配而导致性能下降的问题。
3)高频区子带的ADPCM编码器
高频区子带的ADPCM编码器的输入信号是高频输入信号XH与预测信号5H相减的差值信号SH。差值信号EH的量化采用4个量化级的非线性自适应量化器,各量化样点用2bit的编码表示。该量化器的输出信号IH作为高频子带编码器的输出,以16kb/s的速率传送至译码器。
自适应逆量化器利用2bit的传输编码恢复出差值信号DH。该量化差值信号DH与预测信号SH叠加,得到重建信号RH。
2.译码器
1)低频区子带的ADPCM译码器
低频区子带的ADPCM译码器依据速率模式选择的指示信号,可以进行三种速率模式中任何一种模式的工作。量化差值信号按照速率模式的指示信号,选择DL6、DL5和DL4信号中的一个,再与预测信号SL叠加,产生重建信号RL计算预测信号SL的电路以及包括各逆量化的自适应信号通路,与前述的低频子带ADPCM编码器的反馈电路原理相同。
2)高频区子带的ADPCM译码器
高频区子带的ADPCM译码器,与前述的高频区子带的ADPCM编码器中的反馈电路原理相同。RH为其输出的重建信号。
3)接收正交镜像滤波器QMF
接收QMF利用高频子带和低频带ADPCM译码器输出的重建信号RH、RL进行插值,生成16kHz的数字滤波器的输出Xout,此信号将作为接收音频部分的输入信号。
根据发送和接收QMF的组合,在QMF内部所进行的信号处理和插值,会抵消处理过程中引入的部分误差。因此若不考虑ADPCM的编码译码过程,可以认为QMF部分只是一个对于输入音频信号具有延迟特性的部件。
三种话音编译码器[3]

1. 波形编译码器
波形编译码的想法是,不利用生成话音信号的任何知识而企图产生一种重构信号,它的波形与原始话音波形尽可能地一致。一般来说,这种编译码器的复杂程度比较低,数据速率在16 kb/s以上,质量相当高。低于这个数据速率时,音质急剧下降。
最简单的波形编码是脉冲编码调制(pulse code modulation,PCM),它仅仅是对输入信号进行采样和量化。典型的窄带话音带宽限制在4kHz,采样频率是8kHz。如果要获得高一点的音质,样本精度要用12位,它的数据率就等于96kb/s,这个数据率可以使用非线性量化来降低。例如,可以使用近似于对数的对数量化器(logarithmic quantizer),使用它产生的样本精度为8位,它的数据率为64 kb/s时,重构的话音信号几乎与原始的话音信号没有什么差别。这种量化器在20世纪80年代就已经标准化,而且直到今天还在广泛使用。在北美的压扩(companding)标准是μ律(μ-law),在欧洲的压扩标准是A律(A-law)。它们的优点是编译码器简单,延迟时间短,音质高。但不足之处是数据速率比较高,对传输通道的错误比较敏感。
在话音编码中,一种普遍使用的技术叫做预测技术,这种技术是企图从过去的样本来预测下一个样本的值。这样做的根据是认为在话音样本之间存在相关性。如果样本的预测值与样本的实际值比较接近,它们之间的差值幅度的变化就比原始话音样本幅度值的变化小,因此量化这种差值信号时就可以用比较少的位数来表示差值。这就是差分脉冲编码调制(differential pulse code modulation,DPCM)的基础—对预测的样本值与原始的样本值之差进行编码。
这种编译码器对幅度急剧变化的输入信号会产生比较大的噪声,改进的方法之一就是使用自适应的预测器和量化器,这就产生了一种叫做自适应差分脉冲编码调制(adaptive differential PCM,ADPCM)。在20世纪80年代,国际电话与电报顾问委员会 (International Telephone and Telegraph Consultative Committee,CCITT),现改为国际电信联盟-远程通信标准部(International Telecommunications Union-Telecommunications Standards Section,ITU-TSS ),就制定了数据率为32kb/s的ADPCM标准,它的音质非常接近64 kb/s的PCM编译码器,随后又制定了数据率为16,24和40kb/s的ADPCM标准。
上述的所有波形编译码器完全是在时间域里开发的,在时域里的编译码方法称为时域法(time domain approach)。在开发波形编译码器中,人们还使用了另一种方法,叫做频域法(frequency domain approach)。例如,在子带编码(sub-band coding,SBC)中,输入的话音信号被分成好几个频带(即子带),变换到每个子带中的话音信号都进行独立编码,例如使用ADPCM编码器编码,在接收端,每个子带中的信号单独解码之后重新组合,然后产生重构话音信号。它的优点是每个子带中的噪声信号仅仅与该子带使用的编码方法有关系。对听觉感知比较重要的子带信号,编码器可分配比较多的位数来表示它们,于是在这些频率范围里噪声就比较低。对于其他的子带,由于对听觉感知的重要性比较低,允许比较高的噪声,于是编码器就可以分配比较少的位数来表示这些信号。自适应位分配的方案也可以考虑用来进一步提高音质。子带编码需要用滤波器把信号分成若干个子带,这比使用简单的ADPCM编译码器复杂,而且还增加了更多的编码时延。即使如此,与大多数混合编译码器相比,子带编译码的复杂性和时延相对来说还是比较低的。
另一种频域波形编码技术叫做自适应变换编码(adaptive transform coding,ATC)。这种方法使用快速变换(例如离散余弦变换)把话音信号分成许许多多的频带,用来表示每个变换系数的位数取决于话音谱的性质,获得的数据率可低到16 kb/s。
2.音源编译码器
音源编译码的想法是企图从话音波形信号中提取生成话音的参数,使用这些参数通过话音生成模型重构出话音。针对话音的音源编译码器叫做声码器(vocoder)。在话音生成模型中,声道被等效成一个随时间变化的滤波器,叫做时变滤波器(time-varying filter),它由白噪声——无声话音段激励,或者由脉冲串——有声话音段激励。因此需要传送给解码器的信息就是滤波器的规格、发声或者不发声的标志和有声话音的音节周期,并且每隔10—20ms更新一次。声码器的模型参数既可使用时域的方法也可以使用频域的方法确定,这项任务由编码器完成。
这种声码器的数据率在2,4kb/s左右,产生的语音虽然可以听懂,但其质量远远低于自然话音。增加数据率对提高合成话音的质量无济于事,这是因为受到话音生成模型的限制。尽管它的音质比较低,但它的保密性能好,因此这种编译码器一直用在军事上。
3.混合编译码
混合编译码的想法是企图填补波形编译码和音源编译码之间的间隔。波形编译码器虽然可提供高话音的质量,但数据率低于16kb/s的情况下,在技术上还没有解决音质的问题;声码器的数据率虽然可降到2.4kb/s甚至更低,但它的音质根本不能与自然话音相提并论。为了得到音质高而数据率又低的编译码器,历史上出现过很多形式的混合编译码器,但最成功并且普遍使用的编译码器是时域合成—分析(analysis—by—synthesis,AbS)编译码器。这种编译码器使用的声道线性预测滤波器模型与线性预测编码(1inear predictive coding,LPC)使用的模型相同,不使用两个状态(有声/无声)的模型来寻找滤波器的输入激励信号,而是企图寻找这样一种激励信号,使用这种信号激励产生的波形尽可能接近于原始话音的波形。AbS编译码器由Atal和Remde在1982年首次提出,并命名为多脉冲激励(multi—pulse excited,MPE)编译码器。在此基础上随后出现的是等间隔脉冲激励(regular—pulse excited,RPE)编译码器、码激励线性预测(code excited linear predictive,CELP)编译码器和混合激励线性预测(mixed excitation linear prediction,MELP)等编译码器。
AbS编译码器的一般结构如图6所示。
AbS编译码器把输入话音信号分成许多帧(frames),一般来说,每帧的长度为20ms。合成滤波器的参数按帧计算,然后确定滤波器的激励参数。从图6(a)可以看到,AbS编码器是一个负反馈系统,通过调节激励信号u(n)可使话音输入信号s(n)与重构的话音信号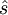 (n)之差为最小,也就是重构的话音与实际的话音最接近。这就是说,编码器通过“合成”许多不同的近似值来“分析”输入话音信号,这也是“合成-分析编码器”名称的来由。在表示每帧的合成滤波器的参数和激励信号确定之后,编码器就把它们存储起来或者传送到译码器。在译码器端,激励信号馈送给合成滤波器,合成滤波器产生重构的话音信号,如图6(b)所示。
(n)之差为最小,也就是重构的话音与实际的话音最接近。这就是说,编码器通过“合成”许多不同的近似值来“分析”输入话音信号,这也是“合成-分析编码器”名称的来由。在表示每帧的合成滤波器的参数和激励信号确定之后,编码器就把它们存储起来或者传送到译码器。在译码器端,激励信号馈送给合成滤波器,合成滤波器产生重构的话音信号,如图6(b)所示。
合成滤波器通常使用全极点(all pole)的短期(short—term)线性滤波器,它的函数式如

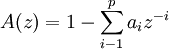
是预测误差滤波器,这个滤波器是按照这样的原则确定的:当原始话音段通过该滤波器时产生的残留信号的能量最小。滤波器的极点数的典型值等于10。这个滤波器企图去模拟由于声道作用而引入的话音相关性。
合成滤波器也可以包含音节滤波器,用来模拟话音中出现的长期预测。MPE和RPE编译码器一般不使用音节滤波器,对于CELP编译码器,音节滤波器则显得非常重要。
图6中的“误差加权”方框用来塑造误差信号谱的形状,目的是减少误差信号的主观响度。这样做的想法是,在话音信号能量很高的频段中,误差信号至少有部分能够被高能量的话音掩蔽掉。
AbS编译码器的性能与如何选择激励合成滤波器的波形u(n)有很大关系。从概念上说,可把每一种可能的波形输送给合成滤波器试试看,这种激励信号将会产生什么样的重构话音信号,它和原始话音信号之间的误差如何变化,然后选择产生最小加权误差的激励信号,并把它作为译码器中的合成滤波器的驱动信号。由于编码器是一个闭环系统,因此可以获得比较高的音质而数据率又比较低。但由于可能的激励信号的数目巨大,因此需要有某种方法来减少计算的复杂性而音质又不会牺牲太大。
MPE,RPE和CELP编译码器之间的差别在于所使用的激励信号的表示方法。在MPE中,对每帧话音所用的激励信号u(n)是固定数目的脉冲,在一帧中脉冲的位置和幅度必须由编码器来确定,这在理论上可以找到很好的值,但实际上不太可能,因为计算太复杂。因此在实际上就使用次佳方法,一般来说,每5ms使用4个脉冲,在数据率为10kb/s时可以获得好的重构话音。
像MPE那样,RPE编译码器使用固定间隔的脉冲,于是编码器就只需要确定第一个激励脉冲的位置和所有其他脉冲的幅度,所需要的脉冲位置信息也就可以减少,而脉冲的数目则比MPE使用的数目多。数据率在10kb/s左右时,每5ms可使用10个脉冲,比MPE多6个,产生比MPE音质高一些的重构话音。然而RPE仍然显得比较复杂,因此欧洲的GSM移动电话系统使用了一个带长期预测的简化了的RPE编译码器,数据率为13kb/s。
虽然MPE和RPE编译码器在10kb/s左右的数据率下可提供好的音质,但数据率低于10kb/s情况下提供的音质还不能接受,这是因为它们需要提供大量有关激励脉冲的位置和幅度信息。对要求音质好而数据率又低于10kb/s的编译码器,现在普遍使用的算法是1985年由Schroeder和AtM提出的CELP算法。与MPE和RPE的不同之处是,CELP使用的激励信号是量化矢量。激励信号由一个矢量量化大码簿的表项给出,还有一个增益项用来扩展它的功率。典型的码簿索引有10位,就是有1024个表项的码簿,增益用5位表示。因此激励信号的位数可以减少到15位,这与GSMRPE编译码器中使用的47位相比减少了32位。
CELP最初使用的码簿包含白高斯序列(white Gaussian sequences),这是因为作了这样的假设:长期预测和短期预测能够从话音信号中去除几乎所有的冗余度,产生随机的像噪声那样的残留信号。试验也显示出短期概率密度函数几乎是高斯状的。Schroeder和Atal发现,对长期和短期滤波器使用这样的码簿能够产生高质量的话音。然而,在合成—分析过程中要选择使用哪一个码簿表项,这就意味每一个激励序列都要传送给合成滤波器,看看重构话音与原始话音的近似程度。这也就是说原始CELP编译码器的计算量太大,难以实时执行。从1985年开始,在简化CELP的码簿结构方面做了大量的工作,使用数字信号处理芯片提高执行速度方面也取得了很大的进展,因此现在在低成本的单片DSP上实寸执行CELP算法相对容易了。在CELP基础上制定了好几个重要的话音编码标准,例如美国的“Department of Defence(DoD)4.8kb/scodec”标准和CCITT的“low—delay16kb/s codec”标准。
CELP编译码器在话音通信中取得了很大成功,话音的速率在4.8kb/s—16kb/s之间。近年来对运行在4.8kb/s以下的编译码器作了大量的研究工作,其目标是开发运行在2.4kb/s或者更低数据率下的编译码器。
通过对话音段进行分类,例如分成浊音帧、清音帧和过渡帧,CELP编译码器的结构可以进一步得到改善,不同类型的话音段使用专门设计的编码器进行编码。例如,对于浊音帧编码器不使用长期预测,而对于清音帧使用长期预测就显得特别重要。这种按话音类型设计的编译码器在数据率为2.4kb/s下呈现的音质已经得到认可。多带激励(multi—band excitation,MBE)编译码器把频域中的某些频段看成是浊音频段,其他频段看成是清音频段。它们传送每帧的音节周期、频谱的幅度和相位信息以及浊音/清音的判决。这种编译码器经过改造以后也显示出了它的潜力,在低数据率下可提供认可的音质。
在数据率为2.4kb/s-64kb/s的范围里,部分编码器的MOS分数大致如表1所示。
表1 部分编码器的MOS分
| 编码器 | MOS分 |
| 64kb/s脉冲编码调制(PCM) | 4.3 |
| 32kb/s自适应差分脉冲编码调制(ADPCM) | 4.1 |
| 16kb/s低时延码激励线性预测编码(LD-CELP) | 4.0 |
| 8kb/s码激励线性预测编码(CELP) | 3.7 |
| 3.8kb/s码激励线性预测编码(CELP) | 3.0 |
| 2.4kb/s线性预测编码(LPC) | 2.5 |
编译码器应用实例[4]
(1)编码器的应用
1.微控制器报警编码电路
图7所示为利用74LSl48编码器监视8个化学罐液面的报警编码电路。若8个化学罐中任何一个的液面超过预定高度时,其液面检测传感器便输出一个0电平到编码器的输入端。编码器输出3位二进制代码到微控制器。此时,微控制器仅需要3根输入线就可以监视8个独立的被测点。
这里用的是Intel 8051微控制器,它有4个输入/输出接口。我们使用其中的一个口输入被编码的报警代码,并且利用中断输入 接收报警信号
接收报警信号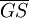 (是编码器输入信号有效的标志输出,只要有一个输入信号为有效的低电平,就变成低电平)。当Intel 8051在端接收到一个0时,就运行报警处理程序并做出相应的反应,完成报警。
(是编码器输入信号有效的标志输出,只要有一个输入信号为有效的低电平,就变成低电平)。当Intel 8051在端接收到一个0时,就运行报警处理程序并做出相应的反应,完成报警。
 | 
|
2.用编码器构成A/D转换器
图8为74LSl48构成的A/D转换器。这个电路主要由比较器、寄存器和编码器三部分组成。
输入信号UI(模拟电压),同时加到7个比较器(C1~C7)的反相端。基准电源UR经串联电阻分压为8级,量化单位q=UR/7。各基准电压分别加到比较器的同相端。若U1大于基准电压时,比较器Ci的输出电压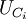 =0,否则=1。7个比较器的基准电压依次为
=0,否则=1。7个比较器的基准电压依次为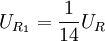 ,
,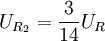 ,
, ,
,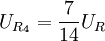 ,
,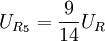 ,
,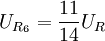 ,
,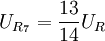
寄存器74LS373由8个D触发器构成。它的作用是寄存器缓冲比较器输出的信号,以避免因比较器响应速度不一致可能造成的逻辑错误。比较器的输出量保存一个时钟周期后,供编码使用。
编码器根据寄存器提供的信号进行编码,编码可以反码输出,也可以是原码输出。
当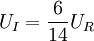 时,7个比较器输出为
时,7个比较器输出为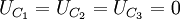 ,
,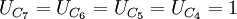 。这7个信号就是7个D触发器的输入信号。在时钟信号CP的上升沿时,7个D触发器的输出信号为Q7 = Q6 = Q5 = Q4 = 1,Q1 = Q2 = Q3 = 0。74LSl48译码器输出\overline{Y}_2\overline{Y}_1\overline{Y}_0=100,经非门输出原码CBA=011。这样A/D转换器就把输入的模拟信号U1变成了3位数字信号。
。这7个信号就是7个D触发器的输入信号。在时钟信号CP的上升沿时,7个D触发器的输出信号为Q7 = Q6 = Q5 = Q4 = 1,Q1 = Q2 = Q3 = 0。74LSl48译码器输出\overline{Y}_2\overline{Y}_1\overline{Y}_0=100,经非门输出原码CBA=011。这样A/D转换器就把输入的模拟信号U1变成了3位数字信号。
通常R选用1ktΩ,UR=5V,CP周期要大于手册中给出的比较器、寄存器、编码器、非门的平均传输延迟时间之和的2倍,而脉冲宽度只要大于寄存器的平均传输延迟时间即可。该转换器的转换精度取决于电阻分压网络的精度。这种转换器适合于高速度、低精度的情况应用。
(2)译码器的应用
译码器的应用范围很广,除了能驱动显示器外,还能实现存储系统的地址译码和指令译码,实现逻辑函数,作多路分配器,以及控制灯光等。下面介绍译码器的几种典型应用。
1.译码器作地址译码器
实现微机系统中存储器或输入/输出接口芯片的地址译码是译码器的一个典型用途。图9所示是四输入变量译码器用于半导体只读存储器地址译码的一个实例。图中,译码器的输出用来控制存储器的片选端\overline{CS},该输出信号取决于高位地址码A5~A8。A5~A8四位地址有16个输出信号。利用这些输出信号从16片存储器中选用一片,再由低位地址码A0~A4从被选片中选中一个存储单元,读出选中单元的内容。
2.用译码器构成数据分配器或时钟分配器
数据分配器也称为多路分配器,它可以按地址的要求将一路输入数据分配到多输出通道中某一个特定输出通道去。由于译码器可以兼作分配器使用,厂家并不单独生产分配器组件,而是将译码器改接成分配器。下面举例说明。
将带使能端的3—8线译码器74LSl38改作8路数据分配器的电路图,如图10(a)所示。译码器使能端作为分配器的数据输入端,译码器的输入端作为分配器的地址码输入端,译码器的输出端作为分配器的输出端。这样分配器就会根据所输入的地址码将输人数据分配到地址码所指定的输出通道。
例如,要将输入信号序列00100100分配到Yo通道输出,只要使地址码X2X1X0=000,输入信号从D端输入, 端即可得到和输入信号相同的信号序列。波形图如图10(b)所示。此时,其余输出端均为高电平。若要将输入信号分配到E输出端,只要将地址码变为001即可。以此类推,只要改变地址码,就可以把输入信号分配到任何一个输出端输出。
端即可得到和输入信号相同的信号序列。波形图如图10(b)所示。此时,其余输出端均为高电平。若要将输入信号分配到E输出端,只要将地址码变为001即可。以此类推,只要改变地址码,就可以把输入信号分配到任何一个输出端输出。
74LSl38作分配器时,按图10(a)接法可得到数据的原码输出。若将数据加到S1端,而 、
、 接地,则输出端得到数据的反码。
接地,则输出端得到数据的反码。
在图10(a)中,如果D输入的是时钟脉冲,则可将该时钟脉冲分配到~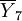 的某一个输出端,从而构成时钟脉冲分配器。
的某一个输出端,从而构成时钟脉冲分配器。
3.用译码器实现逻辑函数
由于全译码器在选通时,各输出函数为输入变量相应最小项之非,而任意逻辑函数总能表示成最小项之和的形式。因此,全译码器加一个与非门可实现逻辑函数。
【例1】用全译码器实现逻辑函数 。
。
解(1)全译码器的输出为输入变量的相应最小项之非,故先将逻辑函数式F写成最小项之反的形式。由摩根定理得

(2)F有三个变量,因而选用三变量译码器。
(3)变量A、B、C分别接三变量译码器的A2A1A0端,则有:

4.译码器用于灯光控制
图12是用于娱乐场所或电子玩具中的滚环追逐电路。该电路能够产生正反两方向循环、双向循环,并有常态和闪烁两种方式。
这个电路主要由定时器555、双16分频器74LS393及两片集电极开路的4—16线译码器74159构成。
图中用555构成的多谐振荡器,输出为一串矩形脉冲。它的充电路径为:+5V→R1→R2→C→地,输出为高电平(R1=4.7kΩ,R2=10kΩ)。放电路径为C→R2→TD(555内放电管)→地,输出为低电平。电容C上的充放电,使得555连续翻转,产生矩形脉冲。其脉冲宽度T1≈0.7(R1 + R2)C,脉冲休止期T2≈0.7R2C,周期T=T1+T2。调整C的值,可改变振荡器的输出频率。C_1=0.01μF,用作旁路电容。
555输出的脉冲信号,同时送到74LS393的两个计数脉冲CP端,使它们同步工作。Q3~Q0为16分频器的输出信号,它们以二进制方式记录cP的脉冲数。计满16个脉冲,又回到起始状态,重新开始计数。MR接地时,正常计数;MR接高电平时,Q3~Q0置0。
开关S1断开,555产生一串矩形脉冲。S2有闪烁和常态两种状态。S2置常态时,相当于MR接地。S3置正向,74159(1)的两个使能端接地,74159(1)工作;74159(2)的使能端悬空,74159(2)不工作。发光二极管按顺序0→1→2→…→15→0→…正向循环。S3置反向时,74159(1)不工作,74159(2)工作,发光二极管按顺序15→14→…0→15→…反向循环发光。S3置双向时,两片74159都工作,一路按正循环发光,一路按反循环发光。
S2置闪烁时,S3与555输出的矩形脉冲相连。当脉冲是低电平时,74159工作,点亮发光二极管;当脉冲是高电平时,74159处于禁止状态,发光二极管熄灭。在脉冲一个周期内,发光二极管一亮一灭地闪烁,发光顺序仍由S3决定。
开关S1闭合时,74159的输出信号维持不变,即发光二极管某一只或两只亮。
由于74159(1)的0线与74159(2)的15线,74159(1)的1线与74159(2)的14线……74159(1)的15线与74159(2)的0线接起来,使得同一时刻最多只有两只发光二极管同时点亮,因而只用一只限流电阻R3即可。R3=Vcc/2ID。ID为发光二极管允许流过的电流,应小于74159允许灌入的电流。
该电路的电压、电流不能驱动舞台上的彩灯。加驱动电路后,可以提高其输出电压和电流,驱动颜色艳丽的节日灯。
调节电容C可改变振荡器的振荡频率。若555输出的频率为60Hz左右,可用于控制节日彩灯、商店橱窗广告等场合;若555输出的频率为800~900Hz,则可用于博彩游戏中。
5.多路信号的分时传送
此项应用中将用到数据选择器和译码器,故先简要介绍一下数据选择器。
数据选择器的逻辑功能是按需要从n个(一般为4、8、16个)输入信号中选择一个信号输出,也可以用作并行码输入、串行码输出的转换,还可以用作n线至1线的多路转换器。
以双4选1数据选择器74LSl53的功能表如表2所示。其逻辑符号如图13(a)所示。该集成块包括两个相同的4选1数据选择器。从逻辑图可见(以下叙述中,省去区别A数据选择器和B数据选择器的下标)I0~I3是数据输入端,S1、S0是选择输入端,S1为高位;Z是原码输出; 是选通端,低电平有效。=1时,数据选择器不工作,=0时,输出函数表达式为
是选通端,低电平有效。=1时,数据选择器不工作,=0时,输出函数表达式为
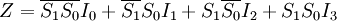
根据S1、S0的取值,决定I0~I3中的一个输出。
表2 74LSl53功能表
| 选择 | 数据输入 | 选通 | 输出 | ||||
| S1 | S0 | I0 | I1 | I2 | I3 | | Z |
| × | × | × | × | × | × | 1 | 0 |
| 0 | 0 | O | × | × | × | 0 | O |
| 0 | 0 | 1 | × | × | × | 0 | 1 |
| O | 1 | × | 0 | × | × | O | O |
| O | 1 | × | 1 | × | × | 0 | 1 |
| 1 | O | × | × | 0 | × | 0 | O |
| 1 | O | × | × | 1 | × | 0 | 1 |
| 1 | 1 | × | × | × | 0 | 0 | O |
| 1 | 1 | × | × | × | 1 | 0 | 1 |
是使能端。
图13(c)可用来分时传送4路信号。在发端,数据选择器作多路开关(MUX),分时将输入信号送人信息公共传输通道。在收端,译码器作数据分配器(DEMUX),分时将信息公共传输通道上的信号分配至各路。究竟传送哪一路信号,由公用地址A1A0决定。







{kind=link}